RAG 工程里最大的痛点解决了,已开源


关于 RAG 这个话题,我之前写过:
- RAG原作者:我们仍然需要RAG(并且永远需要)
- 一套完整的 RAG 脚手架,附完整代码,基于LangChain
- RAG必备,100页PDF文档秒级精准解析!实测,很强!
今天聊一个完全不一样的角度——RAG / Agent context 工程里最大的痛点,从来不是 chunking 也不是 rerank,而是"数据陈旧"
你给 Agent 喂的代码库、会议纪要、Slack 记录、文档站,每天都在变。LangChain 那一套一次性建完索引就万事大吉?做 demo 行,上生产你就知道有多痛——文件改一个,整个 vector DB 要不要重建?build 一次几十分钟?凌晨跑批结果第二天还是看到旧数据?
就是冲这个痛点来的,我今天介绍一个项目叫 CocoIndex
地址:github.com/cocoindex-io/cocoindex
它给自己的定位很狠:"为 Agent 提供持续 fresh 的上下文"——不是搭一个 RAG 框架,是搭一个专门为 AI workload 设计的增量数据引擎
我看完它的设计哲学之后只有一个感觉:这才是 RAG / agent context 的正确打开方式
简介
先放一句话定位:
❝CocoIndex is an incremental engine for long-horizon agents.Turn codebases, meeting notes, inboxes, videos … into live context for your agents to reason over effectively — with minimal incremental processing. Fresh data anytime.
翻译成大白话:把企业里的代码库、会议笔记、邮件、视频、文档全部接进来,统一变成 Agent 可查询的实时上下文,只重处理变化的部分
它的核心心智模型只有一句话——target = F(source)
你声明目标状态,引擎负责让目标状态和源数据持续同步。源变了或者代码(F)变了,引擎自动算出 delta 重跑。这套思路在前端工程师眼里非常熟悉——就是 React 在数据工程的版本
官方原话叫 "React for data engineering",我觉得说得相当准确
核心特点:
- 增量优先(Incremental by default):每次只处理 delta,单文件改动 → 单行重 sync,不再有"凌晨重建索引"这种事
- 声明式(Declarative):Python 写转换函数,引擎自动并行调度,没有 DAG,没有 YAML,没有 Airflow 那一堆运维负担
- 代码改了也是 delta:F 变了之后只重跑受影响的行,schema 自动演进,no index swap, no downtime——这点我得给个 star,比 LangChain 那种"换个 embedding model 就重建一切"友好十倍
- 为长 horizon agent 设计:不是 demo 级框架,retry / back-off / dead letter / lineage / observability 全部内建,就是奔着生产去的
- Rust 内核 + Python 接口:性能层 Rust,业务层 Python,在 RAG 框架里属于稀缺组合
安装
CocoIndex 是 Python 包,pip 直接装:
pip install -U cocoindex
按官方 quickstart,5 分钟跑通一个 PDF → Markdown 的增量管道
先建个项目目录、放点 PDF 进去:
mkdir cocoindex-quickstart && cd cocoindex-quickstart
mkdir pdf_files
echo "COCOINDEX_DB=./cocoindex.db" > .env
pip install -U cocoindex docling
写一个 main.py,把 PDF 转 Markdown 的逻辑声明出来:
import pathlib
import cocoindex as coco
from cocoindex.connectors import localfs
from cocoindex.resources.file import PatternFilePathMatcher
from docling.document_converter import DocumentConverter
_converter = DocumentConverter()
@coco.fn(memo=True)
def process_file(file: localfs.File, outdir: pathlib.Path) -> None:
markdown = _converter.convert(file.file_path.resolve()) \
.document.export_to_markdown()
outname = file.file_path.path.stem + ".md"
localfs.declare_file(outdir / outname, markdown, create_parent_dirs=True)
@coco.fn
asyncdef app_main(sourcedir: pathlib.Path, outdir: pathlib.Path) -> None:
files = localfs.walk_dir(
sourcedir,
recursive=True,
path_matcher=PatternFilePathMatcher(included_patterns=["**/*.pdf"]),
)
await coco.mount_each(process_file, files.items(), outdir)
app = coco.App(
"PdfToMarkdown",
app_main,
sourcedir=pathlib.Path("./pdf_files"),
outdir=pathlib.Path("./out"),
)
跑起来:
cocoindex run main.py
第一次会处理所有 PDF,第二次再跑——只有新增或修改的 PDF 会被处理,其他的因为 @coco.fn(memo=True) 标记被自动跳过
注意几个细节:
@coco.fn(memo=True):标记这个函数的输出可缓存,输入指纹一致就直接复用结果localfs.declare_file():声明一个 target 文件,源被删了 target 也会自动跟着删,自动反向 GCcoco.mount_each():每个文件自动挂一个独立的处理组件,并行跑
整个心智模型就是写一次性脚本——但引擎自动给你套上增量、缓存、并行、target sync 这一整套生产能力
进阶案例:把播客做成知识图谱
PDF → Markdown 太朴素了,看不出威力。CocoIndex 官方博客里有一个我特别喜欢的进阶 demo——把 Lex Fridman、Dwarkesh Patel 的播客做成可查询的知识图谱
整体管线是这样的:YouTube URL → yt-dlp 下载音频 → AssemblyAI 带说话人识别的转录 → LLM 抽取人物 / 技术 / 组织 / 论断 → SurrealDB 存图
下图是整个管线的架构图:
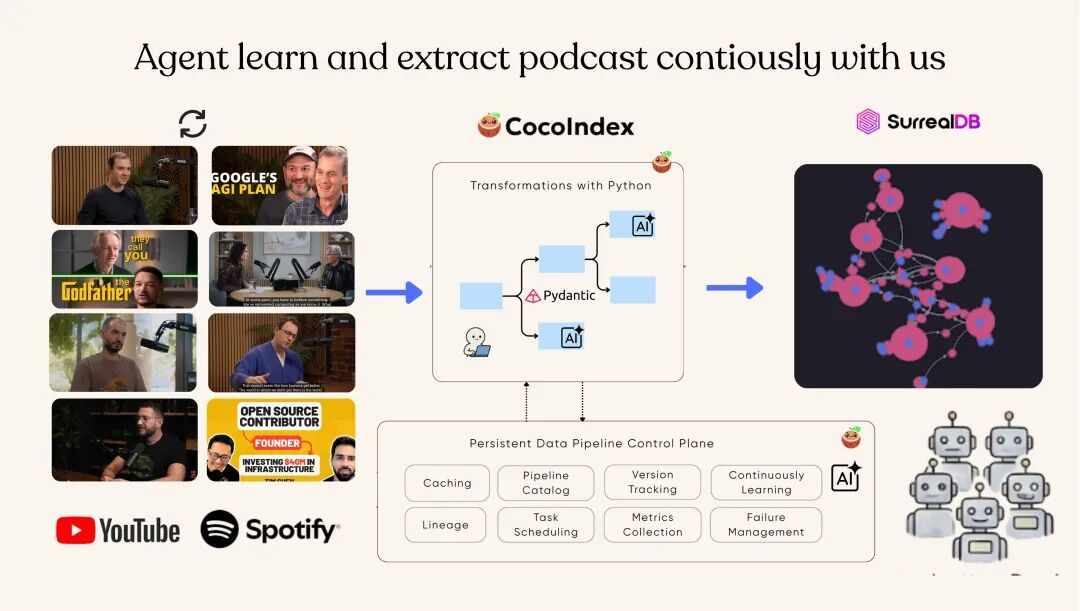
CocoIndex 播客知识图谱管线
CocoIndex 播客知识图谱管线
知识图谱的 schema 设计了 5 种节点(session / statement / person / tech / org)和 4 种关系:
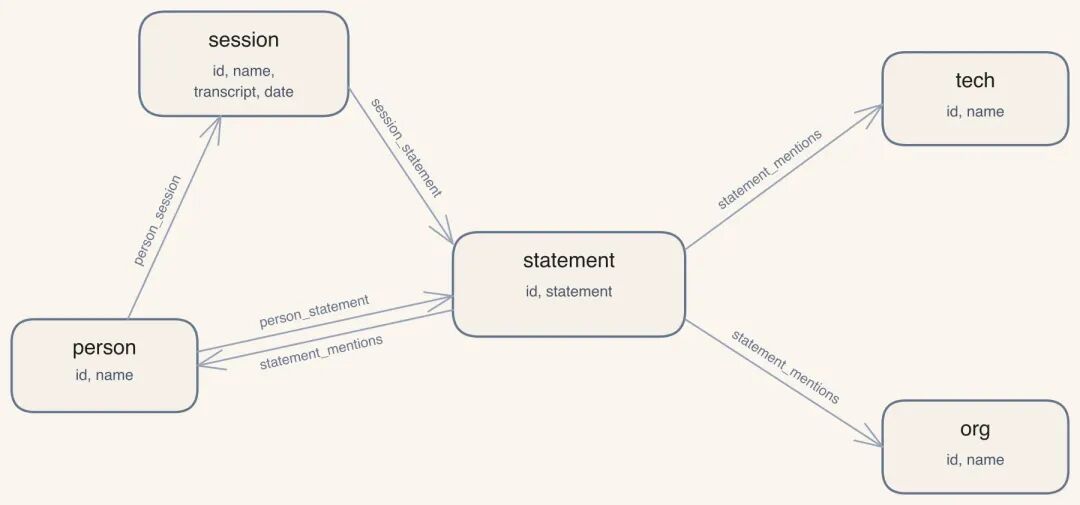
知识图谱 schema
知识图谱 schema
整个流程跑三个 phase:
Phase 1:每个 episode 独立处理——下载、转录、LLM 抽实体和论断。session 和 statement 立刻写库,因为不需要跨 episode 去重
Phase 2:跨 episode 收集所有人名 / 技术名 / 组织名,用 embedding 相似度 + LLM 二次确认做实体消歧(同一个 GPT-4 不同集里可能写成 "GPT-4"、"GPT4"、"OpenAI's GPT-4")
Phase 3:把消歧后的实体和关系写库
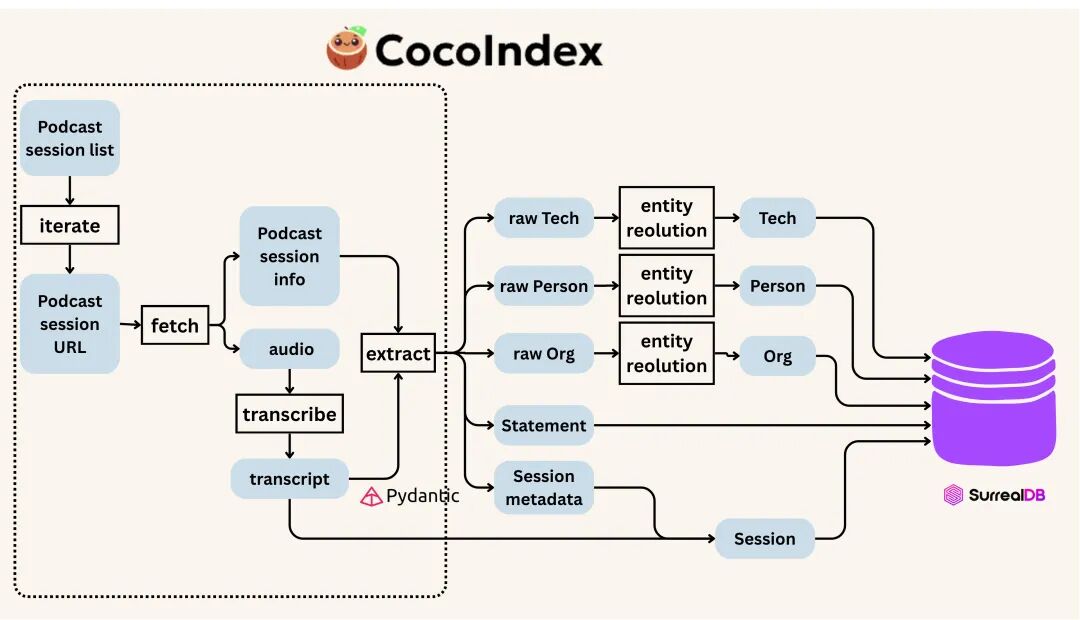
Phase 1 详细流程
Phase 1 详细流程
代码骨架长这样(取最关键的 fetch_transcript 一段):
@coco.fn(memo=True)
asyncdef fetch_transcript(youtube_id: str) -> SessionTranscript:
url = f"https://www.youtube.com/watch?v={youtube_id}"
with tempfile.TemporaryDirectory() as tmpdir:
audio_path = os.path.join(tmpdir, "audio.mp3")
ydl_opts = {"format": "bestaudio/best", "outtmpl": audio_path,
"quiet": True,
"postprocessors": [{"key": "FFmpegExtractAudio",
"preferredcodec": "mp3"}]}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(url, download=True)
config = aai.TranscriptionConfig(speaker_labels=True)
transcript = aai.Transcriber().transcribe(audio_path, config)
utterances = [Utterance(speaker=u.speaker, text=u.text)
for u in transcript.utterances]
return SessionTranscript(utterances=utterances, ...)
注意那个 @coco.fn(memo=True)——同一个 YouTube ID 跑过一次之后永远不会再下载第二次,哪怕你重启进程、改了下游的 LLM prompt,转录这一步的结果直接复用
我看完这个 case 的最深感受:这就是为什么"data infra for AI"应该是一个独立赛道
LangChain 那种"我封装一遍 OpenAI、Pinecone、PDF loader 就叫框架"的玩法,跟 CocoIndex 这种从增量引擎、lineage、schema 演进、failure recovery 一层一层往下做的根基性工作,根本不是同一个量级
总结
老章对它的评价:这是目前我见过最像"工业级 RAG/agent context 基础设施"的开源项目
优点:
- 心智模型极其干净,target = F(source),剩下交给引擎,写起来跟一次性脚本没差别
- 增量是 first-class citizen,不是"我们也支持增量"那种半吊子
- 代码改动也算 delta,schema 自动演进,对长期维护的 RAG 系统来说太重要了——你换个 embedding model 不用全量重建
- Rust 内核保证了性能,长跑大规模数据的场景比纯 Python 框架靠谱
- 内置 CocoInsight 控制平面,lineage / 缓存 / 版本 / 调度全可观测,运维友好
- 文档质量很高,每个 example 都是开箱即跑的工业级代码,不是"hello world"水平
缺点 / 局限:
- 学习曲线比 LangChain 陡——你得理解"声明式增量"这套思路,写惯了命令式管道的人需要扭一下脑子
- 中文资料目前几乎为零,社区问题主要在 Discord,英文交流
- target 端连接器现在主要覆盖 vector DB / graph DB / data warehouse,传统的全文检索(ES / OpenSearch)支持还在补
- 团队还小(一年从 1k stars 走过来),生态成熟度不如 LangChain / LlamaIndex 那种巨无霸
适合谁用:
- 在做生产级 RAG 系统的工程师,特别是数据每天都在变(codebase / Slack / 文档站 / 邮件)的场景
- 在做编码 agent / code-review agent / security-audit agent,需要随时拿到最新代码索引和 call graph
- 在做知识图谱 + LLM,需要持续从多源数据里增量抽实体的
- 觉得 LangChain 一坨胶水代码不够"工程化"的人
不适合谁:
- 只做单次实验、demo、一次性 batch 跑完就不管的场景——增量引擎对你是 overkill
- 完全不会写 Python、希望 zero-code 拖拖拽拽的——这玩意儿还是面向开发者的
- 公司已经有重度 LangChain / LlamaIndex 投入、且数据规模不大的——迁移收益不一定值得
One More Thing
CocoIndex 团队 2025 年 3 月开源,5 月 8 日 1k stars,到现在差不多一年时间,已经迭代到 v1,commit 节奏非常猛
他们 blog 里有篇文章叫 *"AI-Native Data Pipeline - Why We Made It"*,核心观点我特别认同:
❝下一波 AI 应用真正的瓶颈不在模型,而在喂给模型的数据是不是新鲜、可信、可追溯
模型只能做它看到的数据所允许的判断。如果你给 Agent 的代码索引是上周的、文档是上个月的、对话历史是上次重建索引时的——再聪明的 Agent 也会一本正经地胡说八道
模型卷了三年,是时候卷一卷"喂给模型的数据"了——CocoIndex 这条路是对的
一句话总结:如果你正在认真做 RAG 或 Agent context,今晚就装上玩玩,CocoIndex 大概率会改变你对"数据管道"这件事的理解
#CocoIndex #RAG #AgentMemory #增量索引 #知识图谱
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号