条件密度、贝叶斯法则与贝叶斯推断争议

条件密度、贝叶斯法则与贝叶斯推断争议

CreateAMind
发布于 2026-04-15 17:07:52
发布于 2026-04-15 17:07:52
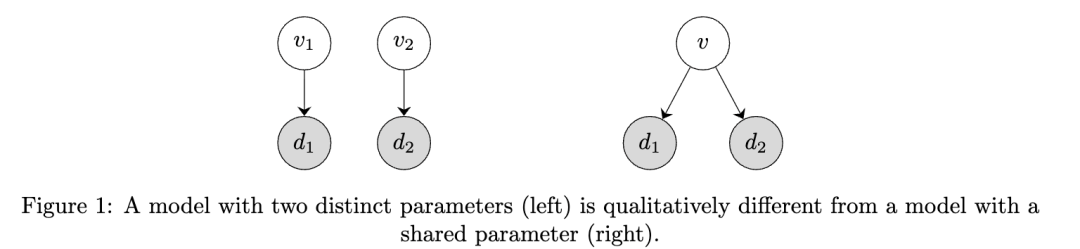
A note on conditional densities, Bayes’ rule, and recent criticisms of Bayesian inference
条件密度、贝叶斯法则与贝叶斯推断争议简析
https://arxiv.org/pdf/2603.27038


摘要
在进行贝叶斯推断时,我们经常需要处理条件概率密度。例如,后验函数就是在给定数据下参数的条件密度。有些人可能会担心条件密度定义不当,因为对于连续随机变量 Y,事件 {Y=y}的概率为零,这意味着公式 P(A∣B)=P(A∩B)/P(B)不适用。实际上,在处理条件密度时,我们从不直接以概率为零的事件 {Y=y}为条件;相反,我们首先以随机变量 Y为条件,然后代入观测值 y。本文的第一个目的就是阐述条件密度的这一要点。虽然我们力求使这一解释通俗易懂,但随后我们也会给出使其严格的测度论路径。近期的一篇预印本(Mosegaard 和 Curtis,2024)表达了这样的担忧:概率密度定义不当,因此贝叶斯定理无法使用,并且他们提供了据称能证明贝叶斯框架存在不一致性的例子。本文的第二个目的就是考察他们的主张。我们认为,他们文中的例子并未证明任何不一致性;我们发现其中存在数学错误,并且这些例子严重偏离了贝叶斯框架。
1 引言
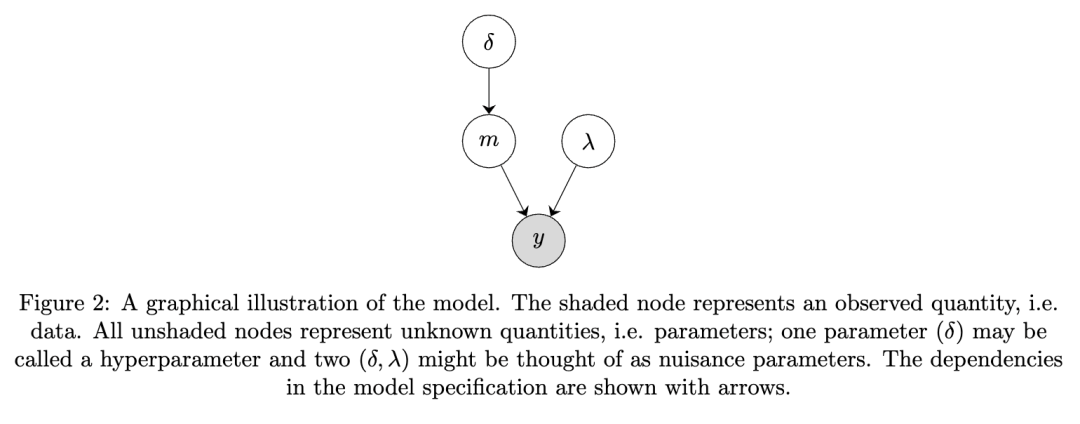
贝叶斯推断是一种从数据中学习的统计方法,它从对系统的先验信念出发,并利用观测数据,依据贝叶斯法则以有原则的方式更新这些信念。这使得我们能够将模型拟合到数据上,进而执行估计和预测等推断任务,同时确保获得不确定性量化。贝叶斯推断被广泛应用于科学和数据驱动的各个学科,包括解决物理科学中的反问题。
在近期的一篇预印本中,Mosegaard 和 Curtis (2024) 声称“证明了常用贝叶斯方法存在数学不一致性和逻辑上的非因果性”。初看之下,他们的工作(以下简称“MC”)似乎发现了贝叶斯范式中的根本性缺陷,尽管贝叶斯范式是一种成熟的统计推断方法。本文考察了 MC 的主张,发现贝叶斯推断并不存在 MC 似乎揭示的那种不一致性和所谓的“逻辑非因果性”。
MC 手稿的一个核心主张是:条件密度定义不当,并且贝叶斯定理在非离散空间中不起作用。¹ 这一主张是错误的。条件化的概念通过测度论得到了严格的定义。测度论发展于 20 世纪上半叶;它也形式化了概率和随机变量的概念。为了支持他们的主张,MC 引用了博雷尔-柯尔莫戈罗夫悖论(也称为博雷尔悖论;Borel, 1965; Kolmogorov, 1956)。一旦我们掌握了恰当的条件分布理论,博雷尔-柯尔莫戈罗夫悖论就基本不相关了。该悖论涉及以概率为零的事件为条件,而条件分布理论涉及的则是以随机变量为条件。
在第 2 节中,我们将解释贝叶斯定理在非离散空间中确实有效。我们将进行阐述,说明什么是条件密度、条件密度存在的条件(即联合密度必须存在),以及它在多大程度上是唯一确定的。作为其中的一部分,我们将在第 2.4.1 节详细阐述为什么博雷尔-柯尔莫戈罗夫悖论在此不构成问题。
我们相信第 2 节可能会引起更广泛的读者群体的兴趣,因此我们力求这一节能够独立于本文其余部分而被理解。在实际进行贝叶斯推断时,我们并不需要理解测度论才能使用条件密度,相应地,我们在第 2.6 节之前一直避免涉及测度论,在那里我们概述了相关测度论的路线图并给出了教科书参考文献,除非沿途需要做一些读者可能希望忽略的技术性澄清。
除了对条件密度是否定义良好的理论关切之外,MC 还提供了许多例子,详细列于其附录中,每个例子似乎都展示了由贝叶斯推断引起的不一致性。在第 3 节和第 4 节中,我们将讨论这些例子。我们的发现是:其附录 A 中的例子从根本上偏离了贝叶斯框架,使用了无效的启发式论证来寻找条件分布;附录 B–D 中的例子在试图重新参数化数据空间时都犯了同样的关键错误;附录 F 中的例子没有正确执行贝叶斯推断;附录 G 中的例子并未证明任何真正的不一致性。第 3 节有一个松散的统一主题,即选择适当的模型是建模者的职责。第 4 节传达的信息是,贝叶斯推断对数据空间的重新参数化保持不变。
最后,在第 5 节中,我们将提及使用贝叶斯推断的一些真正的优点和缺点。与第 2 节一样,这一节也可以独立于文章其余部分来阅读。
2 条件密度与贝叶斯法则
2.1 什么是贝叶斯法则?
在贝叶斯框架中,参数 θ 和数据 Y 都被建模为随机的。它们的联合分布由两部分指定:参数上的概率分布 π(θ),称为先验分布;以及给定参数下数据的条件分布 f(y|θ),称为似然函数。然后,给定数据下参数的条件分布可以使用以下公式获得:²

这被称为后验分布。
“贝叶斯法则”这一术语指代两个概念:
- 一种方法论原则:根据新观测值更新我们先验信念的正确方法是基于观测值进行条件化;
- 一个数学公式,例如 (1),描述条件化如何运作。
我们将使用“贝叶斯定理”来指代后者,这也是我们讨论的主题。在一些文献中,单个字母 pp被用来表示所有概率分布,贝叶斯定理可能被写作

个重要的要点是:方程 (1) 中涉及的每个函数既可以表示概率质量,也可以表示概率密度,具体取决于它们的(第一个)参数是离散的还是连续的。

本节中的阐述旨在为实践中使用条件密度和贝叶斯定理的方式提供理论依据。我们希望这能向读者保证,他们可以继续使用贝叶斯定理,而无需担心 MC 提出的问题。
2.2 以事件为条件
让我们从以事件为条件的概念开始。只要事件的概率为正,以该事件为条件就是定义良好的。
设 B为一个概率为正的事件,即 P(B)>0。如果 AA是另一个事件,那么给定 BB下 AA的条件概率就是两个事件同时发生的概率除以 BB的概率:
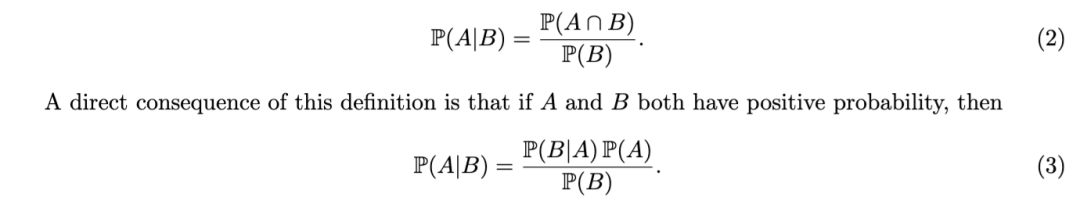

2.3 离散随机变量的条件化
如果 XX和 YY都是离散随机变量,那么给定 YY下 XX的条件分布由下式给出:

2.4 连续随机变量的条件化


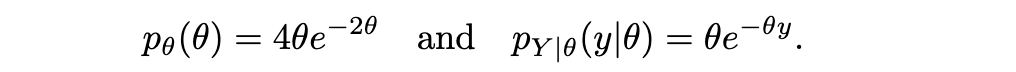

2.4.1 为什么博雷尔-柯尔莫戈罗夫悖论在此不构成问题?
博雷尔-柯尔莫戈罗夫悖论只在人们试图(在不参考随机变量的情况下)以零概率事件为条件时才会出现。

以下两点强调了以随机变量为条件与以零概率事件为条件之间的区别。
条件密度的定义是有充分依据的。
值得注意的是,在连续情形下,我们可以通过要求以连续随机变量为条件必须与以正概率事件为条件相一致,来为定义 (4) 提供动机:
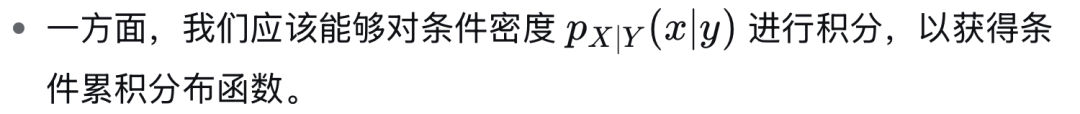
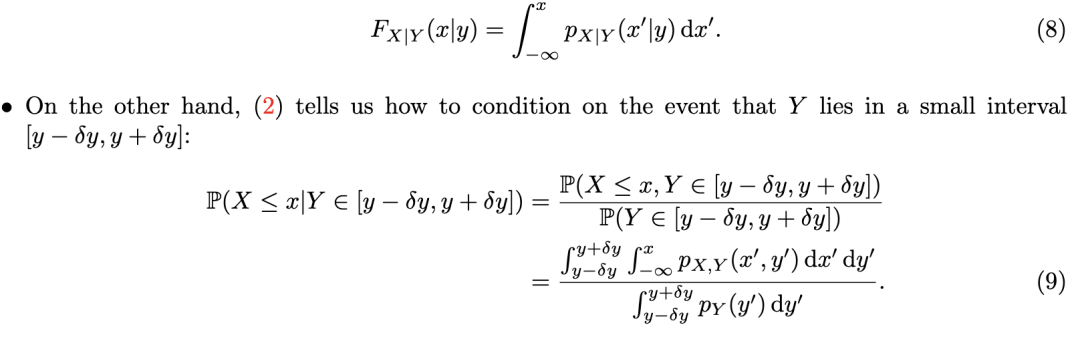


2.4.2 条件密度是唯一确定的吗?
当条件密度存在时,它在本质上是唯一确定的。
需要注意的是,不同的密度函数 f(z)可以定义 ZZ上的同一个分布。例如,标准正态分布的密度函数为:







总之,我们可以在广泛的情况下安全地使用条件密度和贝叶斯定理。通过对所涉及符号进行适当的解释,贝叶斯定理保持相同的公式 (5, 6)。
如果联合密度不存在呢?当联合密度不存在时,条件密度也可能不存在。没有条件密度,我们的贝叶斯定理版本就无法作为帮助我们数值计算后验的工具。尽管如此,条件概率仍然存在,这引出了条件分布的定义。关键在于,即使联合密度不存在(例如,当涉及非参数过程时),后验分布这样的对象仍然存在。
2.6 测度论
到目前为止,我们的论述必然是非正式的。为了弥补这一点,我们现在将勾勒相关理论的路线图,但读者可以跳过本节直接阅读后面的任何部分。我们将主要思想放在一系列方框中,并在这些方框外提供一些指引。该理论发展于 20 世纪上半叶,它驳斥了 MC 关于“条件密度的概念是不可接受的”这一主张。
遵循 Kallenberg (2010, 第 6 章),我们将从条件期望和条件概率开始,定义以 σ-代数为条件意味着什么,然后定义以随机元素为条件意味着什么。接着,我们将定义条件分布。最后,我们将把条件密度视为表示条件分布的一种方式,并证明这种表示与熟悉的公式 (4) 是一致的。
为了建立一般的条件化理论,第一步是定义以 σ-代数为条件意味着什么。下面的方框定义了给定 σ-代数下的条件期望。给定 G下 X的条件期望可以有多个版本,但这些版本只能以微不足道的方式不同,这一点由命题 1 精确阐述。



我们现在已经阐述了条件概率理论中的核心对象。进一步的理论证明,这些对象的行为符合我们的预期,我们可以执行迭代条件化(参见 Kallenberg, 2010, 第 6 章),并且我们还可以考虑 σ-有限测度而不仅仅是概率测度(参见 Kallenberg, 2021, 第 3 章)。最后这一点与贝叶斯推断相关,因为有时我们会使用非正常先验(Chang 和 Pollard, 1997)。
现在(偏离 Kallenberg 2010 的叙述顺序),我们转向分布具有密度的特殊情形。一般而言,概率密度是概率分布关于某个控制测度(可称为基测度或参考测度)的拉东-尼科迪姆导数。通常参考测度隐式地是勒贝格测度,但一般情况下不一定是。知道了概率密度(连同参考测度)就完全确定了概率分布。拉东-尼科迪姆定理确保了概率密度是定义良好的:



2.6.1 文献注记
关于条件密度,相关文献包括 Kingman 和 Taylor (1966, 第 14 章)、Hoel 等人 (1971, 第 6 章)、Ash (1972, 第 6 章)。这些文献都讨论了关于另一个连续随机变量的一个连续随机变量的条件密度。前两个文献还提到了关于条件密度的贝叶斯定理版本,而后两个文献指出条件密度可以扩展到连续随机向量。然而,我们要没有找到一本教材明确指出条件密度可以扩展到生活在更一般空间中的随机元素。既然在实践中我们可能需要在这种情况下使用贝叶斯定理,我们选择展示带有随机元素的更一般情况。
在概率论教材中,博雷尔悖论(Borel paradox)通常被作为一个警告提出,即我们不应尝试以零概率事件为条件。相关的讨论见 Pollard (2001, 第 5 章)、Chang 和 Pollard (1997),以及 Bungert 和 Wacker (2022)。这些文献进一步解释了为什么 MC 所表达的担忧是站不住脚的。MC 声称通过 Mosegaard 和 Tarantola (2002) 中描述的结构可以避免 Borel–Kolmogorov 悖论;然而,他们描述的只是一个非正式的想法,从未被严谨化,且该想法是几何性质的而非概率性质的。Bungert 和 Wacker (2022) 也通过几何视角探讨 Borel–Kolmogorov 悖论;他们的文本基于 Hausdorff 测度的严谨理论 (Billingsley, 1986, 第 19 章)。然而,这些几何思想并不适用于统计推断;在概率论中,事件应当具有其独立的意义,而不需要将其定位在欧几里得空间内部。
转向测度论基础,我们主要遵循 Kallenberg (2010, 第 6 章)。虽然这本书更为简练,但 Billingsley (1986, 第 33–34 章) 更易读。虽然关于条件概率、条件期望和条件分布的现有理论早已确立,但呈现该主题仍有不同的方式:

3 建模者需要指定适当的模型
在本节中,我们将讨论 MC 在其附录 A、F 和 G 中提供的例子。本节松散的统一主题是:MC 报告的问题可以通过建立适当的模型来解决。在接下来的小节中,我们将讨论这些例子,解释它们未能证明贝叶斯推断中存在真正的不一致性,并描述 MC 本可以采用的以适当方式进行贝叶斯推断的建模方法。
3.1 MC 的附录 G 表明不同模型可以产生不同结果
显然,如果不同的模型不等价,它们可以产生不同的结果。
在其附录 G 中,MC 证明了不同的模型(通过固定不同的 σ值)可以产生不同的结果。虽然这是事实,但我们认为这不应令人惊讶,也不应被视为一种不一致性。在这种情况下,如果建模者不知道其模型中 σ的适当值是多少,他们可以将 σ视为一个参数,并为其分配一个反映合理取值范围的先验分布。
3.2 MC 的“简单断层扫描示例”(其附录 A)是无效的:不允许以零概率事件为条件

在实践中,可能我们观测到的数据提供了关于两个速度是否相似的证据;那么我们可以遵循通常的贝叶斯框架,对数据进行概率建模。正如第 2 节所讨论的,当数据被视为随机时,我们被允许以数据为条件。


3.3 MC 关于非因果性的例子(其附录 F)是无效的:他们的模型设置不正确
MC 在附录 F 中给出的两个用于展示“非因果性”的例子是无效的。
他们得出的结论是:“[两个参数]的计算得到的先验分布随正演关系而变化”;但实际上,他们呈现的是(尝试计算)后验分布,而不是先验分布。因此,他们的结论本应是:这些参数的计算得到的后验分布随正演关系而变化,而这自然是意料之中的。

我们有以下先验分布:
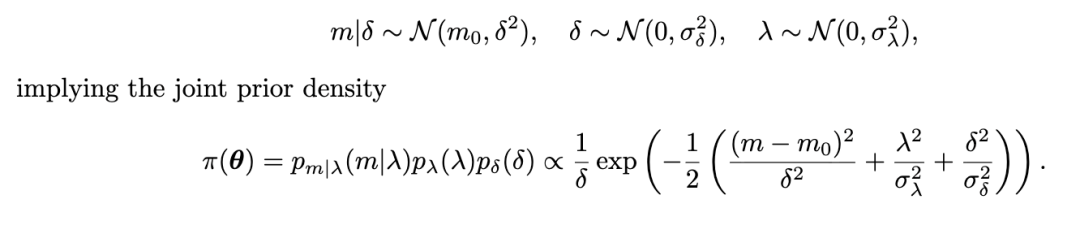


4 贝叶斯推断对数据空间的重新参数化保持不变
MC 的其余例子都基于数据空间中的变量变换。在每个例子中,他们使用数据空间的两种不同参数化进行计算,并得到了不一致的结果。我们发现,这种矛盾源于他们对变量变换的错误处理。事实上,贝叶斯推断并不依赖于数据空间的重新参数化。我们首先说明为什么如此;然后阐明他们的错误。

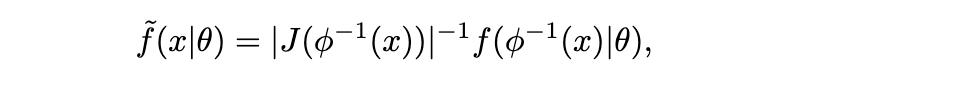

考虑到 X=ϕ(Y),这与我们在方程 (1) 中已知的结果完全一致。因此,对数据空间进行重新参数化不会导致后验出现任何不一致性。
因此,当我们使用这个后验进行 MAP 估计或贝叶斯因子时,也不会有任何不一致;同样,在经验贝叶斯中,当我们使用边缘似然来获得超参数的点估计时,也不会有任何不一致。
与 MC 的论点正交的是,对经验贝叶斯存在一种真正的批评:它两次使用了数据:一次用于估计超参数,另一次用于在固定超参数的模型下获得后验。这意味着超参数的不确定性被忽略了,并且我们正在对数据过度拟合。然而,如果拟合一个具有超参数不确定性的完整层次模型在计算上难以承受,经验贝叶斯仍然可能有用。此外,当数据充足时,超参数通常也几乎没有不确定性。
4.1 MC 涉及 MAP 估计、经验贝叶斯和贝叶斯因子的例子(其附录 B–D)是无效的:重新参数化执行错误
我们所说的与 MC 在其涉及 MAP 估计、经验贝叶斯和贝叶斯因子的例子(分别详述于其附录 B、C 和 D)中所声称的不一致性是不相容的。那么,他们错在哪里呢?



5 使用贝叶斯推断的一些真正优点和缺点是什么?
采用贝叶斯方法的一个障碍是它需要一定水平的统计学素养。我们指出,有许多非常易于理解的贝叶斯推断教科书可能有助于克服这一障碍,包括 Gelman 等 (2013)、Lambert (2018) 和 McElreath (2020)。
除此之外,在决定是否在统计问题中使用贝叶斯推断时,有许多因素需要考虑。在这个独立的章节中,我们希望将注意力引向一些合理的问题。
哲学解释。作为个体,我们每个人对周围世界都存在着不确定性。这些不确定性很重要,因为它们影响着我们如何做决策。当我们在世界中观察和学习信息时,我们会更新自己的信念。贝叶斯框架形式化了这种直觉。这是选择贝叶斯方法的一个令人信服的哲学理由。另一方面,支持频率论统计的人可能会争辩说,参数应被视为世界中固定但未知的特征,而不是将参数视为随机实体。此外,人们可能会反对贝叶斯推断的主观性,因为结果依赖于对先验的主观选择。
不确定性量化。贝叶斯范式的一个关键优势在于它如何提供不确定性量化。贝叶斯推断能够回答诸如“根据这些数据,我们在多大程度上相信假设 A 成立?”这样的问题,并能做出诸如“在我们的模型下,真实参数落在区域 R 内的概率为 95%”这样的陈述。与频率论的对应表述(“如果假设 A 为真,观察到比这更极端的数据的概率是多少?”以及“用于构建区域 R 的程序具有 95% 的覆盖概率”)相比,这些可以说更自然、更易于解释。贝叶斯框架还使得纳入未观测的潜变量、缺失数据和可学习的超参数变得简单直接;这些都可以通过额外的参数进行建模,并且这些参数的不确定性会自然地通过模型传播。此外,即使在数据非常稀少并因此导致极高不确定性的情况下,贝叶斯推断也能提供有原则的不确定性量化。尽管如此,我们应当牢记,如果一开始模型就被错误指定,贝叶斯推断无法找到真实参数;得到的后验分布可能会自信地指向错误的参数值。结果可能仍然有用,因为后验质量会集中到那些能给出最佳数据拟合的参数上。(这就是为什么我们在第 3 节中强调建模者应该注意选择适当的模型。当然,这个问题并非贝叶斯推断所独有。)
先验指定。在某些情况下,指定先验的能力可能很有吸引力,因为它允许我们对来自领域知识或先前实验的先验信息进行编码。信息性先验还可以提供自然的正则化来源,有利于模型的简洁性,并防止更复杂模型中的过拟合。然而,在实践中,指定一个合适的先验可能非常具有挑战性,特别是在先验信息很少的情况下,这时优势变成了劣势。通过贝叶斯法则,不同的先验选择会导致不同的后验;这个问题被称为先验敏感性。在使用贝叶斯因子进行模型比较时,先验敏感性可能特别严重,而基于后验预测分布(包括用于模型比较的 PSIS-LOO)的预测方法往往更稳健。有趣的是,对于一大类参数模型,随着数据量趋近无穷大,贝叶斯方法与频率论方法趋于一致,先验的影响会逐渐消失。
计算困难。到目前为止,我们还没有讨论计算方面的考虑。对于像指数等待时间例子那样的简单模型,后验分布可以解析地推导出来。然而,对于更复杂的模型,解析解通常是不可得的。在这种情况下,直接计算后验密度需要计算贝叶斯定理中的归一化常数。这个归一化常数就是边缘似然 pY(y)=∫π(θ)f(y∣θ)dθ,它涉及对可能高维的参数空间进行积分;这通常在计算上是棘手的。一个解决方案是使用马尔可夫链蒙特卡罗(MCMC)算法从后验分布中抽取参数样本。在过去的几十年里,MCMC 和软件实现的发展使得可行的贝叶斯推断成为可能。即便如此,MCMC 方法仍然可能是计算密集型的。替代方法可以减轻计算负担,但代价是只能逼近后验分布。如果后验函数的形状存在病态结构,MCMC 也可能难以有效地探索参数空间。
6 结论
我们在此陈述本文的几个关键结论。
- 读者应放心,Mosegaard 和 Curtis (2024) 的主张是无效的。贝叶斯推断对于一系列物理反问题仍然是一种有效且原则性强的分析方法。
- MC 论证中的一个重要缺陷是试图以零概率事件为条件。我们强调,这是不可行的,可行的做法是以随机变量为条件。
- 概率密度不仅可以为连续随机变量定义,也可以为更一般的随机元素定义。在实践中,我们确实使用这些更一般的密度:我们的先验函数、后验函数和似然函数都是在适当空间上的概率密度。
- 当联合密度存在时,条件密度也存在。条件密度的概念有坚实的理论支持。
- 虽然贝叶斯推断是一种灵活且提供原则性不确定性量化的方法,但它确实也面临挑战,包括先验敏感性和计算困难。
原文链接:https://arxiv.org/pdf/2603.27038
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号