贝叶斯学习中的线性响应入门

贝叶斯学习中的线性响应入门

CreateAMind
发布于 2026-05-19 10:49:22
发布于 2026-05-19 10:49:22
敏感性及其模式化:贝叶斯学习中线性响应入门
Susceptibilities and Patterning: A Primer on Linear Response in
Bayesian Learning
https://arxiv.org/pdf/2605.07980


摘要

1 引言
将统计建模应用于两个先验上截然不同的领域之间存在着一种系统性的类比:物理系统的统计力学,以及机器学习模型训练的分析。本笔记旨在使这种类比显式化,并推导其对于一种理论根基深厚的可解释性方法的后果。

我们主要的兴趣在于将前一种设定(统计力学)中的思想应用于后一种设定(机器学习)中的问题。具体而言,我们要关注敏感性(susceptibilities):即后验期望值关于数据分布扰动的导数。它们是统计力学中热力学敏感性的直接类比,我们要论证的是,它们为解读训练模型的内部结构提供了一种系统且可计算的工具。
我们设计这些笔记旨在引起这两个领域从业者的兴趣。
- 我们希望物理学家能在贝叶斯学习中认出熟悉的热力学结构——构型空间、能量函数、玻尔兹曼分布以及自然的扰动概念——并在学习理论设定中发现一类新颖的系统,他们熟悉的技术在其中惊人地适用。
- 对于机器学习科学家和从业者,尤其是那些对可解释性感兴趣的人,我们要解释为什么研究贝叶斯后验期望值的变化是一种解读训练模型内部结构的有原则的工具,它们如何联系并扩展了诸如影响函数(influence functions)和训练数据归因(training data attribution)等现有思想,以及奇异学习理论(singular learning theory)如何弥合总体层面定义与实际计算的经验估计量之间的差距。
1.1 下文结构
我们要组织材料,以便不同背景的读者能找到高效的路径。第 2 节发展了统计力学框架,并在 §2.7 中通过与机器学习的类比达到高潮;已经熟悉伊辛模型(Ising model)和涨落-耗散定理(fluctuation-dissipation theorem)的物理学家可能希望略过前面的小节,从那里开始阅读。机器学习读者,特别是那些尚未被说服认为后验协方差是值得研究的合理对象的人,应该花时间仔细研读 §2.5–2.6 中的伊辛实验:这些内容旨在建立一种直觉,即敏感性通过外部探测来探查内部结构。
其余部分在机器学习设定下发展该理论:§3.1–3 阐述了设定,定义了敏感性,并在该设定下建立了涨落-耗散定理;§4 通过拉普拉斯近似(Laplace approximation)发展了敏感性的几何内容;§5 将敏感性矩阵构建为切映射(tangent map),并将模式形成(patterning)发展为逆问题;§6 解决了从总体层面理论到实践中使用的经验估计量的过渡问题。最后一节主要供那些希望理解前述材料是否以及如何能够实际实现的读者参考。
2 系统、构型与可观测量
敏感性理论根植于统计力学与凝聚态物理。在专门聚焦于机器学习中的统计模型之前,理解这些渊源是值得的。这不仅将为如何思考敏感性提供宝贵的直觉,而且事实上,物理学中使用的许多方法可以直接、无需修改地转化到机器学习设定中。
2.1 构型与玻尔兹曼分布


2.2 可观测量与期望值


期望值是研究的标准量:它们是充分的(对于足够丰富的一类可观测量,它们决定了玻尔兹曼分布),并且它们能探测结构(不同的可观测量揭示系统的不同方面)。
注 3.这一视角由 Callen [13] 在其热力学教科书的开篇章节中阐述得尤为清晰。Callen 的出发点是关于物理学中实际可观测内容的观察。系统的微观状态——即

个粒子的精确构型,或每个晶格位点的确切自旋——快速且混沌地涨落。我们在实验室实际测量的是稳定的量:即在空间区域和时间间隔上的平均值,这些区域和间隔与微观尺度相比很大,但与感兴趣的宏观尺度相比很小。温度、压强、磁化强度;所有这些都是平均值。在 Callen 的论述中,热力学的主题始于认识到这些平均量服从其自身的规律,独立于那些已被平均掉的微观细节。
2.3 伊辛模型中的期望值

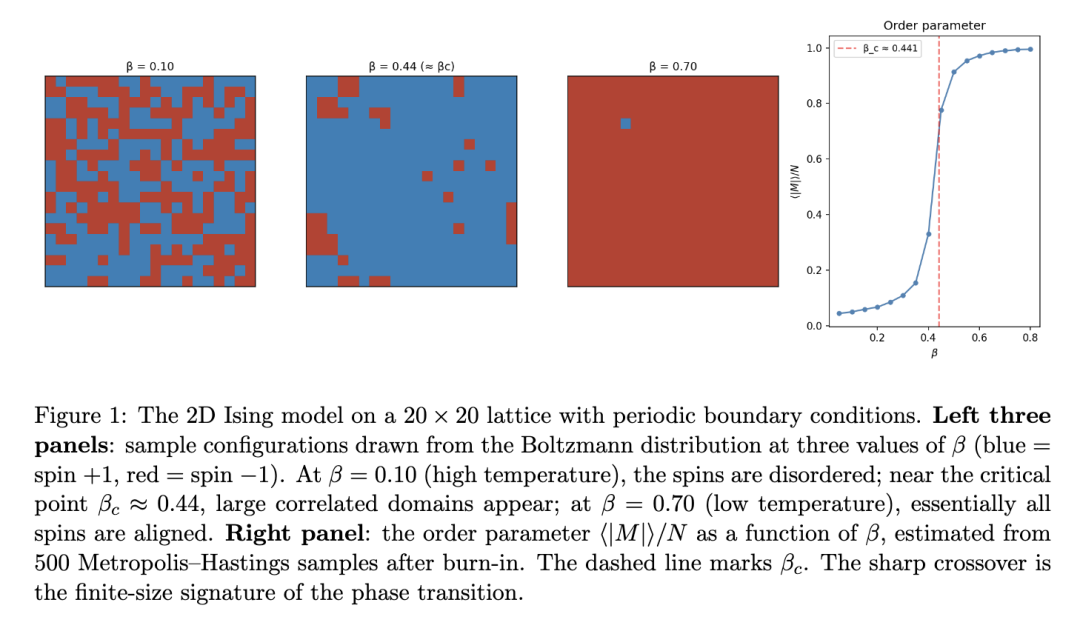
这个例子阐明了一种普遍模式:通过追踪单个可观测量(磁化强度)作为参数(β)的函数的期望值,我们能够在无需检查单个自旋构型的情况下,探测到系统内部组织从无序到有序的定性变化。模型表现出相变这一事实并非单个构型的属性,而是被视为参数 β 的函数的玻尔兹曼分布的属性。
2.4 扰动与敏感性


在统计物理中,敏感性(susceptibility)是探测多体系统内部结构的主要工具,这类系统的微观自由度无法被直接检查。人们通过外部源(例如施加的磁场或温度的变化)可控地扰动系统,并测量宏观可观测量的响应。响应的形式是系统内部组织的一个窗口。例如,我们刚才看到伊辛模型的磁敏感性——即磁化强度对均匀外场的响应——在临界温度处发散,标志着长程序的开始;而比热(specific heat)编码了低能激发的谱。通过研究不同的可观测量和扰动,我们可以获知更丰富的信息,正如我们现在将要展示的那样。
2.5 示例:测量系统各部分之间的耦合
为了使“敏感性作为可解释性工具”这一思想具体化,我们要回到伊辛模型并提出问题:仅通过测量协方差,我们能检测出给定自旋属于晶格的哪一部分吗? 我们将表明,答案不仅是理论上的肯定,而且在经验上也是肯定的。有关包含图示的更详细说明,请参见 [5]。

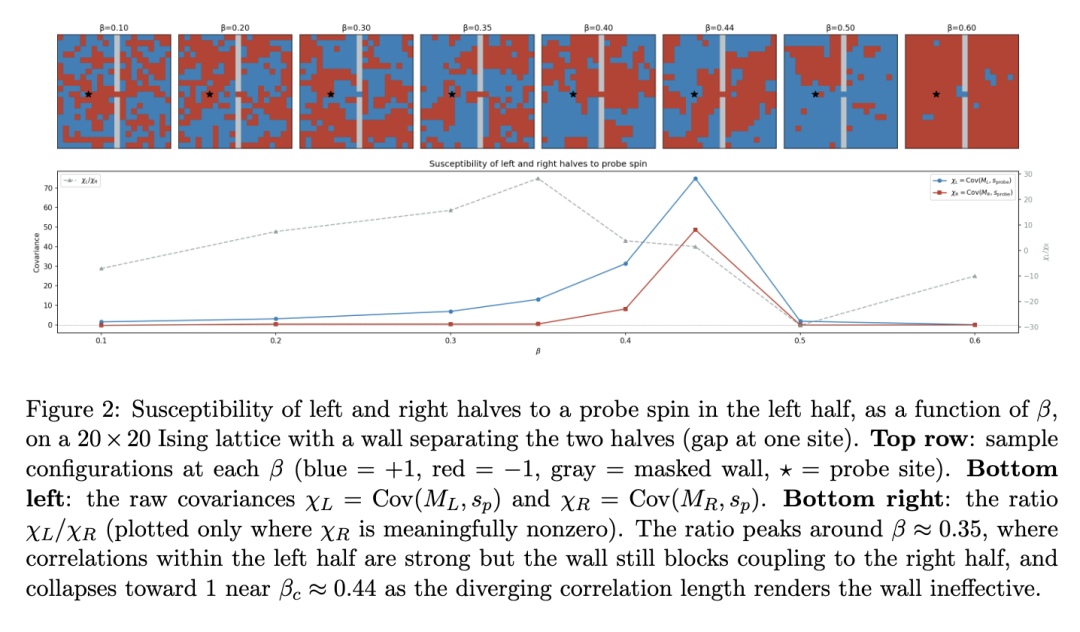



该实验阐明了敏感性在神经网络设定中将扮演的核心思想:局部化探测与区域可观测值之间的协方差能够检测探测与该区域之间的耦合。当系统具有结构(壁)时,这种耦合在不同区域之间有所不同,而敏感性揭示了探测属于哪个区域——无需直接检查晶格几何结构。
2.6 示例:响应矩阵
我们可以通过同时考虑多个探测和多个区域,将这一思想进一步推进,将成对协方差组装成一个响应矩阵。
设置。 我们使用一个具有边界壁的 20×20晶格(所有边缘位点被掩蔽,消除周期性环绕效应)和一个单一内部壁:第 10 行的一水平条带被掩蔽,跨越晶格的右半部分(第 10–18 列)。这将晶格分为三个区域(图 3,左图):
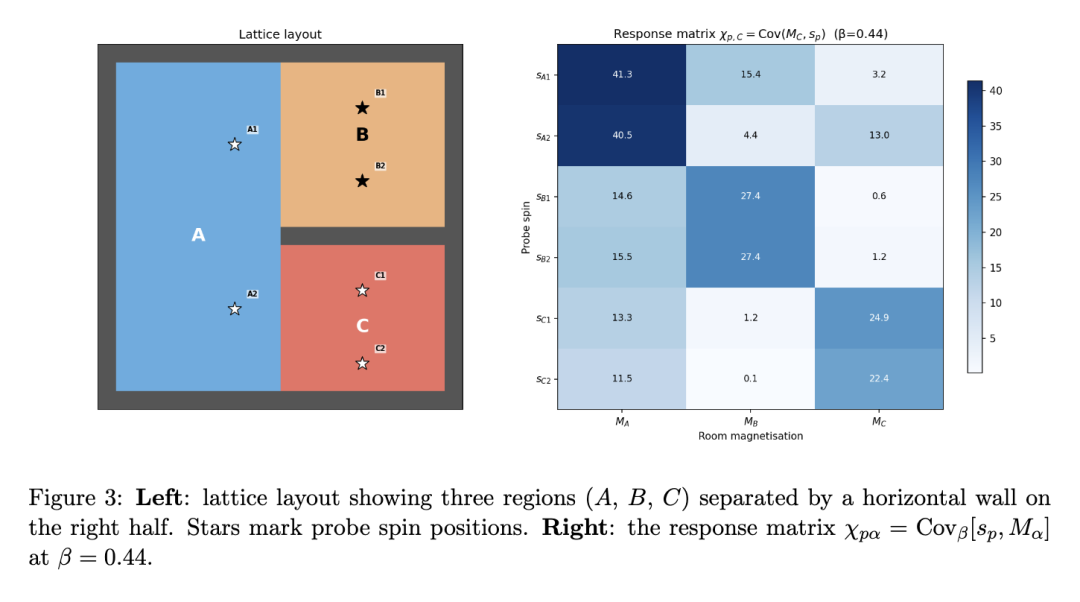
- 区域 A(蓝色):左半部分,第 1–9 列,所有行。该区域是开放的——它没有内部壁,并与 B 和 C 共享无障碍边界。
- 区域 B(橙色):右上部分,第 10–18 列,第 1–9 行。
- 区域 C(红色):右下部分,第 10–18 列,第 11–18 行。
区域 B 和 C 被壁分隔且没有直接耦合:B 中的自旋与 C 中的自旋永远不是最近邻。B 和 C 之间的任何相互作用必须通过 A 来介导,而 A 对两者都是开放的。

结果。 在图 3中,我们展示了在 β=0.44(接近临界温度,此时相关性为长程的)下,通过 20,000 个 Metropolis–Hastings 样本计算得到的响应矩阵。该矩阵具有清晰的块状结构,反映了晶格几何:

响应矩阵仅凭协方差测量便恢复了内部几何结构:三个区域,其中两个被屏障分隔,第三个在二者之间起介导作用。A 探测之间的不对称性不仅揭示了区域划分结构,还揭示了空间布局。这是神经网络中敏感性的原型,在此框架下,“区域”转化为模型组件,“探测”转化为数据点,而响应矩阵则成为文献 [2] 中的结构性敏感性矩阵。
2.7 从物理学走向神经网络
结构推断研究框架 [1, 2, 3, 4] 将这一框架应用于神经网络。其类比关系如下:
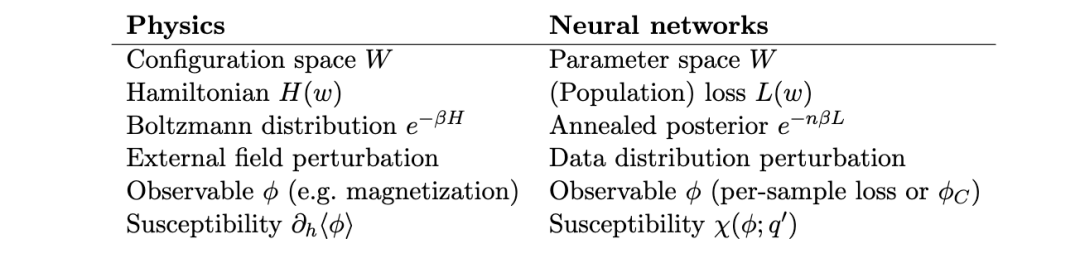
在文献 [2] 中,定义了敏感性并将其用于识别小型 Transformer 模型中注意力头的作用:即哪些头负责数据中的哪些模式。在文献 [4] 中,对逐词元(per-token)敏感性向量进行聚类,得到了数百个可解释的组——即模型的“谱线”——并且一个分解定理表明,这些聚类源于数据分布的模式结构。模式形成方案 [8] 逆转了这一框架:给定期望的内部结构变化,它利用敏感性矩阵的伪逆来计算最优的数据扰动。
3 机器学习中的敏感性
我们现在将统计物理背景下引入的一般框架专门化,应用于神经网络等机器学习模型的设定中。敏感性衡量模型对数据分布扰动的一阶响应。该一般定义适用于任何可观测量;不同的可观测量选择会产生影响矩阵和结构性敏感性矩阵。
3.1 设定与符号



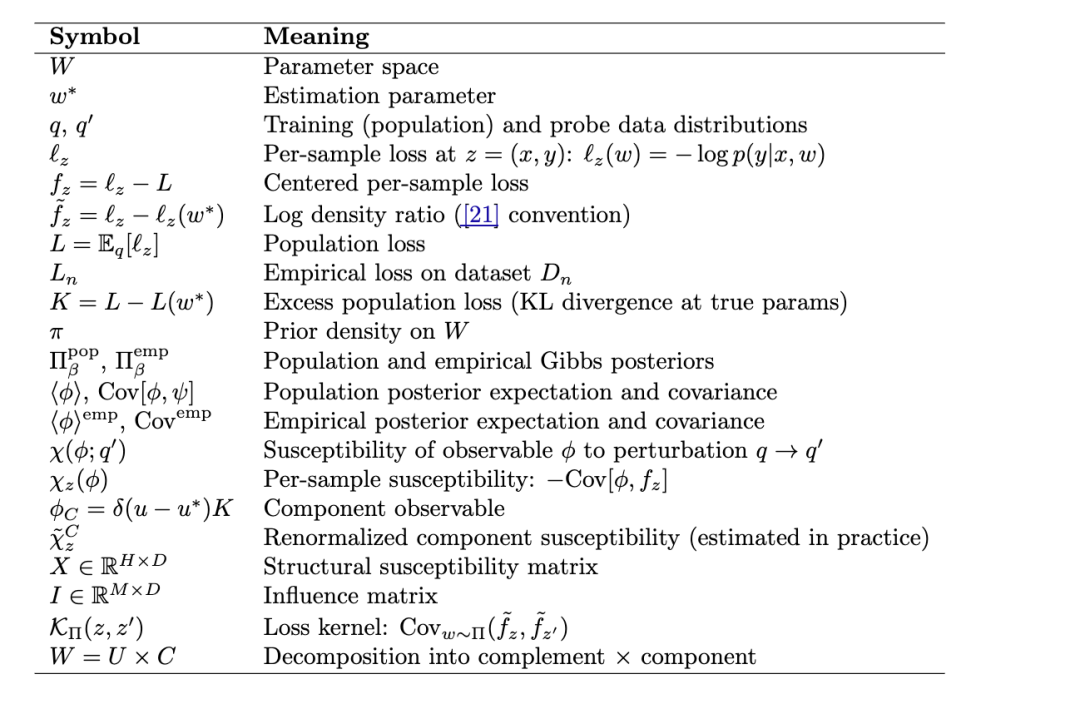
3.2 数据扰动



这一恒等式在贝叶斯统计学中有着悠久的历史,与其在统计物理学中的发展并行:它以 Gustafson [28] 的局部案例敏感性(local case sensitivity)形式出现,出现在变分贝叶斯文献 [23, 24, 25] 中,并在神经网络设定中作为 [20] 的贝叶斯影响函数(Bayesian influence function)出现。我们要在此处针对一般扰动和分布可观测量所采用的表述形式来自 [2]。
协方差形式 (7) 正是使得敏感性可计算的原因:它可以通过用
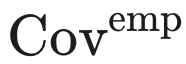
替换 Cov,然后使用蒙特卡洛方法从近似经验后验的分布中采样来估计。我们在第 6 节讨论用经验协方差替换总体协方差的问题,并在第 6.4 节讨论采样过程。
3.4 逐样本敏感性与密度解释



3.5 可观测量的示例
敏感性是针对任何广义可观测量 ϕϕ 定义的;ϕϕ 的选择决定了我们要探测模型的哪个方面。在本节中,我们要描述三类尤为自然地产生的可观测量,并且针对其中的两类——逐样本损失(per-sample losses)和分量局部化损失(component-localized losses)——我们要介绍通过将可观测量族与一组逐样本扰动配对而获得的关联敏感性矩阵(susceptibility matrix)。

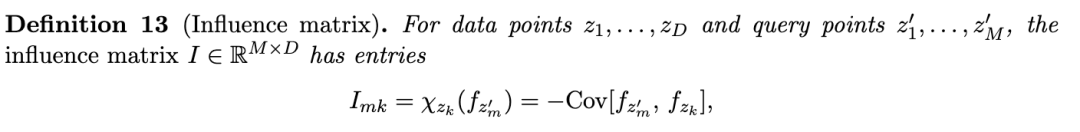

分量可观测量。 为了探测模型的特定分量 CC,我们要使用总体损失的一个类比,该损失仅沿该分量变化。

4 敏感性探测几何 (Susceptibilities probe geometry)


4.1 正则情形 (The regular case)



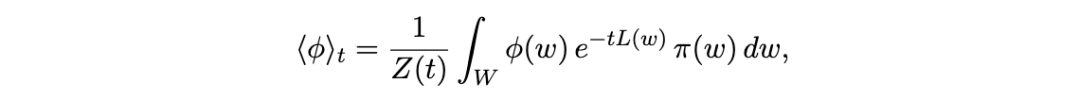


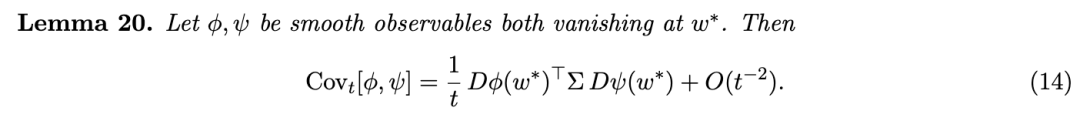



直接计算影响函数需要对 H 求逆,但将敏感性表达为协方差则不需要——这一点我们将在 4.2 节中回过头来讨论,即当 H 退化时的情形。
人们应该从这个计算中得出与之前相同的思想:为了通过敏感性探测 L 的局部几何,需要对可观测量 ϕ 的主导泰勒系数施加消失条件。

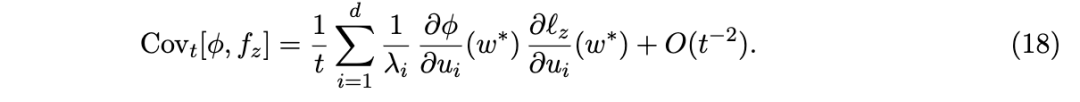

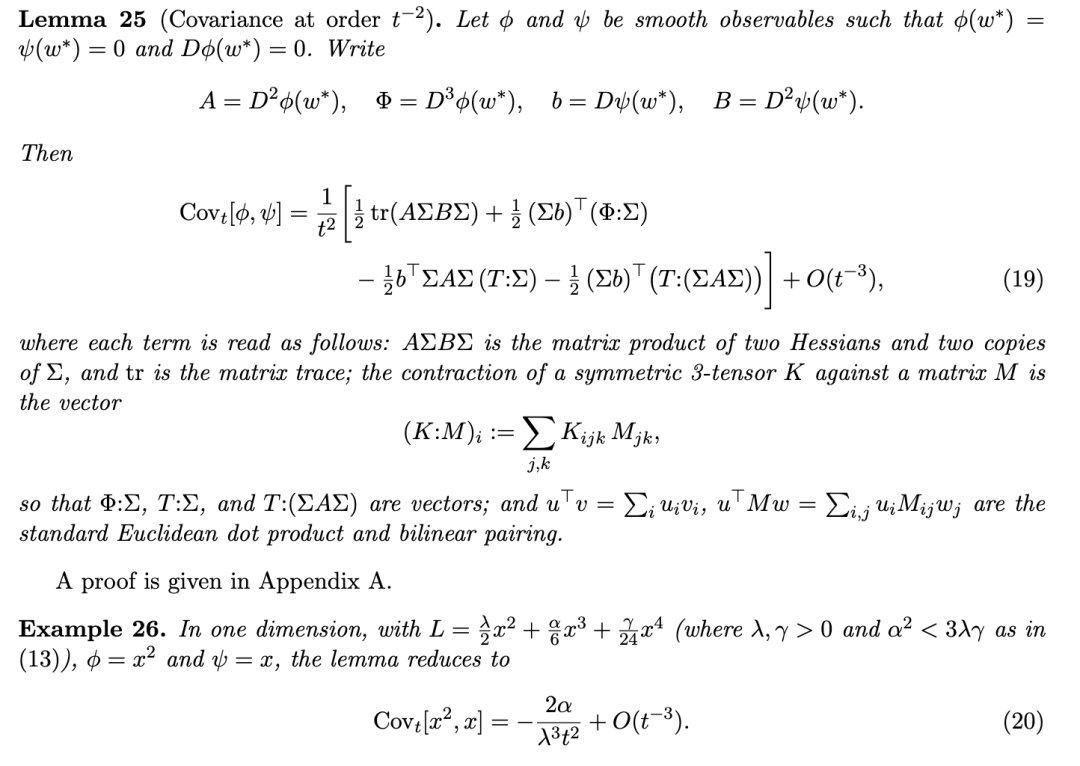
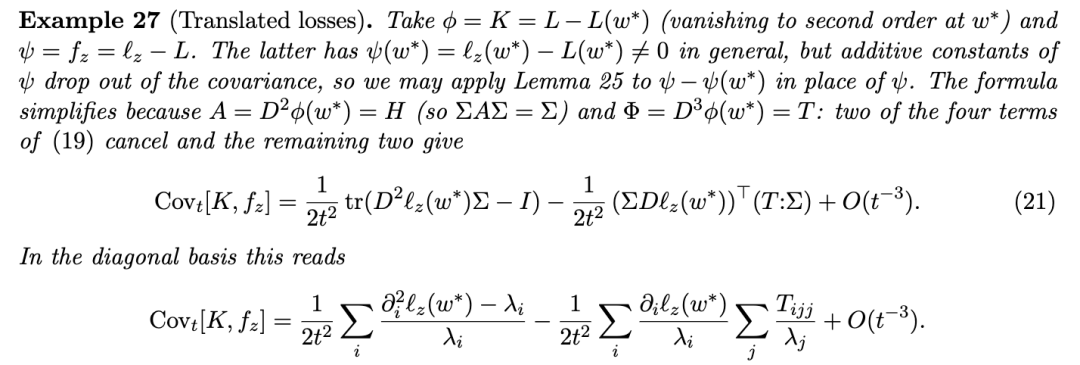


4.2 奇异情形

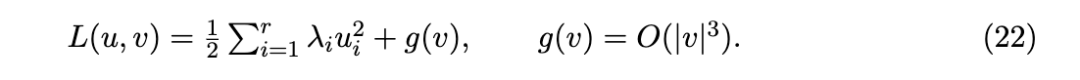







5 敏感性与模式化
前几节将敏感性发展为解读模型内部结构的工具:给定一个训练好的网络和一个数据分布,敏感性矩阵编码了哪些可观测量响应哪些数据模式。模式化(patterning)程序 [8] 将这一过程逆转:给定期望的结构坐标变化,人们希望找到能实现它的数据分布。本节通过切空间之间的单一映射,将正向问题(可解释性)和逆向问题(模式化)统一在同一个框架下。
5.1 结构坐标映射

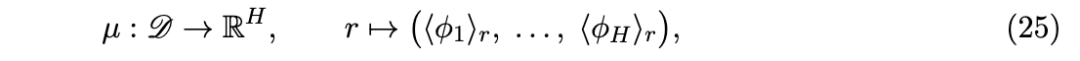

5.2 正向问题:可解释性


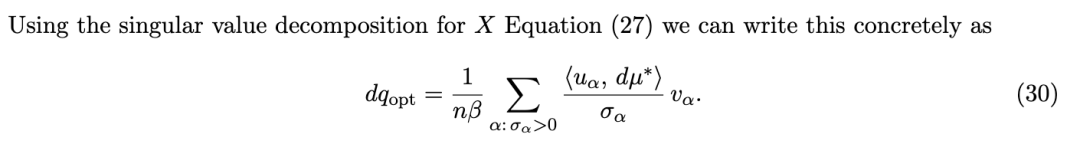

6 实践中的敏感性
本节探讨为神经网络计算敏感性的实际方面,正如在 [2, 4] 中所实现的那样。我们详细探讨从总体层面定义过渡到实践中计算的数值所涉及的三个近似:从总体到经验后验,对于分量可观测量从完整后验到权重受限后验,以及从精确后验期望到 SGLD 样本。
6.1 在总体层面定义敏感性



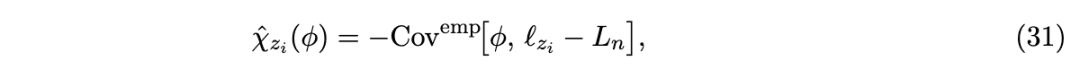



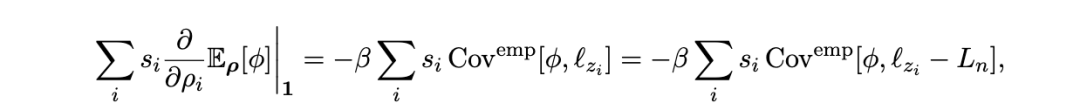


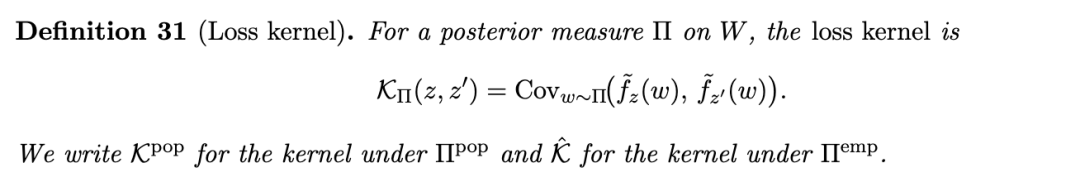

6.3 实践中的分量可观测量
6.3.1 权重限制与重归一化间隙




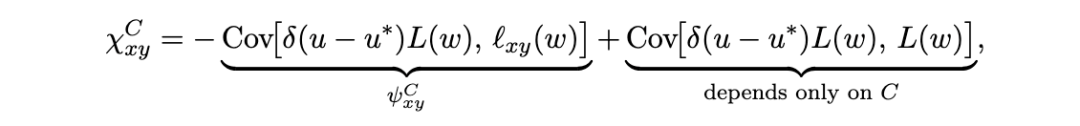

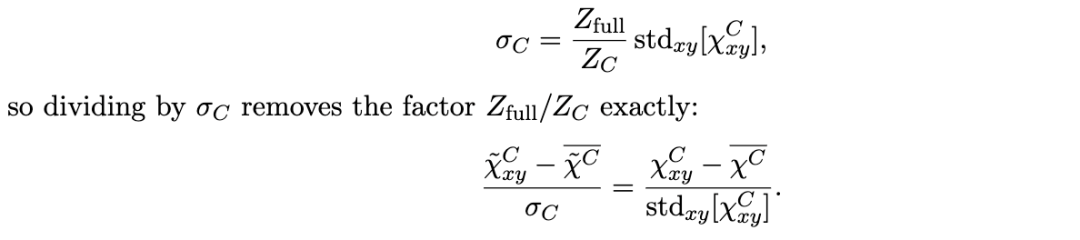
6.4 SGLD 估计
敏感性中出现的后验期望是通过随机梯度朗之万动力学(Stochastic Gradient Langevin Dynamics, SGLD)[18] 来估计的。对于每个分量 CC,一个权重受限的 SGLD 链在钳制(clamping)
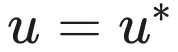
的同时对分量参数 v 进行采样:
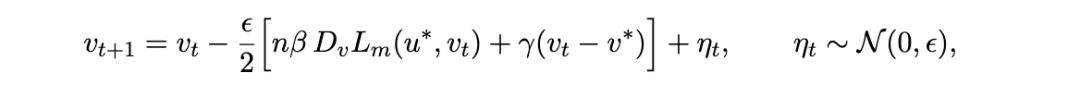

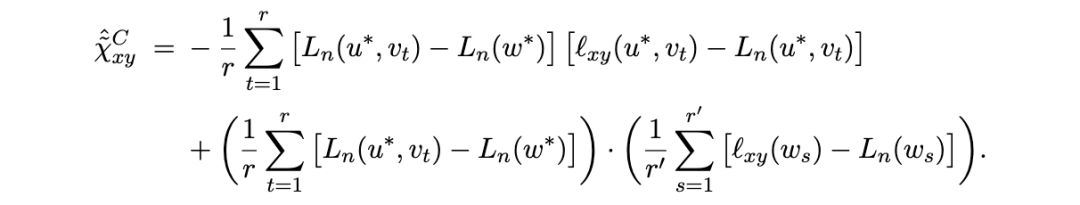
这是混合协方差 (34) 的经验版本:第一个求和遍历受限链(分量受限样本),而第二个乘积中的全局基线项使用完整链。
6.5 实践中的模式化


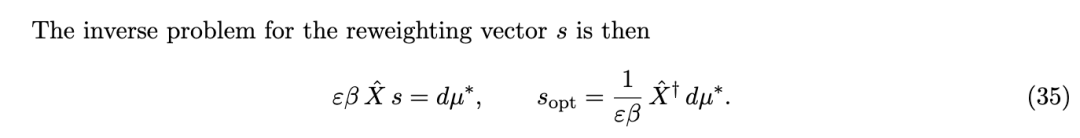



自然的修复方法是用岭正则化逆(ridge-regularized inverse)代替伪逆
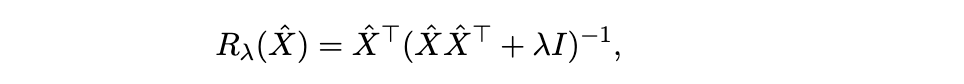

7 结论

该理论已在几个方向上得到应用:[2] 利用结构敏感性矩阵识别小型 Transformer 中注意力头的作用,[3] 在训练过程中追踪它以研究发育轨迹,而 [4] 对行进行聚类以发现可解释的 token 组。模式化(patterning)程序 [8] 逆转了这一框架:给定期望的结构坐标变化,它通过敏感性矩阵的伪逆计算最优数据扰动。
原文链接:https://arxiv.org/pdf/2605.07980
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号