谷歌SkillOS,让Agent自己管Skill

谷歌SkillOS,让Agent自己管Skill

Ai学习的老章
发布于 2026-05-22 20:06:20
发布于 2026-05-22 20:06:20
谷歌前几天放了一篇论文,把 Skill 这套玩法直接推到了一个新阶段:让 Agent 自己学会写、自己学会改、自己学会删 Skill
论文叫《# SkillOS: Learning Skill Curation for Self-Evolving Agents》

arxiv.org/abs/2605.06614
一句话概括论文
Skill 是 Agent 的"程序性记忆",过去都是人手动写、手动维护;SkillOS 让 RL 训练出来的一个"Skill Curator"自动接管这件事
整个系统由两部分组成:
- Agent Executor(冻结,不训练):负责干活——给一个任务,它从 SkillRepo 里挑相关 Skill,按 Skill 执行
- Skill Curator(可训练):负责管 Skill——执行完一个任务后,看着轨迹决定是 insert / update / delete,更新 SkillRepo
下图就是 SkillOS 的整体框架,论文 Figure 1:
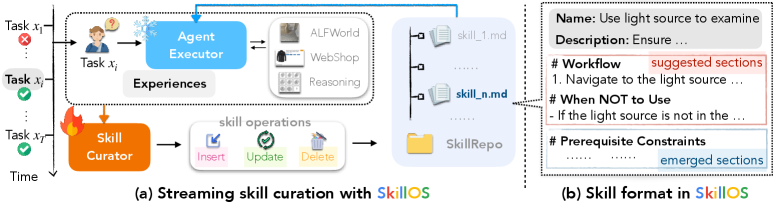
SkillOS 整体框架:Executor 用 Skill,Curator 改 Skill
我把这个闭环再画成一张信息图:
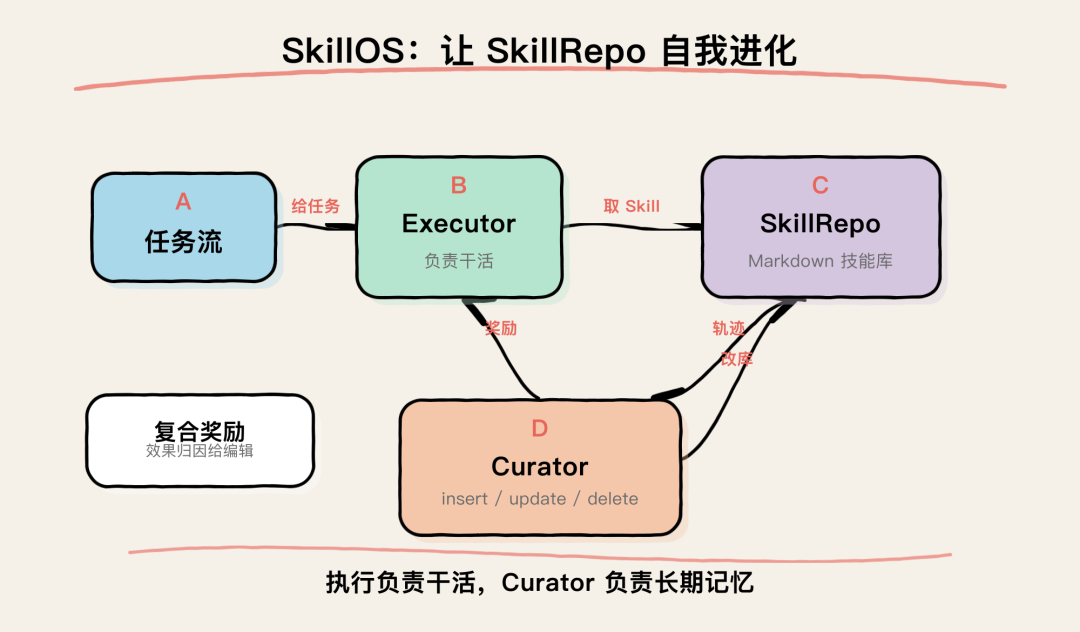
SkillOS 让 SkillRepo 自我进化
注意一个非常关键的细节:Skill 的存储格式是 Markdown 文件——和 Anthropic 那套 Agent Skills 一脉相承
论文要解决什么问题
LLM Agent 现在最大的尴尬:每个任务都是"一次性"的,做完就忘,下次相似的任务还得从头再算一遍
业界已有几条路线:
路线 | 问题 |
|---|---|
人手写 Skill(如 Anthropic Skills) | 需要大量人力专家,覆盖不了任务多样性 |
启发式规则(A-Mem、Alita 等) | 操作固定,没法跟下游执行效果挂钩 |
短 horizon RL | 学不到长期、复杂的"管理"决策,比如"什么时候该删、什么时候该合并" |
SkillOS 的角度是:用 RL 训练一个长 horizon 的 Curator,专门学习 Skill 库的管理策略
关键设计
1. 任务流分组 + 两阶段评估
它把任务按"技能相关性"分组成 stream:前面的轨迹用来更新 SkillRepo,后面相关的任务用来评估"你这次更新是不是真的有用"——给 Curator 提供了延迟奖励信号
2. 复合奖励 (composite rewards)
光看下游对/错没法准确归因到 Curator 的某次具体编辑——所以作者设计了组合奖励,把执行反馈更精准地传回给"那一次 Skill 操作"
3. Skill 格式定死 Markdown
跟 Claude Skills、OpenAI Skills 的存储格式一致,方便迁移、方便人读、方便 LLM 写
实验结果(结论性的部分)
论文在多轮 Agent 任务和单轮推理任务上都做了对比:
- SkillOS 稳定打过 memory-free baseline 和强 memory-based baseline——又快又准
- 训出来的 Curator 能跨 Executor 主干迁移(即你换底层模型,Curator 还能用)
- 训出来的 Curator 能跨任务域迁移
- 更有意思的:随着训练推进,SkillRepo 内部会发展出**更高层级的"meta-skill"**——也就是 Skill 自己开始有层次结构、有抽象——这点很哲学了
这篇论文为什么值得关注
1. 它正式把"Skill 管理"这件事变成了一个 RL 问题
之前大家想 Skill 体系,要么靠人写、要么靠规则,SkillOS 给出了"学习 Skill 管理策略"这条路的可行性证明
2. 它选了 Markdown 作为载体
这个选择不是巧合,Anthropic Skills、OpenAI 最近的 Skill 体系、Hermes Agent 的 Universal Skills 全是 Markdown——这意味着学界和业界的"Skill 格式标准"正在收敛
3. 它给 self-evolving agent 提供了一个具体抓手
"自进化 Agent"这个词喊了快一年了,但具体怎么"进化"一直没明确锚点,SkillOS 把锚点定在"Curator 学会管理 SkillRepo"上,这条线比模糊地说"加 memory"要清晰得多
局限和疑问(我个人的看法)
- 论文里 RL 训练成本到底多大,没充分展开——这是工程上的真问题
- "Curator 能跨任务域迁移"听起来很美,但跨度有多大?需要更多对照实验
- Markdown 是好选择,但 Skill 间的依赖、版本、冲突怎么处理,是后续要补的拼图
总结
我之前文章里多次说过,Skill 会成为 Agent 体系的标配,SkillOS 这篇论文又往前推了一步:Skill 这套体系不仅要会用,还要会"管",而"管"也可以被训练
接下来一年,估计会看到一波"用更聪明的方法管 Skill"的工作冒出来——SkillOS 是其中很扎实的一篇
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号