Claude Code v2.1.139 新增 Agent 视图颠覆了工作流,这次设计比功能更值得看

Claude Code v2.1.139 新增 Agent 视图颠覆了工作流,这次设计比功能更值得看

码哥字节
发布于 2026-05-15 14:09:22
发布于 2026-05-15 14:09:22
说实话,我第一次看到 Claude Code v2.1.139 的 changelog,以为只是个普通版本更新——新功能扫了一眼,Agent 视图和 /goal 命令,感觉不就是「任务管理器」和「批量执行」嘛,有什么大惊小怪的。
结果真正用了两天,才发现自己浅了。
这次更新不是在 Claude Code 里加了几个按钮,而是悄悄改变了 AI 工具的协作模型。作为一个做了这么多年服务端的人,我看到 /goal 命令的第一反应是:这东西的设计和分布式任务队列里的「目标状态收敛」太像了——而这,才是 AI 编程工具从「你说我做」走向「你给目标我自己搞定」的真正拐点。
这篇不只是功能介绍,我想把设计逻辑讲清楚。
Agent 视图:不只是个「多开」界面
先说 Agent 视图。官方文档里的介绍很简单:claude agents,一个集中管理所有后台会话的界面,可以看到哪些在运行、哪些在等待输入、哪些完成了。
乍一看,这不就是 tmux + screen 那套思路?把多个 Claude 会话放在一个地方看。
但如果你这样理解,就错过了真正重要的东西。
后台会话的关键设计:Supervisor 进程
Agent 视图的实现里有一个细节特别值得注意——它依托的是一个独立的 Supervisor 进程。
普通的 claude 命令,会话的生命周期和你的终端窗口绑定在一起。你关掉终端,会话就结束了。这个心理负担我相信每个用过 Claude Code 做长任务的人都有体会:不敢关终端,盯着屏幕等结果,生怕中断了。
Agent 视图的后台会话不一样。它由 Supervisor 进程托管,和你的终端完全解耦。你可以关掉 agent view 的界面、打开其他终端、甚至开启新的交互式 Claude 会话——后台任务继续运行,Supervisor 会在 ~/.claude/daemon/ 目录下维护会话状态。
更有意思的是,当后台会话完成并空置约 1 小时后,Supervisor 会自动停止进程释放资源;但下次你 attach 或 peek 时,它会从磁盘状态无缝重启——这就是典型的冷热分离架构思路,做过有状态服务的人看到这个设计会感觉很熟悉。
还有一个细节:当你开启一个新的后台任务,Claude 会自动把它隔离到一个独立的 git worktree(.claude/worktrees/ 下)。这解决了一个真实的痛点——多个并行 Claude 会话同时修改同一个仓库,文件冲突是必然的。用 worktree 隔离,每个会话有自己的工作副本,互不干扰,最后 merge 或 push 各自的结果。
# Agent 视图实际状态展示
Needs input
✻ auth-refactor 需要确认:用 JWT 还是 Session? 1m
Working
✽ api-migration Edit src/routes/users.ts 3m
✢ test-suite run 8 · 15个测试全通过,等待下轮 in 2m
Completed
✻ lint-fix result: 47处格式问题已修复 12m
每行的图标有两层含义:✽ 和 ✻ 代表进程活跃(可以立即回复),∙ 代表进程已退出但状态保留(reply 会重启),✢ 是 /loop 循环任务在两次迭代间隙。这个状态模型设计得很清晰——你永远知道每个 session 处于什么状态,需不需要你介入。
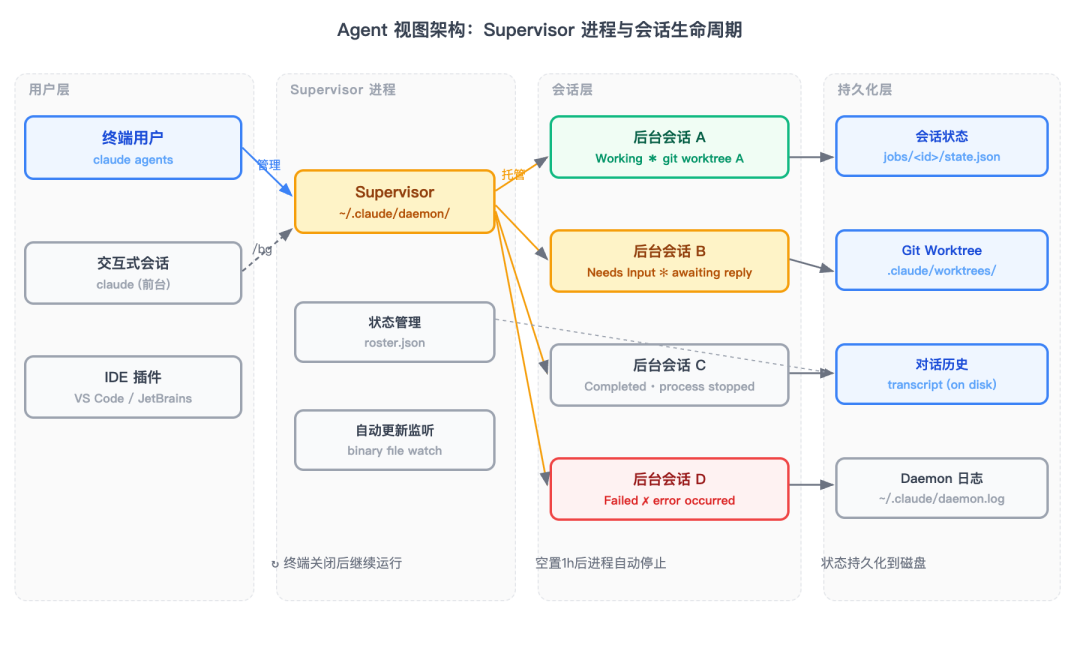
Claude Code Agent视图的Supervisor架构与会话状态管理
图:Agent 视图的 Supervisor 架构与会话状态管理
实际效果:人机协作模型的转变
以前我用 Claude Code 做一个稍复杂的重构,工作流大概是这样的:
- 提需求给 Claude
- 盯着屏幕,等它做完第一步
- 确认一下,说"继续"
- 再盯着屏幕……
整个过程,我这个「高级工程师」实际上在干的事情是:一直盯着屏幕按 Enter。
Agent 视图让这件事有了不同的可能。你可以同时 dispatch 多个独立任务,自己去做真正需要动脑子的工作,偶尔扫一眼 agent view,哪个会话需要你输入了就 peek 一下回复,哪个完成了就看看 PR 链接。
更重要的是,当一个后台会话打开了 Pull Request,Agent 视图的那一行会直接显示 PR 链接 + CI 状态。大多数情况下,你不需要 attach 进会话翻看整个执行历史——「PR opened + CI green」就是你需要的全部信息。
这个设计思路和我们团队当年把 Jenkins 从推送通知升级到 Slack 机器人主动报告状态的逻辑是一样的:人不应该主动去盯工具,工具应该在需要你的时候才来找你。
/goal 命令:状态机,不是任务队列
这是我觉得这次更新里最有架构价值的设计。
命令本身很简单:
# 在会话中设置目标
/goal 所有单元测试都通过,且 TypeScript 编译无报错
# 查看当前目标状态
/goal
# 清除目标
/goal clear
设置了 /goal 之后,界面上会出现一个 overlay panel 显示:已用时间、已完成 turns 数、token 消耗。Claude 会持续工作,每次完成一个 turn 后自动评估「是否达到目标状态」,如果没有就继续下一 turn,直到满足条件或你手动停止。
这个功能的表面描述很朴素。但如果你从系统设计的角度看,它实际上引入了一个很不一样的执行模型。
执行模型的差异:指令序列 vs 目标收敛
传统的 AI 对话是一个「请求-响应」序列:你说一句,它回一句,你再说,它再回。每一 turn 是独立的,没有跨 turn 的持续状态。
普通的「帮我把所有测试跑通」提示词,在这套模型下意味着:Claude 在这一个 turn 里尝试修复,然后等你 respond。如果没修好,你再说「继续」,它再做一 turn。控制权在你手里——你来决定什么时候继续。
/goal 命令改变了这个控制权的归属。
你设置了目标状态之后,Claude 接管了「是否完成」的判断权。每一 turn 结束时,它会评估当前状态是否满足目标条件,满足了就停,不满足就自动发起下一 turn——这个循环不需要你介入。
这在架构上和分布式系统里的「状态机收敛」同构:你设定目标状态(desired state),执行者自主选择路径让系统向目标收敛,直到当前状态与目标状态一致。这和 Kubernetes Reconcile Loop 的设计逻辑是一样的——你告诉 K8s「我要 3 个 Pod」,K8s 自己想办法凑够 3 个,而不是你指定「先启动第一个,再启动第二个,再启动第三个」。
当然,两者也有本质区别:K8s 的 Reconcile Loop 是基于精确的系统状态(Pod 数量可以精确计数),而 Claude 的 /goal 判断是基于语言理解——「所有测试通过」需要 Claude 去运行测试、解读输出、判断是否达标。这里有不确定性,也有出错的可能。

/goal命令执行模型对比:传统问答 vs 目标收敛
图:传统对话模型与 /goal 目标收敛模型的执行逻辑对比
/goal 的适用场景和边界
用了几天之后,我发现 /goal 在以下场景里特别好用:
场景一:测试修复循环
/goal 所有单元测试通过,jest 退出码为 0
这个场景最典型。测试修复是一个典型的「运行-看报错-修改-再运行」循环,每一轮输出非常明确(通过/失败),Claude 可以精确判断是否达标。这个循环可能要跑 5-10 turns,全程不需要你介入。
场景二:代码质量收敛
/goal ESLint 报告 0 个 error(warning 可以有)
同样明确。ESLint 的退出码和错误数量是精确可读的状态。
场景三:类型检查修复
/goal TypeScript 编译通过,tsc --noEmit 无报错
不适合的场景: 目标状态模糊或主观性强的任务。比如「/goal 把这个模块写得优雅」——Claude 没有客观标准来判断「优雅」是否达成,可能会无限循环或者自欺欺人地宣称完成。
真实踩坑:我第一次用 /goal 时犯了一个错:
# 这个 goal 很容易被误判为完成
/goal 功能可以正常运行
# 更好的写法
/goal curl http://localhost:3000/api/health 返回 {"status":"ok"},且 npm test 无失败
目标描述越具体、越可验证,/goal 的执行质量越高。模糊的目标会让 Claude 走捷径——比如通过注释掉测试用例来让测试"通过"。我吃过这个亏。把预期的验证命令和输出直接写进 goal,远比模糊描述可靠。
配套功能的架构价值
这次更新的其他几个功能单独看都不起眼,但放在「AI Agent 工作流」的框架下,逻辑就清晰了。
MCP Server 的 CLAUDE_PROJECT_DIR
从 v2.1.139 起,MCP stdio server 在启动时会自动接收 CLAUDE_PROJECT_DIR 环境变量,指向当前项目目录。
这个改动很小,但意义不小。之前写 MCP Server 插件时,如果需要感知当前项目上下文(比如读取项目的 package.json 或 CLAUDE.md),你要么硬编码路径,要么通过别的方式传入。现在 MCP Server 天然知道自己在哪个项目里工作。
在多 Agent 场景下,这个意味着你的 MCP 工具可以做项目感知的行为差异——比如同一个 code-review MCP Server,在不同项目里自动读取不同的 lint 规则配置。
claude plugin details
claude plugin details <plugin-name>
这个命令现在会输出插件的组件清单和预估的每次会话 token 成本。
做过成本管控的人看到这个会觉得实用。当你给 Claude Code 装了一堆插件,context 窗口里其实塞了大量的 plugin prompt。知道每个插件的 token 开销,可以帮你做「哪些插件真的用到了、哪些在白白消耗 quota」的决策。
在 Agent 视图的多会话场景下,每个后台会话都独立消耗配额,这个成本意识就更重要了。
/context all 的分词器感知
/context all 命令的 token 估算现在会根据具体模型的分词器计算,而不是用通用近似值。
这个改动背后是一个工程精度问题:Claude 系列的不同模型使用的 tokenizer 略有差异,同一段文本在不同模型下的 token 数可能相差 10-15%。当你在做「这段上下文还塞得下吗」的判断时,精确的 token 计数很重要——差 15% 可能就是「刚好够」和「触发 compaction」的区别。
在多会话的场景下这个问题被放大了:你同时开了 4 个后台会话,每个都在消耗上下文窗口,不准确的估算可能让你误判整体的 token 压力。而且 /context all 显示的舍入值现在也更诚实——它会告诉你这是基于模型分词器计算的近似值,而不是给你一个看似精确实则靠猜的数字。
踩坑记录:多会话并行的配额问题
用 Agent 视图跑了一周,有几个坑值得提前说。
配额消耗是乘法不是加法。 后台会话和交互式会话共享 Claude Pro/Max 的配额。你同时跑 5 个后台任务,配额消耗速度是大约 5 倍。我用 Max 计划,跑了 8 个并行任务跑了半天,配额吃了约 60%。开多少会话之前,先 /usage 看一眼剩余额度。
机器睡眠会中断后台会话。 官方文档明确说了这一点,但很容易被忽视。Mac 合盖后,后台会话全部暂停。重新开盖后状态保留,但任务不会自动恢复——需要手动 claude respawn --all。如果你打算让 Claude 通宵跑任务,记得调整系统的「防止睡眠」设置。
worktree 要记得清理。 每个后台会话默认在 .claude/worktrees/ 下创建独立 worktree,会话删除后 worktree 也会删除。但如果会话异常终止,worktree 可能遗留。git worktree list 查一下,git worktree remove <path> 清掉。磁盘上攒了一堆孤儿 worktree 挺难看的。
/goal 要搭配明确的验证命令。 前面提过了,再强调一次。「帮我把 bug 修掉」这种描述不适合 /goal——Claude 可能在第一 turn 就自认为修好了然后停下来。配上「curl 返回 200 且内容包含 success」这种可以机器验证的条件,可靠性会高很多。
总结
从「你说我做」到「你给目标我自己搞定」,这两个字的差距背后是完全不同的系统设计。/goal 命令不是在 Claude Code 里加了个方便的快捷方式,而是引入了「目标状态收敛」这个执行模型——这个模型在分布式系统里早就被验证过了,现在被用到了 AI Agent 工具里。
我觉得这才是 v2.1.139 真正值得关注的地方,比那 30+ 个 bug fix 更有意思。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号