大模型优化技术(RAG 和 LoRA)对比


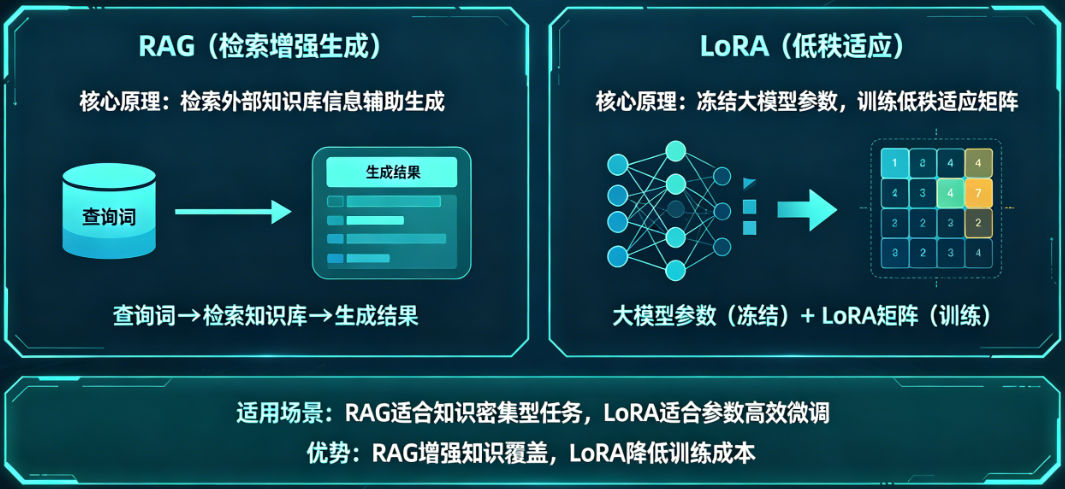
RAG 和 LoRA 是优化大模型的两种主流且互补的技术, LoRA 是给模型“大脑升级”的技能插件,RAG 是给模型“大脑联网”的外挂知识库, 分别从“模型能力”和“知识获取”两个不同维度,来解决让通用大模型变得更专业的问题。
两者的对比如下:
对比维度 | LoRA (低秩适应) | RAG (检索增强生成) |
|---|---|---|
核心思想 | 训练一个技能插件冻结原有模型,只训练一个极小模块,使模型在特定任务上“更擅长” | 挂载一个外挂知识库不修改模型,从外部知识库检索信息,让模型“懂得更多” |
工作原理 | 改变模型本身通过矩阵分解微调部分权重,从根本上调整模型的思考方式 | 改变模型输入检索相关信息并拼接到问题中,模型基于增强的输入进行回答 |
知识更新 | 成本高,需重新训练新知识需要重新微调,生成新的LoRA模块 | 成本低,即时生效直接更新外部文档库即可,无训练成本 |
硬件需求 | 中高,需要GPU训练需要一定算力,但推理时与普通模型无异 | 极低,无需GPU对算力要求低,是RAG的核心优势之一 |
主要优势 | • 性能强:深度改变模型行为,效果提升显著• 适配快:训练参数极少,速度快• 可插拔:LoRA模块极小,可灵活切换 | • 成本低:无需模型训练,实现成本极低• 可溯源:答案有据可查,减少幻觉• 动态更新:知识库实时更新,内容不过时 |
主要局限 | • 训练成本:仍需准备训练数据和进行训练• 过时风险:模型知识无法自动更新• 无法溯源:模型内部决策过程不透明 | • 能力受限:无法改变模型本身能力,依赖检索质量• 效果上限:不擅长需要深度推理的任务• 基础依赖:效果受限于基础模型自身能力 |
PART 01
LoRA (Low-Rank Adaptation)
LoRA是一种高效的模型微调技术,其核心在于用极低的成本改变模型本身的行为模式。
工作原理
它基于一个关键发现:微调时模型权重的变化(ΔW)具有"低秩"特性,意味着,尽管模型变化看似复杂,但可以用更少的参数来概括。因此,LoRA冻结了原始的预训练模型权重,只额外添加两个非常小的矩阵A和B,通过训练这两个小矩阵来模拟完整权重矩阵的变化。
LoRA就像是 给大脑植入一个"微芯片", 不改变大脑的结构,而是额外植入一个能处理特定任务的微型芯片,来改变大脑处理该任务的方式。
LoRA擅长让模型在 行为、风格、逻辑或复杂推理 上做出深度改变,例如,让模型学会特定领域的行话,模仿特定文风,或掌握特定任务的操作流程。
PART 02
RAG (Retrieval-Augmented Generation)
RAG是一种为模型动态提供最新、最相关知识的技术方案,其核心在于不改变模型本身,而是实时地为模型"查资料"。
工作原理
RAG的工作流程分为两步: 检索和生成 。
- 检索 :收到问题时,RAG首先将问题转化为向量,在知识库(如公司内部文档)中搜索最相关的信息片段。
- 生成 :将这些片段与原始问题一起提交给大模型,模型据此生成有据可依的回答。
RAG就像是 给大脑配一个秒查资料的"超级助理", 遇到问题时,大脑不自己回忆,而是先让助理去查资料,再将查到的信息一起思考后回答。
RAG的核心优势在于处理 需要大量、最新、具体事实信息 的场景。例如,企业内部的智能问答助手,根据产品手册解答客户咨询,或实时新闻分析、财报解读等需要最新数据的应用。
PART 03
组合策略
选择的关键在于明确问题是要 改变模型本身 ,还是 引入外部知识, 对于VLA清洁机器人项目,由于需要让模型学会“柔性跟随内外壁”这类全新的 技能和动作模式 ,这触及了模型的“推理”和“行为”能力,是LoRA的优势领域。因此,建议 以LoRA为主,RAG为辅 。
在实际应用中,将两者结合是最佳实践,组合方式主要有两种:
- 顺序组合 :先用 LoRA微调 模型的核心能力(如清洁动作),再部署 RAG系统 处理任务中变化的场景信息(如不同型号的操作指南)。
- 并行组合 :设计一个决策器来判断任务类型, 对深层任务调用LoRA模块,对知识性任务调用RAG流程 。同时,LoRA生成的结果可作为RAG的检索源,形成正向循环。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号