Elasticsearch 向量索引速度提升 12 倍:在 GPU 和 CPU 层部署 NVIDIA cuVS

Elasticsearch 向量索引速度提升 12 倍:在 GPU 和 CPU 层部署 NVIDIA cuVS

点火三周
发布于 2026-05-21 21:06:43
发布于 2026-05-21 21:06:43
Elasticsearch 向量索引速度提升 12 倍:在 GPU 和 CPU 层部署 NVIDIA cuVS
NVIDIA cuVS 在 GPU 上构建 HNSW 图,使 Elasticsearch 中的向量索引速度最高提升 12 倍。本文将介绍两种生产部署模式:模式 A 在同一 GPU 节点上同时进行构建和提供服务,适用于数据节点少于五个的集群。模式 B 使用三个轻量级 GPU 摄入节点(每个 64 GB RAM),通过 ILM 滚动策略将分片移交到七个 CPU 热服务节点(每个 192 GB)——这是大规模生产环境的默认推荐方案。文中包含了针对 3 亿向量语料库的完整索引模板、ILM 策略和规模计算。
Elasticsearch cuVS GPU 插件实际作用是什么?
Elasticsearch cuVS GPU 插件在两个操作期间接管 HNSW 图的构建:段刷新(segment flush)和强制合并(force merge)。该插件要求数据节点连接受支持的 NVIDIA GPU,安装 cuVS 插件,并在 elasticsearch.yml 中设置 vectors.indexing.use_gpu: true。
- 1. 段刷新 向量在 JVM 写入缓冲区中累积。在刷新时,插件会批量处理这些向量,通过 PCIe 将它们复制到 GPU VRAM,在 VRAM 中构建一个 CAGRA 图,将其转换为 HNSW 格式,通过 PCIe 将结果复制回系统 RAM,然后 Lucene 将段文件写入本地 NVMe。随后,该段会被内存映射到操作系统页缓存中以供查询服务。
- 2. 强制合并 当段进行合并时,相同的 GPU 路径会加速图的重建,根据已发布的基准测试,强制合并时间大约加快 7 倍。
所有其他操作(HTTP 请求处理、查询服务、集群状态管理、ILM 执行)都在 CPU 上运行并使用系统 RAM。GPU 是两个写入路径操作的协处理器,而非主机计算环境的替代品。
将 GPU 构建与 CPU 查询服务分离非常重要,因为连接 GPU 的节点不一定需要作为查询服务层。它们可以专用于写入路径,并将构建好的分片移交给更经济的 CPU 热服务节点。这就是模式 B 背后的核心理念。
模式 A:在单个 Elasticsearch 节点中结合 GPU 构建与服务
模式 A 是一种更简单的部署方式。每个 GPU 节点既构建分片,又服务于这些分片上的查询。cuVS 的基准测试就是这样运行的:单个 g6.4xlarge 实例(64 GB RAM,1x NVIDIA L4)在一个 Elasticsearch 进程上运行索引。该节点能够同时进行索引和搜索,尽管已发布的基准测试专门测量了索引吞吐量。
何时使用组合型 GPU 节点(模式 A)
- • 小型集群(少于 5 个数据节点)。
- • 概念验证 (POC) 或边缘部署,其中操作简便性优先于成本优化。
- • 语料库足够小,使得完整的 HNSW 图能够与正常操作一起容纳在每个节点的页缓存中。
节点配置(模式 A)
每个数据节点都将获得一个 GPU,并使用相同的 elasticsearch.yml 配置:
1
2
3
4
5
6
7
8
9
# elasticsearch.yml: 模式 A (组合型 GPU + 服务节点)
node.roles: [data_hot, data_content]
# auto (默认): 在可用时使用 GPU。true: 如果 GPU 不可用则启动失败。
# 在专用 GPU 节点上使用 true 以在启动时捕获配置错误。
vectors.indexing.use_gpu: true
# JVM 堆内存: 最大约 32 GB (压缩 OOPs 边界)
# 剩余系统 RAM 用于 OS 页缓存以存储 HNSW 图
没有分片路由技巧,也没有 ILM 层级分离。分片会落在 Elasticsearch 默认分配器指定的位置,并且每个节点都可以同时进行构建和提供服务。
注意:还有一个索引级别的设置 index.vectors.indexing.use_gpu,可以在每个索引的基础上覆盖节点级别的默认值。有效值包括 auto(默认值,在可用时使用 GPU)、true(需要 GPU,如果不可用则失败)和 false(禁用此索引的 GPU)。
规模计算影响
由于每个节点都持有长期存在的分片,因此它需要足够的系统 RAM 来满足以下需求:
- • JVM 堆内存(约 32 GB)
- • 存储其语料库 HNSW 图部分的操作系统页缓存
- • 操作系统和 CUDA 开销(约 10-15 GB)
对于一个包含 3 亿 int8 向量、具有高可用性(两份副本)的语料库,10 个数据节点中的每个节点将在页缓存中存储约 65 GB 的 HNSW 数据。加上 JVM 和开销,每个节点大约需要 128–192 GB 的系统 RAM。这比 64 GB 的参考基准测试要多得多,因为该基准测试在单个节点上仅存储了 260 万向量。
每个节点的系统 RAM 大小与每个节点的分片数量成比例,而不是与总语料库大小成比例。节点越多,每个节点的 RAM 可以越少;节点越少,每个节点的 RAM 需要越多。这是一种操作复杂性与硬件成本之间的权衡。
关于已发布基准测试的说明。 大约 12 倍的索引吞吐量和 7 倍的强制合并速度是在单个 g6.4xlarge 节点上,使用 260 万个 1,536 维的 float32 hnsw 向量测量得出的。本文的示例使用 1,024 维的 int8_hnsw。性能特征可能因不同的维度计数和量化级别而异,因此请为您的生产规模基准测试自己的语料库。
模式 B:专用 GPU 摄入节点与 ILM 分片移交到 CPU
模式 B 将集群划分为两个具有不同硬件配置和不同角色的数据层:
- • GPU 摄入层。 少量节点,配备 NVIDIA GPU 和适度的系统 RAM(64 GB)。这些节点接受写入,通过 cuVS 在 GPU 上构建 HNSW 段,并拥有活动的写入分片。
- • CPU 热服务层。 大量节点,不带 GPU,但系统 RAM 较大(192 GB)。这些节点通过 ILM 滚动策略从 GPU 摄入层接收迁移的分片,并处理所有查询流量。
一旦分片滚动并迁移到 CPU 热服务层,GPU 摄入节点就不再拥有它。GPU 摄入节点的页缓存占用空间保持很小,因为它只持有当前正在写入的索引。
何时使用 GPU 摄入 + CPU 服务(模式 B)
- • 拥有 5 个以上数据节点的生产集群,其中 ILM 滚动策略已是操作流程的一部分。
- • 当连接 GPU 的硬件昂贵时,您希望最大程度地减少需要 GPU 的节点数量。
- • 当查询服务工作负载受益于与 GPU 构建操作不共享的专用 CPU 和 RAM 时。
- • 当 ILM 已是操作模型的一部分时(对于任何时间序列或生命周期管理的向量语料库都应如此)。
节点配置(模式 B)
GPU 摄入节点(elasticsearch.yml):
1
2
3
4
5
# GPU 摄入节点:构建分片,不长期提供查询服务
node.roles: [data_hot]
node.attr.tier_function: gpu_ingest
vectors.indexing.use_gpu: true
CPU 热服务节点(elasticsearch.yml):
1
2
3
# CPU 热服务节点:接收迁移的分片,提供查询服务
node.roles: [data_hot]
node.attr.tier_function: cpu_serve
两种节点类型都共享 data_hot 角色,因为它们参与相同的逻辑层。自定义属性 node.attr.tier_function 让我们能够控制哪些节点接收新的写入,哪些节点接收迁移的分片。
索引模板:将新写入路由到 GPU 节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
PUT _index_template/vectors-template
{
"index_patterns": ["vectors-*"],
"template": {
"settings": {
"index.routing.allocation.require.tier_function": "gpu_ingest",
"index.lifecycle.name": "vectors-lifecycle",
"index.lifecycle.rollover_alias": "vectors-active"
},
"mappings": {
"properties": {
"embedding": {
"type": "dense_vector",
"dims": 1024,
"index": true,
"index_options": {
"type": "int8_hnsw"
}
}
}
}
}
}
匹配 vectors-* 的新索引将专门分配给 tier_function: gpu_ingest 的节点。写入流向 GPU 摄入节点,cuVS 在 GPU 上构建 HNSW 图。
关键:您必须明确设置 index_options.type 为 int8_hnsw(或 hnsw)才能启用 GPU 加速。 在 Elasticsearch 9.1 及更高版本中,维度大于等于 384 的 dense_vector 字段默认使用 bbq_hnsw,而 cuVS 不支持此类型。如果您在没有指定 int8_hnsw 的情况下在此模板之外创建向量字段,GPU 插件将回退到 CPU 进行索引。上述模板已正确设置,但集群中每个需要从 cuVS 中受益的向量字段都需要此明确设置。
ILM 策略:滚动并迁移到 CPU 服务节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
PUT _ilm/policy/vectors-lifecycle
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "7d",
"max_primary_shard_size": "50gb"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "0ms",
"actions": {
"migrate": {
"enabled": false
},
"allocate": {
"require": {
"tier_function": "cpu_serve"
}
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "180d",
"actions": {
"migrate": {
"enabled": false
},
"allocate": {
"require": {
"tier_function": "cpu_serve"
}
}
}
},
"delete": {
"min_age": "730d",
"actions": {
"delete": {}
}
}
}
}
}
此策略中有几点需要注意。
在 warm 和 cold 阶段中的 "migrate": {"enabled": false} 非常重要。warm 阶段的 migrate 操作通常会尝试将 _tier_preference 设置为 data_warm,但由于此架构中没有节点具有 data_warm 角色,分片可能会变得无法分配。禁用 migrate 并使用带有自定义 tier_function 属性的显式 allocate 操作,使我们能够精确控制分片的位置。
warm 阶段的 min_age: "0ms" 意味着迁移在滚动后立即发生,而不是在时间延迟之后。这是有意的:我们希望分片在滚动后几分钟内就从 GPU 摄入节点上移走,以保持 GPU 摄入层轻量化。
替代方法:如果“warm”(ILM 阶段名称)和“hot serving”(CPU 节点实际执行的操作)之间的命名混淆对您的团队造成困扰,您可以改为将 GPU 摄入节点分配 node.roles: [data_hot],将 CPU 热服务节点分配 node.roles: [data_warm],然后让 ILM 的标准层迁移处理移动,而无需自定义属性。这种权衡的优点是 ILM 更简单,但可能语义上会引起混淆:您最繁忙的查询服务节点被标记为“warm”。
为什么 64 GB 系统 RAM 对于 GPU 摄入节点就足够了
在模式 B 下,GPU 摄入节点仅持有以下内容(近似值,基于标准 Elasticsearch JVM 规模计算指南和观察到的 CUDA 运行时开销):
消费者 | 大致 RAM 占用 |
|---|---|
JVM 堆内存 | ~32 GB |
CUDA 驱动 + 固定的 PCIe 缓冲区 | ~10 GB |
活动写入分片的页缓存 | ~10-15 GB |
操作系统和容器开销 | ~5 GB |
总计 | ~60 GB |
这与已发布的 cuVS 基准测试硬件配置相符:AWS g6.4xlarge,配备 64 GB RAM。GPU 摄入节点不需要持有整个语料库的累积 HNSW 图,只需持有当前正在写入的索引,该索引会以短周期进行滚动。
相比之下,CPU 热服务节点持有页缓存中的累积语料库,根据每个节点的分片数量,需要 128-192 GB。
规模计算总结(模式 B,3 亿向量,int8_hnsw,高可用性)
节点类型 | 数量 | 系统 RAM | GPU | 角色 |
|---|---|---|---|---|
GPU 摄入 | 3 | 64 GB | 1x L40S (48 GB VRAM) | 构建分片,cuVS |
CPU 热服务 | 7 | 192 GB | 无 | 服务查询,在页缓存中存储 HNSW |
Warm/Cold (BBQ) | 5 | 64 GB | 无 | 老化数据,约 8 倍压缩 |
主节点 | 3 | 16 GB | 无 | 集群仲裁 |
协调节点 + Kibana | 4 | 32–64 GB | 无 | 查询路由,UI |
在 ECK 下的总 ERU (Elastic Resource Unit):约 32。
模式 B 端到端的数据流转
在模式 B 中,向量从客户端流向 GPU 摄入节点,cuVS 在 GPU 上构建 HNSW 段,然后 ILM 将完成的分片迁移到 CPU 热服务节点。下面的序列图显示了一批向量的往返过程,以及将完成的分片移动到服务层的滚动过程:
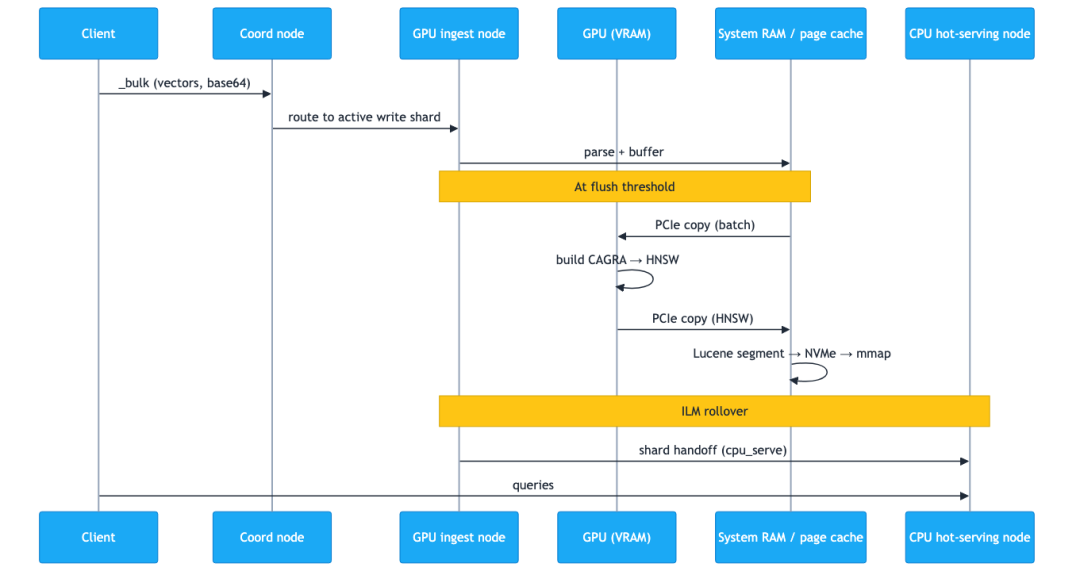
Elasticsearch GPU 摄入到 CPU 服务流程的序列图:向量通过批量请求到达,在 GPU VRAM 上通过 CAGRA 处理以构建 HNSW 图,写入系统 RAM 和 NVMe,然后在 ILM 滚动后移交给 CPU 热服务节点。
Elasticsearch GPU 摄入到 CPU 服务流程的序列图:向量通过批量请求到达,在 GPU VRAM 上通过 CAGRA 处理以构建 HNSW 图,写入系统 RAM 和 NVMe,然后在 ILM 滚动后移交给 CPU 热服务节点。
以步骤形式说明:
- 1. 客户端发送一个
_bulk请求,其中包含编码为 base64 字符串的向量(推荐用于提高吞吐量)。 - 2. 协调节点将请求路由到拥有活动写入分片的 GPU 摄入节点。
- 3. GPU 摄入节点的 JVM 解析请求,并将向量排队到写入缓冲区中。
- 4. 达到刷新阈值时,cuVS 插件批量处理向量,并通过 PCIe 将它们从系统 RAM 复制到 GPU VRAM。
- 5. GPU 在 VRAM 中构建一个 CAGRA 图,并将其转换为 HNSW 格式。
- 6. HNSW 数据通过 PCIe 复制回系统 RAM。
- 7. Lucene 将段文件从系统 RAM 写入本地 NVMe。
- 8. 该段被内存映射到操作系统页缓存(系统 RAM)中,现在可以进行查询。
- 9. 在达到配置的滚动阈值(时间或大小)后,ILM 会滚动索引,并在 GPU 摄入层上创建一个新的写入索引。
- 10. 已滚动索引的分配要求从
gpu_ingest变为cpu_serve,Elasticsearch 的分片分配器通过网络将分片迁移到 CPU 热服务节点。 - 11. CPU 热服务节点将接收到的段内存映射到其页缓存中,并开始服务查询。
- 12. 随着分片离开,GPU 摄入节点的页缓存被释放,为下一个写入周期腾出空间。
在任何时候,查询流量都不会触及 GPU 摄入节点。在任何时候,GPU 都不需要持有超过一批向量的 VRAM。GPU 在步骤 4-6 期间繁忙,否则处于空闲状态。系统 RAM 在 GPU 的两侧都处于路径中:作为 PCIe 传输的暂存区域,以及作为提供服务的持久页缓存。
添加带有重新量化的 BBQ 冷层
模式 B 可以扩展到 BBQ 冷层,用于长期保留的语料库。BBQ 相较于 int8 提供了大约 8 倍的压缩,极大地缩小了冷层的 RAM 和磁盘占用空间。ILM 策略添加了一个阶段,将 int8_hnsw 数据重新索引到一个配置为 bbq_hnsw 的新索引中:
1
2
3
4
5
6
7
8
9
10
"cold": {
"min_age": "180d",
"actions": {
"allocate": {
"require": {
"tier_function": "cpu_serve"
}
}
}
}
实际上,重新量化是通过一个单独的 reindex 作业完成的,该作业与冷阶段的转换一起触发。BBQ 相较于 int8 大约提供了 8 倍的压缩(相较于 float32 约 32 倍),因此冷层的 RAM 和磁盘占用空间显著缩小。
请注意,BBQ 是一种仅限 CPU 的量化路径。截至 9.5 版本,Elasticsearch 中的 cuVS 不支持 bbq_hnsw。这就是为什么 GPU 摄入层使用 int8_hnsw 进行构建,而 BBQ 转换在之后在 CPU warm 或 cold 节点上进行。冷路径没有 GPU 依赖。
您应该选择哪种模式?
对于大多数拥有五个或更多数据节点的生产集群,模式 B 是更好的默认选择。模式 A 适用于概念验证部署和小型集群,其中操作简便性比成本更重要。
因素 | 模式 A (组合型) | 模式 B (专用 GPU 摄入) |
|---|---|---|
集群大小 | 少于约 5 个数据节点 | 5 个以上数据节点 |
操作复杂性 | 较低 | 较高 (ILM + 分配路由) |
GPU Pod 系统 RAM | 128–192 GB | 64 GB |
GPU 利用率 | 查询期间 GPU 空闲 | 刷新间隔期间 GPU 空闲,但节点不提供查询服务 |
硬件成本 | 较高 (每个 GPU 节点都需要查询服务 RAM) | 较低 (GPU 摄入节点轻量化) |
ERU 影响 | 较高 | 较低 |
最适合 | POC 或边缘部署 | 拥有 5 个以上数据节点的生产环境 |
对于大多数生产部署,模式 B 是更好的默认选择。操作复杂性适中(本文所示的 ILM 策略和分配属性即为全部实现),并且在 GPU 节点 RAM 和 ERU 方面的节省是可观的。
开始使用 NVIDIA cuVS GPU 向量索引
使用 NVIDIA cuVS 进行 GPU 加速的向量索引在 Elasticsearch 9.3(自管型企业版)中提供技术预览,并计划在 Elasticsearch 9.5 中全面推出。
要求:
- • Elasticsearch 9.3+,并拥有企业订阅
- • NVIDIA Ampere 架构 GPU 或更新版本(计算能力 ≥ 8.0),最低 8 GB VRAM
- • CUDA 12.x 和 cuVS 运行时库(请参考 Elastic 支持矩阵以获取确切支持版本)
- • GPU 节点上的 Java 22 或更高版本
- • Linux x86_64
- • 快速本地 NVMe(不推荐使用网络附加存储)
对于正在权衡与 FAISS 或专用向量数据库(如 Milvus 或 Pinecone)相比的团队,操作上的优势在于:同一个单一平台、相同的 ATO、相同的操作模型,并在现有 Elasticsearch 集群之上叠加了 GPU 加速的摄入功能。更广泛的 Elastic 和 NVIDIA 合作背景请参阅《Elastic 和 NVIDIA 携手开启下一代企业 AI 搜索》。
首先在单个 GPU 节点上使用模式 A 来验证您语料库的吞吐量。一旦您对数据有信心,就可以使用上述 ILM 策略转到模式 B,扩展 CPU 热服务层以匹配您的查询 SLA,并让 GPU 摄入层做它唯一擅长的事情:以比 CPU 快 12 倍的速度构建 HNSW 图。
有关 cuVS 基准测试方法和结果,请参阅[使用 NVIDIA cuVS 在 Elasticsearch 中实现高达 12 倍的向量索引速度提升]。有关 Elastic 和 NVIDIA 更广泛的合作,请参阅[Elastic 和 NVIDIA 携手开启下一代企业 AI 搜索]。
常见问题
为什么 Elasticsearch 在大型语料库上的向量索引速度很慢?
HNSW 图构建是 CPU 密集型操作,并在规模化时主导索引时间。添加 NVIDIA cuVS 插件将图构建转移到 GPU,在基准测试硬件上,其运行速度最高可达 12 倍。对于数亿向量的语料库,这能将数周的索引工作缩短到数天。
如何在 Elasticsearch 中部署 GPU 向量索引而不让 GPU 节点服务查询?
使用两层架构:配备 cuVS 插件和 64 GB RAM 的 GPU 摄入节点构建 HNSW 段并拥有活动的写入分片。然后,ILM 滚动策略将完成的分片迁移到配备 192 GB RAM 的 CPU 热服务层,该层处理所有查询。自定义节点属性 tier_function 控制哪些节点接收新写入,哪些节点接收迁移的分片。
Elasticsearch 的 dense_vector 字段能否使用 NVIDIA cuVS 进行 GPU 加速?
可以,在自管型企业版 Elasticsearch 9.3 及更高版本中,只要节点安装了 cuVS 插件并配备了受支持的 NVIDIA GPU 即可。您必须在 dense_vector 字段上明确设置 index_options.type 为 int8_hnsw 或 hnsw,因为 9.1 及更高版本中的默认 bbq_hnsw 不受 cuVS 的 GPU 加速支持。
Elasticsearch 中 GPU 向量索引节点需要多少 RAM?
一个 GPU 摄入节点仅持有当前正在写入的分片,因此大约 60 GB 的总 RAM 就足够了(32 GB JVM 堆内存,10 GB CUDA 运行时和固定的 PCIe 缓冲区,10-15 GB 页缓存,5 GB 操作系统开销),这与 AWS g6.4xlarge 基准测试硬件配置相符。存储累积 HNSW 语料库的 CPU 热服务节点则需要 128-192 GB,具体取决于每个节点的分片数量。
为什么我的 Elasticsearch GPU 插件在安装 cuVS 后仍未加速向量索引?
最常见的原因是使用了默认的 bbq_hnsw 索引选项,cuVS 插件不支持该选项。请在 dense_vector 映射中将 index_options.type 设置为 int8_hnsw 或 hnsw。同时,请验证节点是否具有计算能力 8.0 或更高版本的 NVIDIA GPU、CUDA 12.x,并且 vectors.indexing.use_gpu 已设置为 true。
如何配置 ILM 将 Elasticsearch 分片从 GPU 构建层迁移到 CPU 服务层?
在 warm 阶段设置 "migrate": {"enabled": false},这样 ILM 就不会尝试将分片移动到此架构中不存在的 data_warm 角色;然后使用显式的 allocate 操作将分片路由到具有 node.attr.tier_function: cpu_serve 属性的节点。完整的策略结构和索引模板已在文章中给出。
我应该使用带有 NVIDIA cuVS 的 Elasticsearch 还是专用向量数据库?
如果您已经使用 Elasticsearch 进行搜索、可观测性或安全分析,那么添加 cuVS 可以在同一平台上支持代理 AI 工作负载,而无需第二个数据存储或独立的操作模型。cuVS 也完全在本地硬件上运行,这对于气隙(air-gapped)、主权(sovereign)和本地部署环境非常重要,因为这些环境无法使用托管向量数据库。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号