结构化策略初始化加速大规模离散动作空间离线强化学习

结构化策略初始化加速大规模离散动作空间离线强化学习

CreateAMind
发布于 2026-04-30 17:12:06
发布于 2026-04-30 17:12:06
IMPROVING AND ACCELERATING OFFLINE RL INLARGE DISCRETE ACTION SPACES WITH STRUCTUREDPOLICY INITIALIZATION
结构化策略初始化加速大规模离散动作空间离线强化学习
https://arxiv.org/pdf/2601.04441


摘要
在离散组合动作空间中进行强化学习,需搜索指数级数量的联合动作,以同时选择多个能形成协调组合的子动作。现有方法要么通过假设子动作相互独立来简化策略学习,但这常导致不协调或无效的动作;要么尝试联合学习动作结构与控制,但这往往缓慢且不稳定。我们提出了结构化策略初始化(SPIN),这是一种两阶段框架:首先预训练动作结构模型(ASM)以捕捉有效动作的流形,随后冻结该表示,并训练轻量级策略头用于控制。在具有挑战性的离散DM Control基准测试中,SPIN较当前最优方法将平均回报最高提升了39%,同时将收敛时间最多缩短至原来的1/12.8(即提速12.8倍)。
1 引言
许多现实世界的问题需要在高维离散动作空间中进行决策,包括医疗保健(Liu et al., 2020)、机器人装配(Driess et al., 2020)、推荐系统(Zhao et al., 2018)以及网约车(Lin et al., 2018)等领域的应用。在这些领域中,在线探索(online exploration)可能代价高昂或不安全,这使得离线强化学习(RL)(Lange et al., 2012; Levine et al., 2020)成为一个极具吸引力的框架。然而,标准的离线RL方法(Fujimoto et al., 2019; Agarwal et al., 2020; Fu et al., 2020; Kumar et al., 2020; Kostrikov et al., 2021)并非专为大型离散动作空间设计,因为它们需要在整个离散动作集上最大化Q函数或对策略进行参数化——随着动作空间随
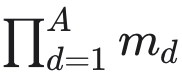
呈指数级扩展,这些操作将变得难以处理(intractable),其中 A 是子动作维度的数量,
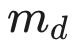
是每个维度的可选数量。
在这些复杂场景中进行学习需要解决两个相关问题:(i)在指数级数量的联合动作中进行搜索,以及(ii)确保所选子动作形成协调一致的组合。针对此类组合空间设计的方法传统上通过施加强结构先验(例如假设子动作间条件独立)来简化策略学习(Tang et al., 2022; Beeson et al., 2024)。然而,这牺牲了表示能力,致使模型无法捕捉有效控制所需的交互作用。其他方法尝试同时学习动作表示与优化策略(Zhang et al., 2018; Landers et al., 2024; 2025),但这种目标耦合往往导致学习过程缓慢且不稳定。
我们提出了结构化策略初始化(Structured Policy Initialization, SPIN),这是一个将表示学习与控制解耦的两阶段框架。在第一阶段,通过自监督训练一个动作结构模型(Action Structure Model, ASM),以学习一个表示函数;该函数以状态 ss 为条件,在子动作上诱导产生一个特征空间,其中结构上连贯的联合动作集中在一个低维流形上。随后,在第二阶段冻结该动作空间表示,此时控制问题简化为针对下游强化学习(RL)任务,在动作流形上学习轻量级策略头。通过先学习结构再学习策略,SPIN 允许智能体利用底层的动作几何结构,而不是在原始组合空间中进行搜索。这带来了更快的训练速度和提升的策略性能(图 1)。在数据集大小和质量、动作维度以及动作基数各异的多样化基准测试中,SPIN 相比当前最先进方法(state of the art)将平均回报最高提升了 39%,并将达到最先进性能所需的训练时间最多缩短了 12.8 倍。
我们的贡献如下:
- 我们将离散结构化动作空间中的离线强化学习(RL)重新构建为一个表示问题,将动作结构学习与控制分离开来。
- 我们提出了 SPIN,这是一个两阶段框架,通过预训练并冻结动作空间表示来加速并改进策略学习。
- 我们展示了 SPIN 在具有挑战性的基准测试中实现了最先进(SOTA)的性能,在显著更快的同时优于现有方法。
- 我们分析了学习到的表示,以证明在离散组合动作空间中进行有效策略学习时,捕捉动作结构至关重要。
2 相关工作
大离散动作空间中的强化学习。 针对路由(Nazari et al., 2018; Delarue et al., 2020)和资源分配(Chen et al., 2024)等领域的组合动作空间,已开发出多种强化学习方法,但这些方法通常依赖于特定任务的知识。研究也引入了通用方法(Dulac-Arnold et al., 2015; Tavakoli et al., 2018; Farquhar et al., 2020; Van de Wiele et al., 2020; Zhao et al., 2023),但它们通常面向在线学习设计,难以直接适应离线数据集的约束条件。在离线强化学习中,现有方法通常对策略或 Q 函数进行分解(factorize)(Tang et al., 2022; Beeson et al., 2024)。然而,这种分解强制子动作之间满足条件独立性,从而限制了模型的表征能力,并在子动作存在强依赖关系时失效。其他方法则显式地捕捉依赖关系——例如 BraVE(Landers et al., 2024)对跨维度交互进行建模,但其计算复杂度随动作规模扩大而急剧增加(扩展性差);而自回归策略(Zhang et al., 2018)则强加了固定的动作顺序,破坏了排列不变性。最近,SAINT(Landers et al., 2025)引入了一种基于 Transformer 的策略,通过自注意力机制捕捉子动作间的依赖关系,但其联合学习动作结构与控制策略的方式,导致了训练缓慢且不稳定。另一条相关研究线致力于为大规模但平坦(flat)的动作空间学习表征。其中最相关的是 MERLION(Gu et al., 2022),它为离线强化学习学习了一种基于伪度量(pseudometric)的动作表征。然而,MERLION 的策略执行需要在每个时间步对整个枚举动作集进行最近邻搜索,这在我们所考虑的组合场景中计算上是不可行的。此外,其架构将动作视为原子实体,并未对其底层的组合结构进行建模。相比之下,SPIN 专为这种组合设定设计,其结构化策略逐维度生成联合动作,而非枚举完整的组合动作集。
强化学习中的自监督预训练。 强化学习中的自监督预训练已呈现多种形式,包括作为表征塑造(representation shaping)的辅助目标(Jaderberg et al., 2016; Shelhamer et al., 2016)、对比与预测编码器(Laskin et al., 2020; Schwarzer et al., 2021; Stooke et al., 2021; Liu & Abbeel, 2021b;a)以及世界模型建模(Ha & Schmidhuber, 2018)。其他研究探索了掩码决策建模或轨迹建模(Cai et al., 2023; Liu et al., 2022; Wu et al., 2023; Sun et al., 2023)。大规模行为预训练已催生出通用策略(generalist policies)与视觉-语言-动作模型(VLA models)(Brohan et al., 2022; Zitkovich et al., 2023; O’Neill et al., 2024; Kim et al., 2024; Team et al., 2024; Tirinzoni et al., 2025),并配套了预训练后的快速适应方法(Sikchi et al., 2025)。这些方法大多以状态或轨迹为中心,且通常预设了在线交互或多任务微调的场景。相比之下,SPIN 预训练了一个能够捕捉动作组合规律的动作结构模型(ASM),从而在无需任何在线交互的情况下,为组合动作空间中的策略学习提供结构化初始化。
3 预备知识

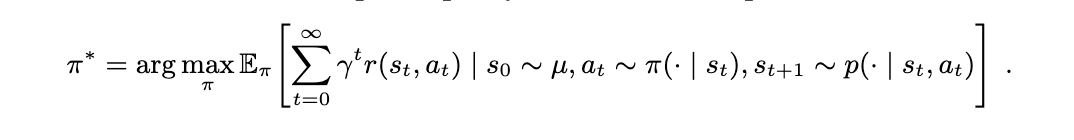

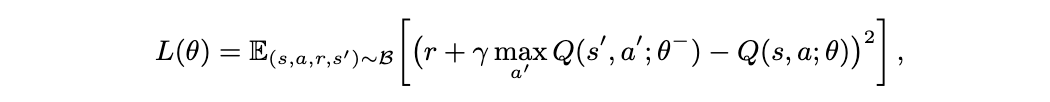

4 结构化策略初始化 (SPIN)
结构化策略初始化(Structured Policy INitialization, SPIN)是一个针对结构化动作空间中离线强化学习的两阶段框架,它显式地将表示学习与控制解耦。在第一阶段,通过自监督训练一个动作结构模型(Action Structure Model, ASM),以学习一个表示函数;该函数以状态 s 为条件,在子动作上诱导产生一个特征空间,其中结构上连贯的联合动作集中在一个低维流形上。在第二阶段,该表示被冻结,策略学习简化为在诱导出的动作流形上训练轻量级头(heads),以用于下游的强化学习任务。
4.1 动作结构建模 (ASM)

ASM 的预训练过程总结在算法 1 中。我们在附录 C 中通过实证验证了这一目标,展示了它优于强大的生成式和判别式替代方案。

4.2 基于冻结表示的策略学习
在第二阶段,SPIN 在 ASM 提供的冻结表示上执行策略学习。策略网络 πθ 仅更新轻量级组件,如查询向量和输出头,而 ASM 保持固定。这种分离保留了学习到的动作结构,并保持策略优化的可处理性(tractability)。

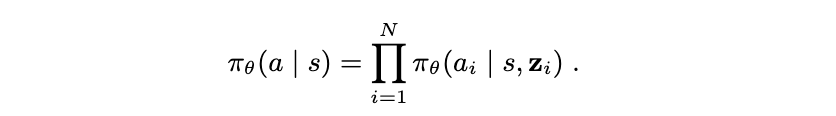



5 实验评估

为了隔离架构选择的影响,所有方法均使用 IQL(Kostrikov et al., 2021)目标进行训练。为了评估鲁棒性,我们在附录 D 中也报告了使用替代目标(包括 AWAC (Nair et al., 2020) 和 BCQ (Fujimoto et al., 2019))的结果。为了验证 SPIN 在运动(locomotion)之外的泛化能力,我们在 Maze(Beeson et al., 2024)上评估了其性能,结果见附录 E。为了证明 SPIN 的有效性归因于其以动作为中心(action-centric)的预训练目标,而非仅仅源于预训练本身,我们在附录 F 中将其性能与一种以轨迹为中心(trajectory-centric)的预训练方法进行了比较。在所有这些设置中,SPIN 在性能和效率上均一致优于基线方法。
所有实验均使用 Python 3.9 和 PyTorch 2.6 在单块 NVIDIA A40 GPU 上运行。报告的结果是五个随机种子的平均值,±± 值表示跨种子的一个标准差。
5.1 渐近性能与训练效率
表 1 报告了跨环境和数据集质量的最终性能与训练效率(完整的学习曲线见附录 A)。SPIN 取得了比所有基线方法 consistently 更高的回报,并且比所有基线方法用更少的挂钟时间(wall-clock time)达到了目标性能。
SPIN 达到了最高的总体平均回报 594.1,超过了次优基线 SAINT 的 572.1。这种提升在整个基准测试套件中是系统性的,而非集中在个别环境中。这种优势在异构的 medium-expert(中等 - 专家)和 random-medium-expert(随机 - 中等 - 专家)数据集中最为显著,它们代表了最现实且具有挑战性的基准设置。在 random-medium-expert 数据集上,SPIN 实现了 499.2 的平均回报,比次优方法 SAINT(438.9)提升了超过 13%。
我们还测量了每种方法达到 F-IQL 渐近性能 95% 所需的挂钟时间(以分钟为单位报告)。F-IQL 是结构化动作空间中广泛采用的最先进(state-of-the-art)基线(Tang et al., 2022; Beeson et al., 2024; Landers et al., 2024),在各环境中均提供了可处理性(tractability)和稳定的收敛性。使用 F-IQL 作为目标使得收敛到不同回报水平的方法之间能够进行公平比较,避免了因在次优性能处提前终止而产生的误导性优势。我们采用 95% 的阈值而不是 100%,是因为有些方法永远无法达到 F-IQL 的渐近性能。直接处理这些情况——无论是通过排除运行次数还是报告完整运行时间——都会使结果产生偏差,而 95% 的标准提供了一致且可比的度量。
每个环境的到达目标时间(time-to-target)完整结果报告在附录 B 中。总计,SPIN 在 223.3 分钟内达到目标性能,大约比 F-IQL 本身快 2.5 倍,比 SAINT 快 3.8 倍。这种加速在 medium-expert 数据集中尤为明显,SPIN 仅需 62 分钟的训练时间,而所有其他方法则需要超过 250 分钟。SPIN 的所有运行时间均包含 ASM 预训练阶段的全过程。
这些发现表明,在专用的预训练阶段显式地对动作结构进行建模,使得表示层能够捕捉连贯动作的流形。在策略学习期间冻结该表示保留了这种结构,使得轻量级头(heads)能够高效地适应下游任务。与 Factored(因子化)和 Autoregressive(自回归)方法相比(它们要么丢弃跨维度依赖关系,要么对其施加强制性的刚性结构),SPIN 在保留灵活性的同时没有牺牲可处理性。与试图联合学习动作结构和控制的 SAINT 不同,SPIN 的解耦设计实现了更高的渐近性能和更快的收敛速度。
5.2 对动作基数的鲁棒性

结果总结在表 2 中。SPIN 在每个基数下都取得了最高的平均回报,且相对于基线的差距随着动作空间的增大而增加。在三个区间时,SPIN 略微优于最强的基线 SAINT。在三十个区间时,SPIN 达到了 703.9 的平均回报,相比之下 SAINT 为 562.5,提升幅度超过 25%。AR-IQL 表现出不稳定的性能,从三个区间时的 526.5 下降到十个区间时的 457.4,而 F-IQL 则未显示出从增加粒度中获益,停留在 480 左右。
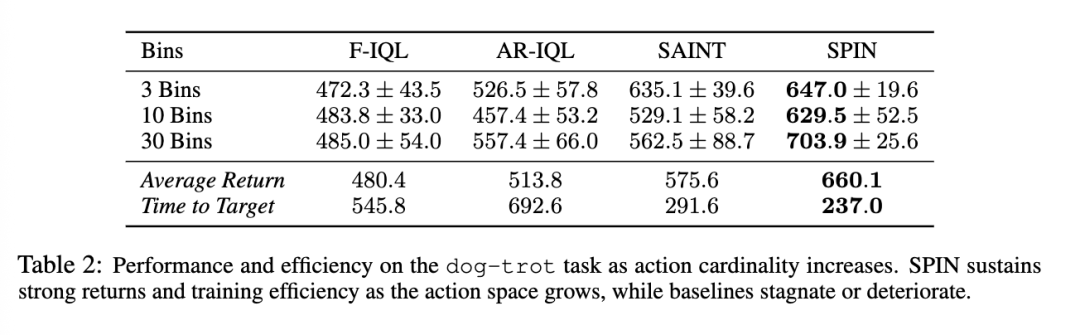
训练效率遵循相同的趋势。即使在最大的动作空间中,SPIN 始终需要更少的挂钟时间(wall-clock time)来达到目标性能(完整运行时间结果见附录 B)。这些结果表明,随着组合复杂性的增长,将结构学习与控制分离开来日益有益,因为智能体可以在学习到的低维流形上行动,而端到端(end-to-end)的方法仍然受制于原始联合空间的规模。
6 SPIN 有效性的底层机制
第 5 节的实验表明,SPIN 在学习速度和最终性能上均优于现有方法。我们现在考察这些提升背后的机制。
6.1 表示质量对策略性能的影响
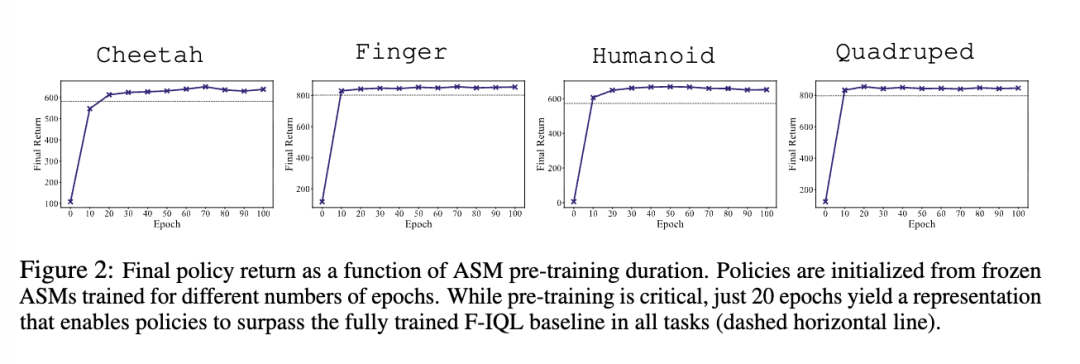
为了评估 ASM 预训练的贡献,我们在 medium-expert(中等 - 专家)数据集上将 ASM 表示训练了 10–100 个 epoch。随后,将每个表示函数冻结,并用于初始化一个新的策略,该策略随后在控制任务上训练至收敛。
图 2 显示,下游回报(return)通常随着更多的 ASM 预训练而提升,其中前 20 个 epoch 的增益最为陡峭。在 20 个 epoch 之后,策略在所有任务上均超过了完全收敛的 F-IQL 参考值。由未训练的 ASM(Epoch 0)初始化的策略表现不佳。这些结果表明,最终策略性能在很大程度上取决于预训练动作表示的质量;一旦学习到了连贯的表示,控制优化就会变得 substantially 更容易。
6.2 量化表示质量
图 2 中随机初始化(epoch 0)与预训练智能体之间的巨大差距,可能是由于预训练仅提供了方便的初始化而未编码结构,也可能是由于预训练学习到了能够赋能下游性能的表示。我们通过测试 ASM 表示是否使用线性探针(linear probe)捕捉联合动作依赖关系来直接评估这一点,线性探针是自监督表示的标准诊断工具(Chen et al., 2020; He et al., 2020)。
在本实验中,ASM 表示被冻结——无论是预训练了 100 个 epoch 还是随机初始化——并在其嵌入上训练一个轻量级线性分类器,以根据状态预测数据集动作。为此探针(probe)学习了新的动作查询和线性头。分析是在 dog-trot 环境中进行的,该环境拥有 38 个子动作维度,被离散化为 30 个区间(bins),从而产生了 DM Control 套件中最大且最具挑战性的组合动作空间。

6.3 分离学习到的表示的贡献

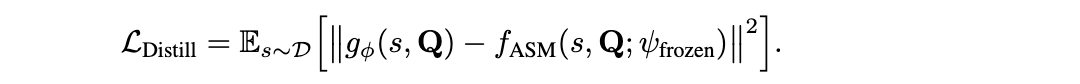
训练后,学生网络被冻结,并作为下游策略的轻量级、无注意力机制的特征提取器发挥作用。表 3 报告了该实验的结果。
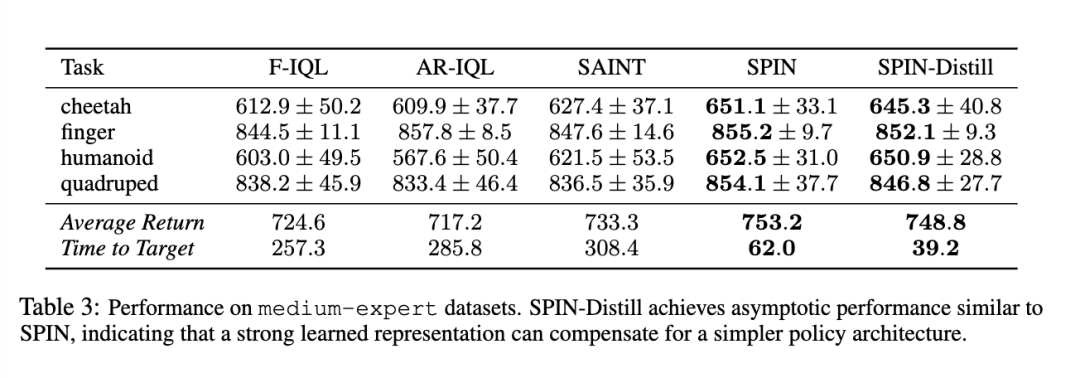
SPIN-Distill 与完整 SPIN 模型的渐近性能相差无几,并且显著优于所有其他基线方法,同时速度比 SAINT 快近 8 倍。这些结果提供了强有力的证据,表明 SPIN 的性能提升归因于预训练表示本身的质量,而非策略网络的具体架构。
6.4 涌现的快速适应
在确立了预训练和表示质量的重要性之后,我们接下来考察学习动态。表 4 报告了在 10,000 个梯度步之后达到的 F-IQL 渐近性能的百分比,这仅相当于总训练预算的 1%。在几乎所有环境中,SPIN 学习到的策略都能达到至少 90% 的目标性能,而基线方法的提升则缓慢得多。这种效应在异构数据集上最为显著。在使用 medium-expert 数据集的人形机器人(humanoid)任务中,SPIN 达到了目标性能的 93.4%,而次优方法 SAINT 仅达到了 9.3%。在 random-medium-expert 数据集上,在此期间,SPIN 在 cheetah 和 humanoid 任务中均超过了 F-IQL 渐近性能的 100%。
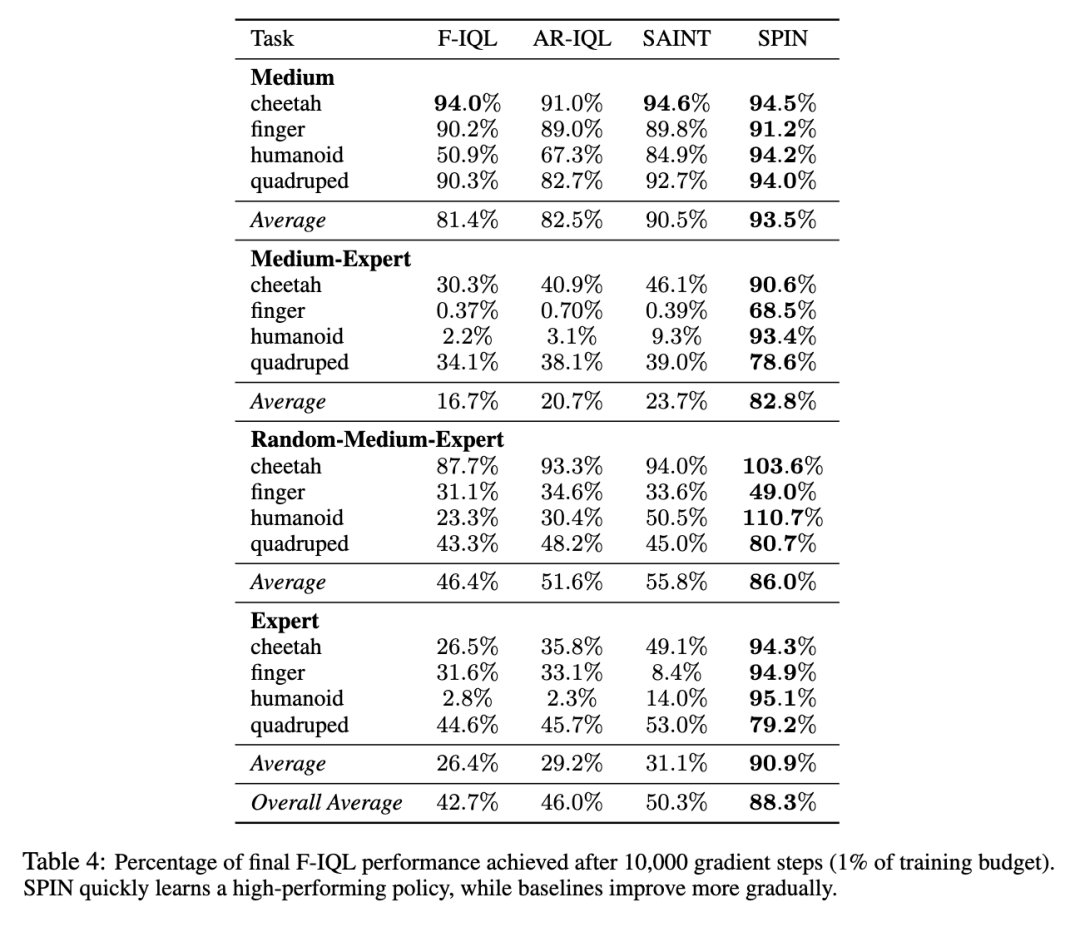
这种快速学习也阐明了 SPIN 的挂钟时间效率(表 1)。下游 RL 阶段的计算开销主要由 Actor-Critic 循环占据,该循环需要在每个梯度步对 Actor、Critic 和目标网络进行重复评估,以及进行贝尔曼备份(Bellman backups)。相比之下,ASM 预训练阶段是一个应用于掩码子动作的、稳定的、单次遍历(single-pass)的监督目标。因此,其相对成本极低:在 medium-expert 数据集上,预训练仅占 cheetah 总挂钟时间的 5.6%,finger 的 1.4%,以及 humanoid 和 quadruped 的 1.6%。
综上所述,这些结果表明 ASM 提供了一个强有力的结构先验,极大地简化了下游学习。端到端基线方法必须联合发现动作结构和控制,导致初始进展缓慢,而 SPIN 则利用连贯的表示开始策略学习,从而实现了高效的早期适应并减少了整体训练时间。
7 讨论与结论
在离散组合动作空间中进行强化学习,需要在指数级数量的组合动作中进行搜索,同时确保所选子动作构成连贯的动作组合。一些方法通过忽略动作结构来简化策略学习(Tang et al., 2022; Beeson et al., 2024),但代价是丢弃了关键的子动作依赖关系。其他方法尝试同时捕捉结构并求解控制问题(Zhang et al., 2018; Landers et al., 2024; 2025),但通常计算开销极大且不稳定。相比之下,SPIN 采用两阶段过程将表示学习与策略学习分离。在第一阶段,动作结构模型(ASM)学习一个表示函数,该函数以状态 ss 为条件,在子动作上诱导一个特征空间,其中结构连贯的联合动作位于一个低维流形上。随后,该表示被冻结并在第二阶段重用,此时控制问题简化为在预训练 ASM 之上训练轻量级策略头。
在数据集大小和质量、动作维度以及动作基数各异的基准测试中,SPIN 相比当前最优方法将平均回报最高提升了 39%,并将达到强基线性能所需的时间最多缩短了 12.8 倍。这些收益在具有挑战性且更贴近现实的 medium-expert(中等-专家)和 random-medium-expert(随机-中等-专家)数据集中最为显著。
针对性分析阐明了 SPIN 的有效性。最终性能随着学习到的表示质量的提升而提高,证实了控制问题的瓶颈在于结构发现。一旦该结构可用,策略便能快速学习,在极小的训练比例内即可达到其最终回报的大部分。线性探针进一步表明,学习到的表示在生成完全协调的动作方面比随机基线有效 45 倍,为下游智能体的成功提供了直接且定量的解释。
尽管 SPIN 展现了强大的性能,但仍存在若干未来工作方向。将 SPIN 扩展至 CQL 等值正则化方法是一个有前景的方向。一个自然的下一步是开发混合目标,将 SPIN 的“表示优先”设计与温和的保守正则化相结合——例如,将惩罚限制在 ASM 提议的候选联合动作上,或应用于子动作级别,从而避免在完整组合空间上进行难以处理的全局操作。将 SPIN 适配于具有除排列等变性以外结构假设的动作空间(例如有序或基于序列的子动作)是另一个未来方向。最后,与所有离线方法一样,SPIN 的泛化能力最终取决于数据集的覆盖范围,在稀疏或有偏数据下提高鲁棒性仍然是一个重要的开放挑战。
SPIN 为结构化动作空间中的控制引入了一种“表示优先”的视角。通过首先学习合理动作的流形,随后重用表示函数进行下游决策,它将复杂的组合问题简化为可处理的策略学习任务。这种解耦为高维、结构化领域的强化学习提供了一个原则性框架。
原文链接:https://arxiv.org/pdf/2601.04441
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号