ICML 2026|DropoutTS:从”学什么”到”学多少”的鲁棒时间序列预测

ICML 2026|DropoutTS:从”学什么”到”学多少”的鲁棒时间序列预测

时空探索之旅
发布于 2026-05-11 14:37:28
发布于 2026-05-11 14:37:28
☀️ 论文标题:DropoutTS: Sample-Adaptive Dropout for Robust Time Series Forecasting
🌱 作者: Siru Zhong, Yiqiu Liu, Zhiqing Cui, Zezhi Shao, Fei Wang, Qingsong Wen, Yuxuan Liang
🌼 机构:香港科技大学(广州),中国科学院计算技术研究所,松鼠 AI
🔗 论文链接:https://arxiv.org/abs/2601.21726
🌐 项目主页:https://github.com/CityMind-Lab/DropoutTS

点击文末阅读原文跳转本文arXiv链接
摘要
深度时间序列模型在真实应用中普遍面临噪声干扰。现有鲁棒性建模策略往往走向两个极端:一类方法通过样本筛除等方式决定”哪些数据该学,哪些数据要丢掉”,另一类方法则引入额外先验或复杂不确定性建模,代价较高,难以兼顾效果与效率。针对这一问题,DropoutTS 提出了一种新的思路:不再重点回答”学什么”,而是回答”学多少”。
论文提出了一个与模型无关的插件式方法,通过样本自适应 Dropout(Sample-Adaptive Dropout) 动态调节模型的学习容量。具体来说,DropoutTS 利用频谱稀疏性,在频域中估计样本级噪声强度,并将噪声分数映射为不同的 dropout rate。这样一来,模型可以对干净样本保留更多表达能力,对高噪声样本施加更强正则化。
论文在多种噪声条件和公开基准上的实验表明,DropoutTS 能够在无需修改主干架构、且仅引入极少额外参数的前提下,稳定提升强基线模型的鲁棒性与预测表现。
1. 引言
真实世界中的时间序列往往包含复杂噪声,包括传感器误差、随机扰动和异常事件。对于深度模型而言,这些噪声很容易被误当作有效模式加以拟合,进而影响预测精度和泛化能力。
现有鲁棒时间序列建模策略主要可以分为两类,都通过决定模型“学什么”来达到更加鲁棒的效果:
- 第一类是 以数据为中心(Data-Centric) 方法。 这类方法通常通过筛除样本、样本重加权或异常检测等方式提升鲁棒性,核心关注点是”哪些样本值得学”。然而,这类”删除或保留”的离散决策往往过于粗糙,可能误伤有效信息,进而带来信息损失。
- 第二类是 以模型为中心(Prior-Centric) 方法。 这类方法通常建立在信息瓶颈理论、贝叶斯概率框架等基础之上,通过显式建模不确定性、噪声分布或先验结构来提升鲁棒性。尽管这一思路在理论上更为完整,但在实际中常常面临着先验假设僵化的风险,同时也常常伴随着更高的建模复杂度与计算代价。
我们提出将研究视角从传统的”学什么”转向”学多少”,并将这一新范式概括为以容量调节为中心(Capacity-Centric):不是通过删除数据或引入重型先验去处理噪声,而是直接调节模型对不同样本的有效学习容量。
基于上述观察,我们提出了 DropoutTS。该方法是一个模型无关、即插即用且以容量调节为核心的鲁棒学习框架,能够在避免信息损失的同时,绕开复杂先验鲁棒性建模所带来的额外负担。
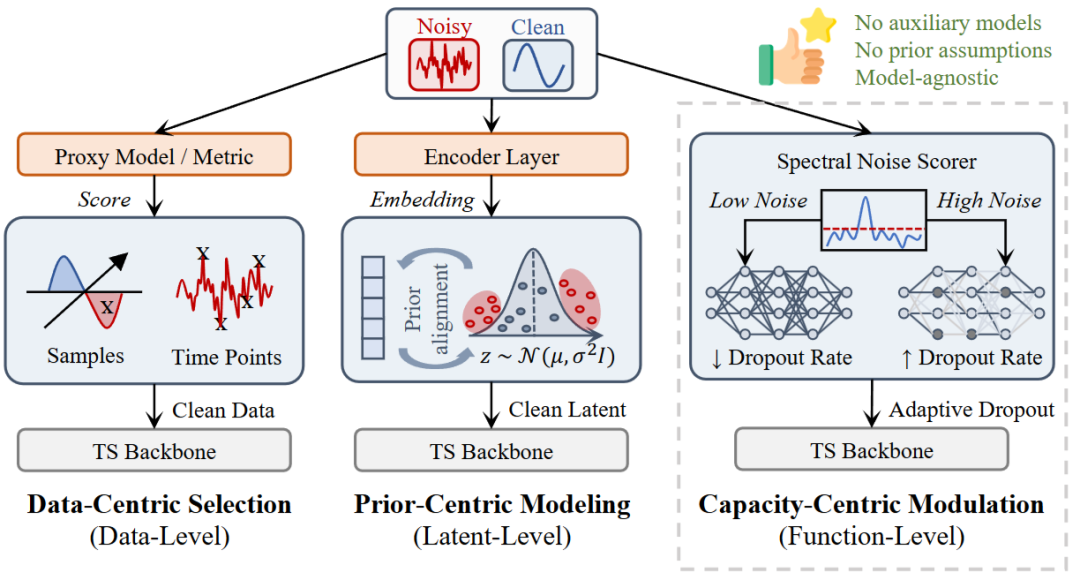
三种范式对比图
三种范式对比图
图 1:不同鲁棒性范式的对比。(1) 以数据为中心:数据的剔除会导致不可避免的信息损失。(2) 以模型为中心:僵化的概率约束增加了建模复杂度。(3) 以容量为中心:通过样本自适应 Dropout(Sample-Adaptive Dropout)动态调节模型容量,兼顾预测保真度与鲁棒性。
2. 方法:DropoutTS
DropoutTS 的整体框架由两个核心组件组成:频域噪声评分器(Spectral Noise Scorer) 和 样本自适应 Dropout(Sample-Adaptive Dropout)。其核心思想是,先在频域中估计样本级噪声强度,再将噪声分数映射为动态 dropout rate,从而在端到端训练过程中按样本调节模型学习容量。
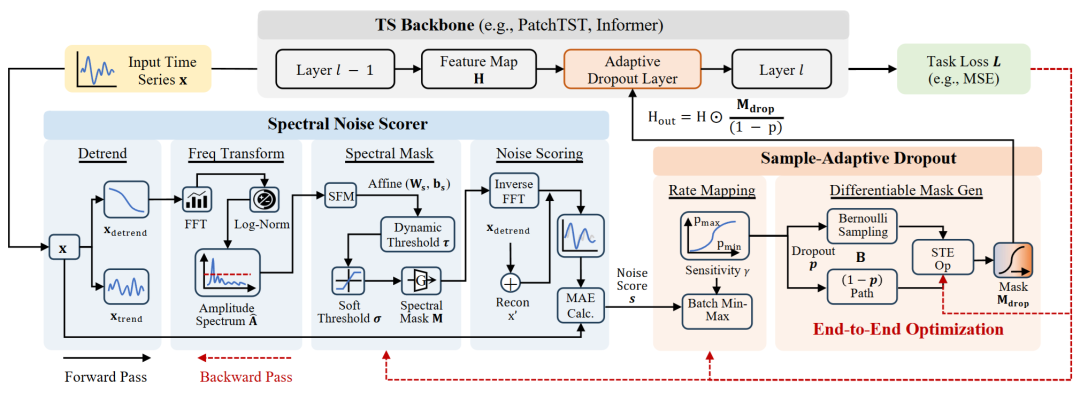
DropoutTS 整体框架示意图
DropoutTS 整体框架示意图
图 3. DropoutTS 整体框架示意图。作为一个模型无关的插件,DropoutTS 将默认时序建模骨干网络的 dropout 替换为自适应 dropout,整体由两个核心组件构成:(1)频域噪声评分器(Spectral Noise Scorer),用于量化样本级噪声;(2)样本自适应 Dropout(Sample-Adaptive Dropout),将噪声分数映射为动态 dropout rate。
2.1 频域噪声评分器(Spectral Noise Scorer)
为了给不同样本分配不同 dropout rate,首先需要估计每个样本的噪声强度。DropoutTS 没有直接在时域中做启发式判断,而是转向频域分析。实验表明,时间序列中的有效结构通常会在频谱中表现出相对集中的模式,而噪声更可能表现为分散、振幅较低的、缺乏主导峰值的频谱形态。
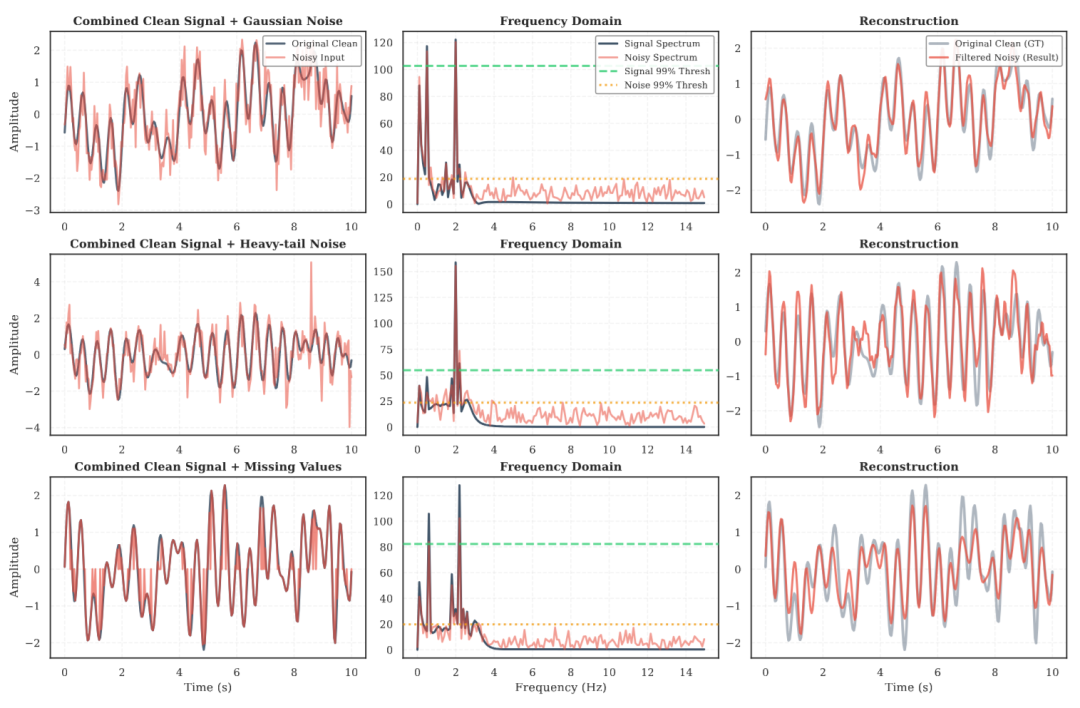
图 2:频谱稀疏性验证。
图 2:频谱稀疏性验证。
图 2:频谱稀疏性验证。该图展示了复合信号(周期项(Periodic)+ 趋势项(Trend)+ 变频信号(Chirp)+ 非平稳方差(AM))在不同噪声条件下的分析结果。左图为受扰动的时域输入;中图表明频域中稀疏的高能信号成分与分散噪声之间具有清晰分离;右图说明基于频谱阈值化的重建结果与真实信号高度一致,验证了该方法对异常值与缺失数据的鲁棒性。
这一模块可以分成四步。
- 去趋势(Detrending) 先从原始序列中去掉全局趋势项。这样做是为了缓解快速傅里叶变换(FFT)中的谱泄漏(spectral leakage)问题。因为如果序列本身带有明显趋势,直接做 FFT 时,窗口边界的不连续会在频域里产生额外干扰,影响后续对信号和噪声的区分。
- 频域映射与 Log-scale 归一化(Spectral Transformation) 对去趋势后的序列做 FFT,把时域信号映射到频域。这样做是因为很多结构化模式在频域里更容易看清,例如主要周期和高能成分,而噪声通常更分散。映射后,我们对频谱幅值进行 Log-scale 归一化:先计算对数幅值 ,再做 min-max 归一化到 。这一步骤至关重要,因为真实信号的有效幅值可能跨越多个数量级,线性归一化容易让弱但有效的周期信号被淹没,而 Log-scale 能更好地平衡不同强度信号的检测灵敏度。
- 谱掩码(Spectral Masking) 在频域中,模型根据当前样本的频谱特征生成一个软掩码,用来保留主要频率成分、抑制更可能属于噪声的频率成分。这里引入频谱平坦度(Spectral Flatness Measure, SFM)作为动态阈值的锚点,是因为结构化信号通常频谱更集中,而噪声频谱通常更平坦。
- 残差重建与噪声得分(Residual Reconstruction and Noise Scoring) 将掩码后的频率成分重建回时域,并与原始输入进行比较。两者之间的重建残差被用来定义样本级噪声得分。重建误差越小,说明该样本的主要模式越容易被稳定恢复,更可能是低噪声样本;重建误差越大,则说明其中包含更多难以解释的扰动,对应更高的噪声水平。
换句话说,如果一个样本难以被主要频率成分稳定重建,它更可能是一个高噪声样本。
2.2 样本自适应 Dropout(Sample-Adaptive Dropout)
这一模块可分成三步。
- 噪声到 dropout rate 的映射(Noise-to-Dropout Mapping)模型先把每个样本的噪声得分映射成对应的 dropout rate。具体来说,先将噪声得分在当前 batch 内归一化到 ,再通过可学习的敏感度曲线映射到 这个 dropout 区间: 其中, 是第 个样本的噪声得分, 是可学习的敏感度参数, 是该样本对应的 dropout rate。噪声越大的样本获得越强的正则化,噪声越小的样本则保留更多有效容量。
- 按样本调节学习容量(Sample-wise Capacity Modulation) 得到 dropout rate 后,模型不再对整个 batch 使用统一的固定 dropout,而是让不同样本使用不同的 dropout 强度。这样做是为了避免固定 dropout 的问题:同一个正则化强度往往无法同时适应干净样本和高噪声样本。论文认为,这正是 DropoutTS 用来缓解 Fixed Dropout Paradox 的关键。
- 端到端可训练(End-to-End Learning) 标准 dropout 的采样操作是离散的,无法直接求导。为了实现端到端训练,DropoutTS 采用 Straight-Through Estimator(STE) 技巧:在前向传播时采样二值掩码 ,在反向传播时让梯度直接流过 dropout rate ,从而优化频域掩码参数()和敏感度参数 。这一机制使 DropoutTS 无需额外代理模型、无需修改 backbone 结构,即可作为即插即用插件直接增强已有时序模型的鲁棒性。
3. 实验
我们在多个层次上使用多种主流 backbone 进行评测验证了 DropoutTS 的有效性。以下是核心实验发现的快速总结:
📊 核心实验亮点
- 合成噪声场景:在 Informer 上平均 MSE 降低 46.0%,最高达 48.2%();六种 SOTA backbone 平均提升 9.8%
- 真实数据集:在 Electricity 上 Informer 的 MSE 降低 68.0%,ETTh2 上降低 47.6%
- 模型无关:兼容 Transformer、CNN、MLP 等 6 种主流架构,无需修改 backbone
- 极低开销:仅增加 4 个参数,Informer 训练时间节省 31.0%(加速 1.45 倍)
- 正交互补:与 Selective Learning 数据筛选方法结合,进一步获得 2% 增量提升
- 消融验证:去掉去趋势设计导致 MSE 下降41.7%,验证各组件必要性
3.1 多种噪声条件下的稳定提升
首先,在可控噪声强度的合成场景(Synth-12)下验证了方法的基本行为。Synth-12 是一个物理驱动的合成基准,通过动态信号耦合(叠加非线性趋势、准周期循环、变频信号等)和对抗性噪声注入(叠加高斯噪声、重尾尖峰、随机观测缺失)构建复合时序流形。通过调节噪声强度 ,创建了从 SNR 23.77 dB 到 7.39 dB 的难度梯度。
如图 4 所示,随着噪声水平增强(),固定 dropout 的最优点并不一致,而 DropoutTS 可以根据样本噪声自动分配正则化强度,从而比固定 dropout 表现更稳定。
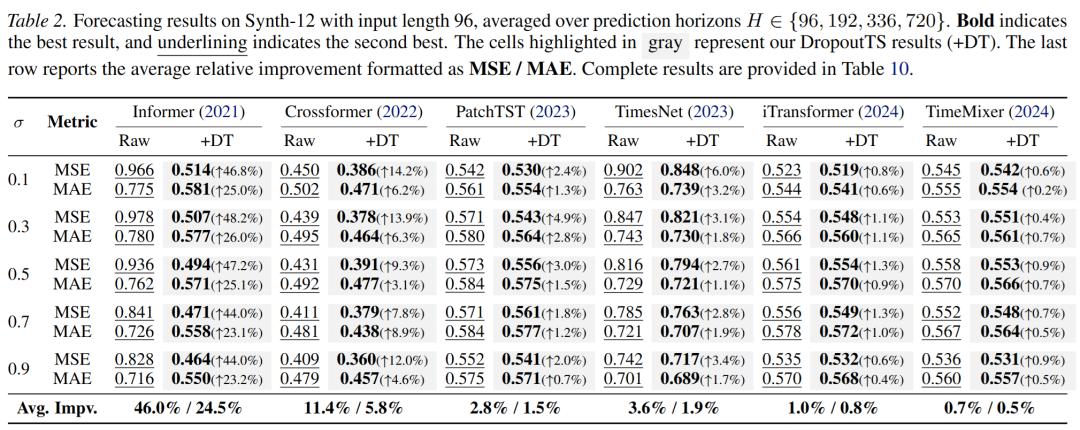
合成实验结果:不同噪声水平下的性能对比
合成实验结果:不同噪声水平下的性能对比
图 4:合成数据集(Synth-12)上的鲁棒性验证。横轴为噪声强度 ,纵轴为预测误差(MSE)。DropoutTS(蓝色)在各噪声水平下均优于固定 dropout(红色),且有效缓解了 Fixed Dropout Paradox。
定量结果显示,DropoutTS 对噪声敏感的模型(如 Informer)提升最为显著:
- Informer:平均 MSE 降低 46.0%,MAE 降低 24.5%;在 时 MSE 降幅高达 48.2%
- Crossformer:平均 MSE 降低 11.4%,MAE 降低 5.8%
- TimesNet:平均 MSE 降低3.6%,MAE 降低 1.9%
- 即使是强基线如 PatchTST、iTransformer、TimeMixer,也能获得 0.7%–2.8% 的稳定提升
Fixed Dropout Paradox 的定量可视化
如图 5 所示,为了深入理解固定 dropout 的问题,论文对 Informer 和 Crossformer 的性能轨迹进行了可视化分析:
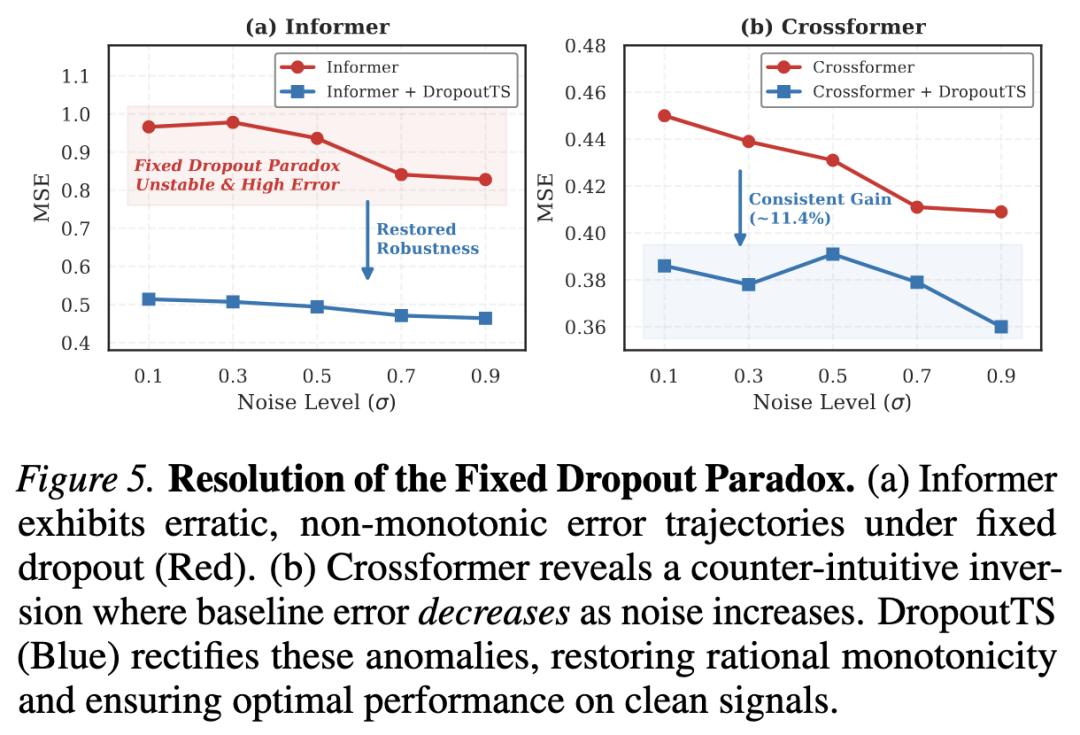
Fixed Dropout Paradox 可视化分析
Fixed Dropout Paradox 可视化分析
图 5:Fixed Dropout Paradox 的定量可视化。(a) Informer 在固定 dropout 下呈现非单调的"三阶段行为";(b) Crossformer 出现反直觉的误差随噪声增加而下降的现象。DropoutTS(蓝色)修正了这些异常,恢复了合理的单调性。
关键观察:
- Informer(左图):固定 dropout(红色)呈现非单调的"三阶段行为":
- 低噪声:固定 dropout 损害了干净特征的学习
- 中等噪声:欠正则化触发过拟合峰值
- 高噪声:极端噪声反而充当随机增强,提升性能
- Crossformer(右图):出现反直觉现象——误差随噪声增加()反而单调下降,说明即使在先进架构中,干净数据下也存在"正则化饥饿"
- DropoutTS(蓝色):通过频谱噪声门动态校准正则化,消除了这些异常,确保在干净信号上达到最优性能
3.2 公开基准上的鲁棒性收益
在真实公开基准(ETTh1/h2、ETTm1/m2、Electricity、Weather、ILI)上,添加 DropoutTS 的 backbone 均能带来稳定收益。如图 6 所示,效果并不局限于某个单独模型或某类特定数据。
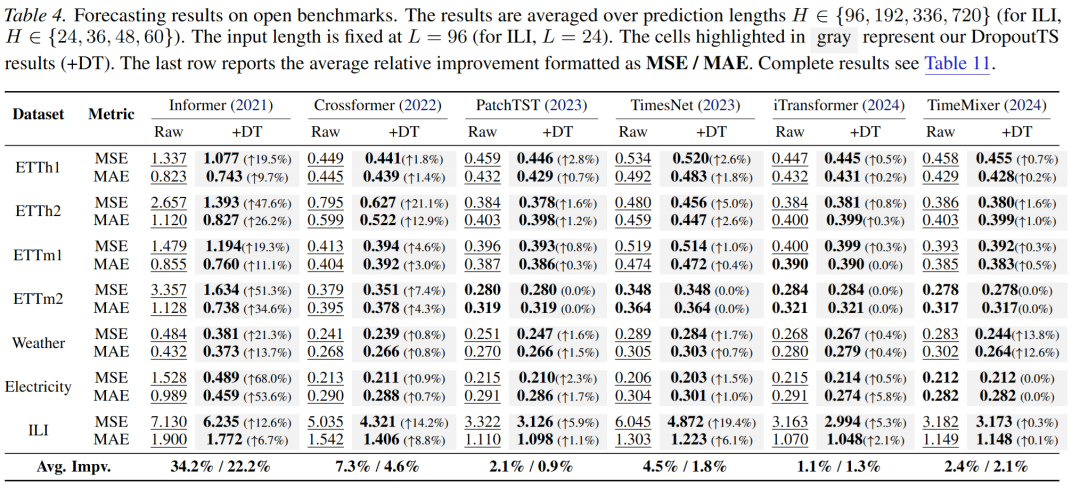
真实基准实验结果
真实基准实验结果
图 6:公开基准上的性能提升。展示了在多个数据集和预测长度下,DropoutTS 对 6 种主流 backbone 的增益。颜色越深表示提升幅度越大。
关键定量结果:
- Informer(噪声敏感模型):在 Electricity 数据集上 MSE 降低 68.0%,MAE 降低 53.6%;在 ETTh2 上 MSE 降低 47.6%,MAE 降低 26.2%
- TimeMixer(强基线):在 Weather 数据集上 MSE 降低 13.8%,MAE 降低 12.6%
- TimesNet:在 ILI 数据集上 MSE 降低 19.4%,MAE 降低 6.1%
- 平均而言,各 backbone 的 MSE 降幅在 1.1%–34.2% 之间
预测效果定性可视化
如图 7 所示,论文还提供了预测曲线的定性对比,直观展示 DropoutTS 如何改善预测质量:
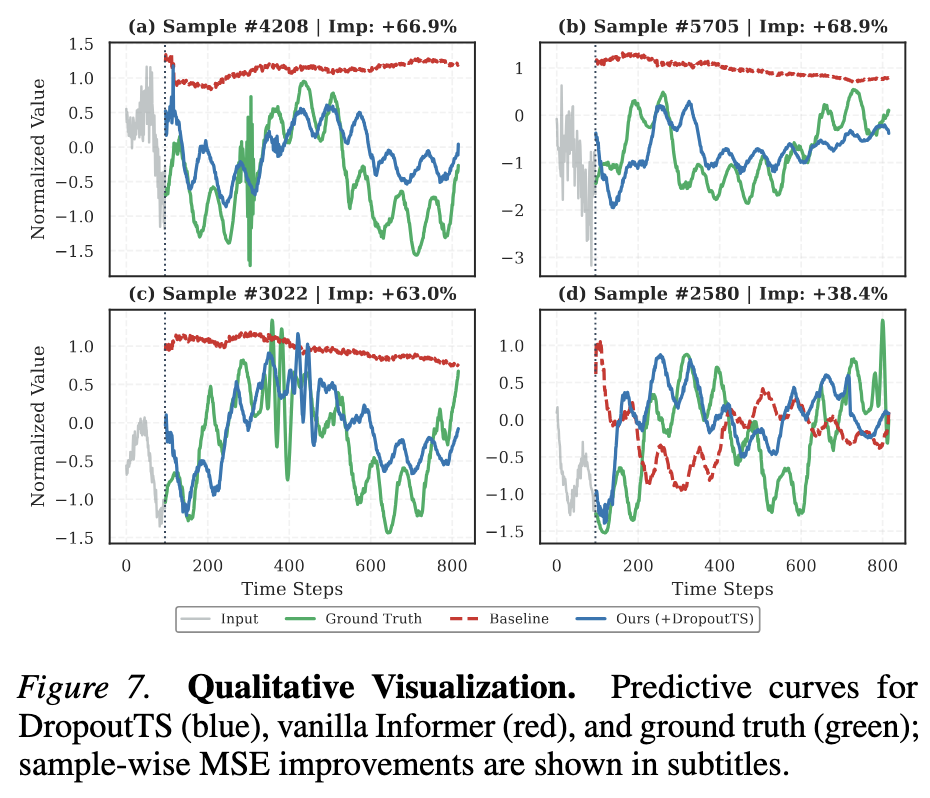
预测效果定性对比
预测效果定性对比
图 7:定性可视化对比。蓝色曲线为 DropoutTS,红色为原始 Informer,绿色为真实值。DropoutTS 能更好地跟踪时序动态,避免了原始模型的"均值趋平"现象。
观察发现:
- 原始模型(红色)在噪声输入下常坍缩为"均值趋平"的平坦线——标准 MSE 损失在随机振荡下收敛到平凡全局平均
- DropoutTS(蓝色)作为频谱引导的容量调节器,将频谱噪声强度转化为自适应 dropout rate,抑制高频伪影的记忆
- 这驱使模型关注主导谐波,恢复出锐利且同步的轨迹,忠实跟踪底层时序动态
3.3 与强 backbone 的兼容性
论文特别强调,DropoutTS 是一个模型无关插件(model-agnostic plugin)。实验结果显示,它能够与已有强基线模型自然结合,并在不改变主干网络结构的前提下提升性能。这一点非常关键,因为它意味着方法的贡献不仅是“提出了一个新模块”,而是“为已有模型提供了一个可直接复用的鲁棒增强手段”。
兼容性覆盖范围:
- Transformer-based:iTransformer、PatchTST、Crossformer
- CNN-based: TimesNet
- MLP-based: TimeMixer
所有实验均严格遵循原模型的超参数设置,仅调优 DropoutTS 的初始敏感度参数 ,验证了即插即用的便利性。
3.4 低额外开销
除了性能提升之外,论文还强调了方法的效率优势。与依赖复杂先验建模或额外网络分支的鲁棒方法相比,DropoutTS 只引入极少额外参数(仅 +4 个参数),且无需对 backbone 结构进行改造。
如表 1 所示,尽管频域操作(FFT/IFFT)会带来一定的训练延迟,但这一开销被加速收敛大幅抵消:
模型 | 参数量增加 | 训练轮数 | 总训练时间 | 时间节省 | 加速比 |
|---|---|---|---|---|---|
Informer | +4 | 30 → 16 | 2873 → 1982 | 31.0% | 1.45× |
TimeMixer | +4 | 20 → 16 | 2045 → 1819 | 11.0% | 1.12× |
更重要的是,自适应机制在推理阶段完全关闭,零额外推理延迟,非常适合实时部署场景。
3.5 消融实验的结论
论文还对方法中的关键设计做了系统分析,如图 8 和表 2 所示:
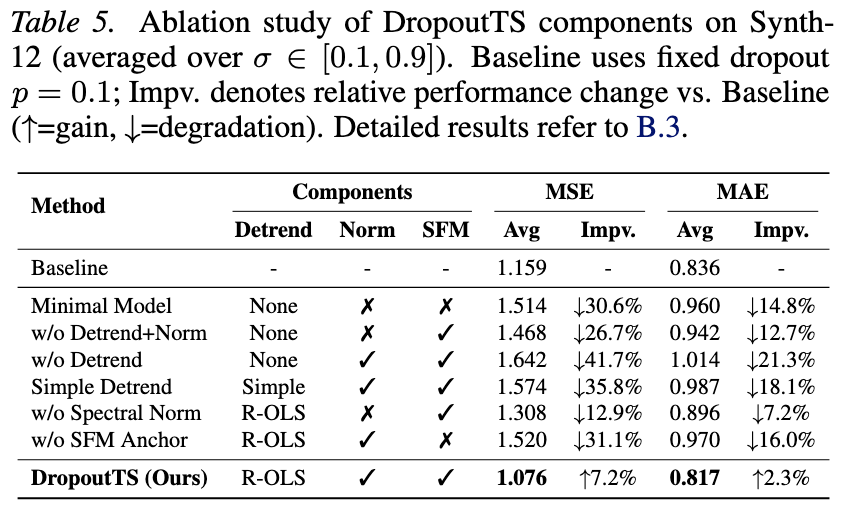
消融实验结果
消融实验结果
图 8:消融实验分析。展示了各组件对最终性能的贡献程度。
变体 | 去趋势 | 谱归一化 | SFM 锚点 | MSE | 相对变化 |
|---|---|---|---|---|---|
Baseline(固定 dropout) | - | - | - | 1.159 | - |
w/o Detrend | ✗ | ✓ | ✓ | 1.642 | 恶化 41.7% |
w/o SFM Anchor | ✓ | ✓ | ✗ | 1.520 | 恶化 31.1% |
w/o Spectral Norm | ✓ | ✗ | ✓ | 1.308 | 恶化 12.9% |
DropoutTS(完整) | ✓ | ✓ | ✓ | 1.076 | 改善 7.2% |
消融实验表明:
- 去趋势设计最关键:去掉后 MSE 恶化41.7%,说明趋势项会导致频谱泄漏,严重误导噪声评分
- SFM 锚点不可或缺:用纯可学习参数替代后 MSE 恶化 31.1%,验证频谱平坦度作为归纳偏置的必要性
- 谱归一化保障泛化:去掉后 MSE 恶化 12.9%,说明尺度不变的噪声检测至关重要
这些结果共同支撑了论文的核心论点:DropoutTS 的性能提升不是某个局部技巧偶然带来的,而是来自“频域估噪 + 动态容量调节”这一路径本身的合理性。
3.6 超参数鲁棒性
论文还验证了 DropoutTS 对超参数的敏感性。方法仅将初始敏感度参数 作为主要可调超参数,其余参数(dropout 上下界 、掩码锐度 、偏置 )均采用经验默认值。
如图 9 所示,实验发现:
- 保守设置():在所有噪声水平下均保持稳定低误差,是推荐的默认配置
- 激进设置():在极端噪声()下表现更优,符合更强过滤的需求
- 中间值():表现最差,呈现出非单调行为
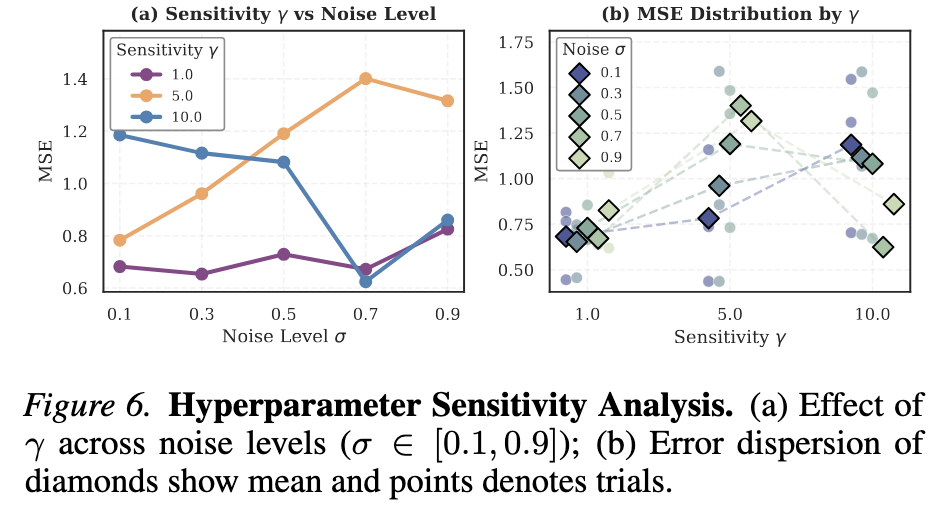
超参数敏感性分析
超参数敏感性分析
图 9:超参数敏感性分析。(a) 不同 值在各噪声水平()下的误差表现;(b) 各设置下的误差分布(菱形为均值,点为多次试验结果)。 作为保守默认值在所有噪声水平下均表现稳定。
这说明敏感度参数需要根据噪声 régime 进行特定校准,而 作为一个保守默认值具有良好的鲁棒性。这一特性大大降低了方法的调参负担,即插即用性更强。
3.7 与数据-centric方法的兼容性
一个关键问题是:DropoutTS 是否与现有的数据-centric鲁棒方法(如 Selective Learning)存在竞争关系?论文通过组合实验验证了二者的正交性。
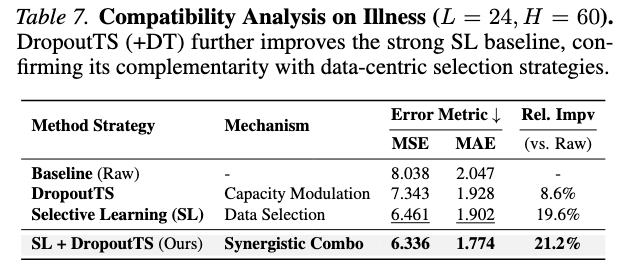
如图 10 和表 3 所示,在 Illness 数据集上:
方法策略 | 机制 | MSE | MAE | 相对提升 |
|---|---|---|---|---|
Baseline (Raw) | - | 8.038 | 2.047 | - |
DropoutTS 单独使用 | 容量调节 | 7.343 | 1.928 | 8.6% |
Selective Learning (SL) | 数据筛选 | 6.461 | 1.902 | 19.6% |
SL + DropoutTS(组合) | 协同作用 | 6.336 | 1.774 | 21.2% |
与 Selective Learning 的兼容性验证
与 Selective Learning 的兼容性验证
图 10:与 Selective Learning 的兼容性验证。展示了数据-centric 方法(SL)与容量-centric 方法(DropoutTS)的组合效果,证实二者正交互补。
核心发现:
- Selective Learning 通过丢弃低质量时间点,将 MSE 从 8.038 降至 6.461(提升 19.6%)
- 在 SL 基础上叠加 DropoutTS,MSE 进一步降至 6.336,MAE 降至 1.774
- 这一增量提升(约 2%)从实验上证实了两个范式的正交性:
- SL 在输入层筛选(数据-centric)
- DropoutTS 在功能层调节容量(容量-centric)
- 二者协同,抑制了二进制过滤无法捕捉的残余噪声
这意味着 DropoutTS 不仅可以独立使用,还能无缝集成到现有的数据清洗流程中,进一步提升最终性能。
总结
本文提出的 DropoutTS 通过将频域噪声估计与样本自适应 Dropout 相结合,首次从容量调节视角系统解决时间序列鲁棒预测问题。实验结果表明,该方法在预测精度、鲁棒性与计算效率上均显著优于现有方法,为真实噪声场景下的时间序列预测提供了一种即插即用且理论支撑的解决方案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号