面试官问你「会写Agent Skill吗」,别只说「写提示词」——这才是正确答案

面试官问你「会写Agent Skill吗」,别只说「写提示词」——这才是正确答案

王中阳AI编程
发布于 2026-05-26 17:25:15
发布于 2026-05-26 17:25:15
最近面试AI Agent岗,有个问题出现频率特别高:「如果让你给Agent写Skill,你会怎么写?」 很多人一听Skill,直接说:「不就是写一段提示词吗?」——面试官听完直接皱眉头。 别小看这个问题,它考察的不是你会不会写Prompt,而是你有没有把重复经验沉淀成可复用能力的工程意识。 这篇文章系统讲一下:Skill到底是什么?和Prompt、Tool、MCP、Memory、Harness有什么区别?一个高质量Skill应该包含什么?怎么写?怎么管理?面试怎么答?
一、👔 面试官:先给结论——Skill到底是不是更长的Prompt?
🙋♂️候选人:Skill就是给Agent写的一段更详细的提示词……
👔面试官:那Prompt和Skill有什么区别?
🙋♂️候选人:呃……Skill更长更详细?
👔面试官:那什么任务适合沉淀成Skill?什么不适合?Skill和Tool、MCP、Memory、Harness又有什么边界?
💡 简要回答
Skill不是更长的Prompt,而是把可复用经验、操作流程、工具使用方法和质量标准沉淀成Agent可调用的能力模块。Prompt解决单次任务表达,Skill解决跨任务复用。
📝 详细解析
Skill到底是什么
可以这样定义:Skill是面向某一类任务的可复用能力说明,它告诉Agent什么时候用、怎么做、用什么工具、按什么标准输出、遇到异常怎么处理。
注意,它不是简单写一句:
你是一个专业的简历优化专家。
这太空了。一个真正有用的Skill,应该能回答这些问题:
- 什么场景该用它?
- 什么场景不该用它?
- 输入需要哪些信息?
- 操作步骤是什么?
- 优先使用哪些工具?
- 输出格式是什么?
- 怎么判断结果合格?
- 信息不足怎么办?
- 工具失败怎么办?
- 有哪些安全边界?
举个例子,如果你写一个"简历项目点评Skill",它不应该只说"帮用户优化简历项目",而应该写清楚:
- 先判断项目描述是否有业务场景
- 再检查个人工作是否突出技术贡献
- 再看项目难点是否有挑战和解决方案
- 再给出优化版本
- 输出必须包含反面问题和正面示例
- 不要凭空编造用户没写过的经历
这才是Skill。Skill的价值不是让模型"知道一个名词",而是让模型在某类任务上更稳定地遵循流程和边界。
Skill和其他概念的区别
面试官很喜欢问边界,因为很多人把这些概念混在一起。你要能讲清楚它们分别解决什么问题:
概念 | 解决的问题 | 和Skill的区别 |
|---|---|---|
Prompt | 单次任务表达 | Prompt是临场告诉模型"这次按A、B、C做",Skill是提前沉淀好一套SOP"以后遇到这类任务都这么做" |
Tool | 执行动作的能力 | Tool解决"能不能做",Skill解决"怎么做得更稳"——比如search_docs是工具,Skill告诉Agent"什么时候检索、检索几轮、怎么判断够不够" |
MCP | 工具接入协议 | MCP提供工具生态,Skill提供任务方法论——Skill不负责协议,负责告诉Agent该不该用、怎么用MCP工具 |
Memory | 经验和事实的存储 | Memory是材料库(用户喜好、历史记录),Skill是操作手册(做事的流程和标准) |
Harness | 全局运行时治理 | Harness管全局(编排、权限、成本、安全),Skill管局部(某个具体任务怎么做) |
一句话总结:Prompt适合一次性任务,Skill适合高频重复任务。Tool是执行器,Skill是使用指南。MCP是接入协议,Skill是使用策略。Memory是知识库,Skill是方法论。Harness是全局治理,Skill是局部能力。
二、👔 面试官:一个高质量Skill应该包含什么?
🙋♂️候选人:就是把提示词写得详细一点……
👔面试官:详细到什么程度?要不要写安全边界?要不要写失败处理?要不要写质量标准?
💡 简要回答
写Skill不能只写"你要专业"这类没工程价值的话。一个高质量Skill至少应该包含:适用场景、不适用场景、输入要求、操作步骤、工具使用、输出格式、质量标准、失败处理、安全边界。
📝 详细解析
高质量Skill的九个组成部分
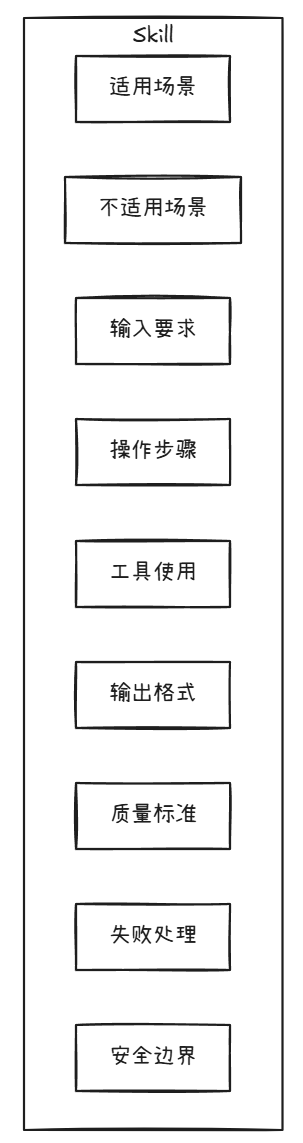
逐个拆解:
1. 适用场景:什么时候该用这个Skill?
- 比如:"当用户要求分析简历项目、优化项目经历、点评个人工作时使用"。适用场景越清楚,Agent越不容易误用。
2. 不适用场景:什么时候不该用?
- 这点很重要!很多Skill只写能做什么,不写不能做什么,结果Agent一遇到相似任务就乱套。比如简历点评Skill不应该用于:生成虚假实习经历、伪造项目成果、编造公司背景、替用户写不真实的技术细节。Skill要写边界,不只是写能力。
3. 输入要求:Skill要说明需要哪些输入
- 比如:原始简历内容、目标岗位、项目背景、技术栈、用户想优化哪一部分。如果输入不足,Skill应该要求Agent先追问,而不是硬编。
4. 操作步骤:Skill最重要的是流程
- 比如:先识别任务类型→再检查信息完整性→再按框架分析→再输出优化建议→最后给出可直接替换的版本。步骤要明确,但不要写死到无法适配。
5. 工具使用:如果任务需要工具,要写清楚
- 优先用哪个工具?什么情况下不用工具?工具失败怎么办?工具结果如何验证?注意,Skill不能绕过Tool Registry,它只能指导工具使用方式,不能替代权限治理。
6. 输出格式:Agent最容易不稳定的地方就是输出格式
- Skill里应该写清楚:最终输出分几部分?要不要表格?要不要代码?要不要引用来源?要不要风险提示?
7. 质量标准:Skill要告诉Agent什么叫做好
- 比如:是否解决用户目标?是否有事实依据?是否结构清晰?是否可执行?是否避免无关展开?没有质量标准,Agent只会生成"看起来像完成了"的结果。
8. 失败处理:真实任务里经常失败
- Skill要写:信息不足怎么办?工具失败怎么办?证据不足怎么办?权限不足怎么办?结果冲突怎么办?高质量Skill一定要有兜底策略。
9. 安全边界:比如不要编造事实、不要绕过权限、不要执行高风险动作、不要输出敏感信息、不要把不确定内容说成确定事实。这里要强调:安全边界不能只写在Skill里,工程层也要有拦截——Skill是提醒,Harness和Tool Registry才是强制执行。
三、👔 面试官:怎么写出高质量Skill?
🙋♂️候选人:就是想清楚流程,然后写出来……
👔面试官:那流程是从哪来的?凭经验拍脑袋?还是有方法论?
💡 简要回答
好的Skill不是坐在工位上拍脑袋写出来的,而是从真实任务里抽出来的。推荐路径:重复任务→失败案例→专家流程→工具经验→Eval反馈→Skill迭代。
📝 详细解析
写出高质量Skill的五个步骤
1. 从重复任务里提炼
不是所有任务都值得写Skill。Skill适合高频、重复、流程相对稳定的任务,比如:
- 简历点评
- 日志排查
- RAG评估
- SQL优化
- 文档生成
- PR Review
- 数据分析报告
如果任务只出现一次,写Skill成本可能不划算。
2. 从失败案例里补规则
Skill最有价值的来源,是Agent犯过的错。
- 比如Agent做RAG评估时,经常只看最终答案,不看证据来源→Skill里就要补"必须检查答案关键结论是否被检索文档支持"
- 比如Agent写代码时经常忘记跑测试→Skill里就要补"修改代码后优先运行相关最小测试"
好的Skill,是从错误里长出来的。记住:Skill是软约束,工程拦截才是硬约束——Skill可以提醒,但真正的安全控制要在Harness和Tool Registry层实现。
3. 从专家流程里抽SOP
很多专家做事有隐性流程。
- 比如一个资深工程师排查线上问题,不会一上来就改代码→他会先看影响范围,再看日志,再看最近变更,再验证假设
这种流程就适合沉淀成Skill。Skill的价值,就是把专家隐性经验显性化。
4. 从工具使用经验里沉淀最佳实践
有些工具很强,但用不好。
- 比如浏览器自动化、数据库查询、RAG检索、日志平台、代码搜索
Skill可以写清楚:
- 查询前先缩小范围
- 不要一次取太多结果
- 先读schema再写SQL
- 搜不到时换关键词
- 工具结果要二次校验
这会显著提升Agent的稳定性。
5. 从Eval结果里迭代
Skill写完不是结束,要看效果。
- 如果某个Skill加载后,任务成功率上升、工具失败率下降、格式错误率降低→说明它有效
- 如果Skill加载后Token暴涨,误召回增加→说明它可能污染上下文
Skill要进入评测闭环,不是写完就放在那里。
四、👔 面试官:Skill多了之后,Agent怎么选择和调用?
🙋♂️候选人:就是让Agent自己选……
👔面试官:那选错了怎么办?Skill冲突了怎么办?怎么控制Token消耗?
💡 简要回答
Skill选择不是单一方案,而是组合使用:显式指定(最稳定)、任务描述匹配(最灵活)、Metadata检索(最可控)、Harness控制注入(最安全)。最重要的是——Skill要按需加载,不要全塞进去污染上下文。
📝 详细解析
Skill选择的四种方式
Skill多了之后,最大的问题不是怎么写,而是怎么选。面试官很可能会问:"如果系统里有几十个Skill,Agent怎么知道该用哪个?"
可以分四种方式:
方式 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
显式指定 | 用户或系统直接指定用哪个Skill | 最稳定,不会选错 | 不够灵活 | 后台任务、固定流程、自动化工作流 |
任务描述匹配 | 根据用户输入和Skill描述做匹配 | 最灵活,用户体验好 | 依赖Skill描述质量,可能误匹配 | 开放式对话、用户自主使用 |
Metadata检索 | 每个Skill有metadata(name、description、domain、task_type等),根据metadata检索路由 | 比全文匹配更可控,可扩展 | 需要维护metadata | 中等规模Skill库 |
Harness控制注入 | Harness根据任务类型、用户权限、上下文预算、风险等级决定注入哪些Skill | 最安全,可控制成本 | 需要实现Harness层 | 生产级系统 |
推荐做法:生产系统里,不应该让Agent自己随便加载所有Skill。Agent可以建议用Skill,但Harness应该控制Skill注入。
Skill选择失败怎么办
Skill召回错了,会误导Agent。比如用户只是问"怎么写简历",系统却加载了"简历造假美化Skill"——这就危险了。
所以要有:
- Skill命中置信度:置信度低时不自动加载,而是询问用户
- 多Skill冲突检测:如果多个Skill规则冲突,按优先级处理
- 低置信度时追问用户:"我不确定该用哪个Skill,你能告诉我吗?"
- 高风险Skill需要显式确认:涉及删除、修改等操作的Skill,必须用户确认
- Skill使用记录进入Trace:方便排查问题和迭代Skill
五、👔 面试官:Skill的上下文怎么治理?会不会污染?
🙋♂️候选人:就是把所有Skill都塞进去……
👔面试官:那Token会不会爆炸?上下文会不会被污染?Agent会不会被误导?
💡 简要回答
Skill本来是能力资产,但管理不好会变成上下文噪声。核心策略:按需加载、分层摘要、优先级和作用域、版本管理、过期Skill淘汰。Skill不是越多越好,是越准越好。
📝 详细解析
Skill上下文治理的五个策略
Skill多了之后,会出现一个新问题:Skill本来是能力资产,但管理不好会变成上下文噪声。很多团队一开始很兴奋,写了几十个Skill,然后每次任务都塞一堆进去,结果模型看了一大堆不相关规则,反而更容易跑偏。
这就是Skill污染上下文。怎么治理?
1. 按需加载:不要把所有Skill都放进上下文,只加载当前任务需要的最小集合。Skill应该像工具一样按需调用,而不是像背景音乐一样一直播放。
2. 分层摘要:Skill可以分层:
- metadata:用于检索和路由
- summary:用于快速判断是否适用
- full instruction:真正执行时再加载
这样可以减少上下文浪费。
3. 优先级和作用域:不同Skill可能冲突,比如一个Skill要求"回答尽量简洁",另一个Skill要求"详细解释每一步"。这时要有优先级,通常可以按:系统安全规则 > 项目级规则 > 任务级Skill > 用户喜好。作用域也要清楚,不要让一个局部Skill影响全局任务。
4. 版本管理:Skill会迭代,每次修改都应该有版本,至少要记录:修改原因、影响场景、评测结果、回滚方式。否则Skill越改越乱。
5. 过期Skill淘汰:业务会变,工具会变,模型能力也会变,旧Skill可能不再适用。所以要定期检查:是否还被命中?是否提升指标?是否产生误导?是否和新工具冲突?无效Skill要下线。
一句话总结:Skill不是越多越好,是越准越好。
六、👔 面试官:Skill怎么评估效果?
🙋♂️候选人:就是看效果好不好……
👔面试官:怎么定义"好"?有没有量化指标?有没有A/B测试?
💡 简要回答
不要只说写了Skill,要说怎么证明它有用。核心指标:任务成功率、工具调用成功率、输出稳定性、人工修正率、Token消耗、Skill命中准确率和误召回率。还要做A/B测试对比。
📝 详细解析
Skill效果评估的七个指标
面试中说Skill,有一个很重要的加分点:不要只说写了Skill,要说怎么证明它有用。如果你说"我加了Skill后感觉效果更好了",这不算工程结论。要看指标。
指标 | 说明 | 怎么算提升? |
|---|---|---|
任务成功率 | 加载Skill后,任务是否更容易完成?比如简历点评是否覆盖四要素、日志排查是否定位到根因、代码修改是否通过测试 | 成功率上升 |
工具调用成功率 | Skill是否减少了错误工具调用?比如工具选错率、参数非法率、无意义重复调用、高风险工具误调用 | 失败率下降 |
输出稳定性 | 看输出是否更稳定?比如格式错误率、字段缺失率、引用缺失率、不按流程输出的比例 | 错误率下降 |
人工修正率 | 如果Skill有效,人工修正应该减少,特别是面向内容生成、代码修改、数据分析的任务 | 返工率下降 |
Token消耗 | Skill不是免费的,加载Skill会占上下文。要看Skill Token占比、总Token是否上升、重试次数是否下降、单任务成本是否下降 | 成本下降或持平,但效果提升 |
Skill命中准确率 | 该用的时候有没有用? | 准确率上升 |
Skill误召回率 | 不该用的时候有没有乱用?误召回很危险,因为错误Skill会给Agent带来错误方向 | 误召回率下降 |
A/B测试怎么做
可以做对比:
- 不加载Skill vs 加载Skill
- 旧Skill vs 新Skill
- 单Skill vs Skill组合
- 全量Skill vs 最小必要Skill
有对比,才能知道Skill是真的有效,还是只是心理安慰。
七、👔 面试官:Skill常见的误区有哪些?
🙋♂️候选人:好像没什么误区……
👔面试官:那你有没有把Skill写得特别长?有没有只写步骤不写边界?有没有Skill冲突不管?
💡 简要回答
常见误区:把Skill写成长Prompt、只写步骤不写边界、Skill互相冲突不管、工具细节写太死、Skill不更新、所有任务都强制加载、没有Eval只靠感觉迭代、把安全约束只写在Skill里。
📝 详细解析
八个常见误区
这里面试也很容易问,因为很多团队引入Skill后,确实会踩坑:
1. 把Skill写成长Prompt:Skill不是越长越好,太长会挤占上下文,还会让模型抓不住重点。好的Skill应该结构清楚、边界明确、只包含必要信息。
2. 只写步骤,不写边界:只写"怎么做",不写"什么时候不该做",很容易误用。Skill必须写不适用场景和风险边界。
3. Skill互相冲突:多个Skill同时加载时,规则可能冲突。所以要有优先级、作用域和冲突检测。
4. 工具细节写太死:如果Skill把某个工具的参数写死,工具一升级就坏。Skill应该描述工具使用原则,具体schema以Tool Registry为准。
5. Skill不更新:业务会变,工具会变,模型能力也会变,Skill也要变。过期Skill会误导Agent。
6. 所有任务都强制加载Skill:这会造成上下文污染。Skill应该按需加载,不是越多越专业。
7. 没有Eval,只靠感觉迭代:没有指标,就不知道Skill有没有价值。最后会变成一堆没人敢删的历史规则。
8. 把安全约束只写在Skill里:这是很危险的误区。Skill可以提醒模型不要越权,但真正的权限、审批、审计,必须在Harness和Tool Registry层实现。
🎯 总结:面试怎么答Skill相关问题
回顾这篇文章,当面试官问你Skill相关问题时,你可以按这个逻辑链回答:

面试回答框架:
- 先给结论:Skill不是更长的Prompt,而是把可复用经验沉淀成Agent可调用的能力模块。Prompt解决单次任务,Skill解决跨任务复用。
- 再讲边界:Skill和Prompt、Tool、MCP、Memory、Harness的区别——面试官很喜欢问这个,能讲清楚说明你理解透彻。
- 再说结构:一个高质量Skill应该包含九个部分——适用场景、不适用场景、输入要求、操作步骤、工具使用、输出格式、质量标准、失败处理、安全边界。
- 接着讲方法:怎么写出高质量Skill?从重复任务里提炼、从失败案例里补规则、从专家流程里抽SOP、从工具使用经验里沉淀最佳实践、从Eval结果里迭代。
- 然后讲管理:Skill多了怎么选?显式指定、任务描述匹配、Metadata检索、Harness控制注入。上下文怎么治理?按需加载、分层摘要、优先级和作用域、版本管理、过期淘汰。
- 再讲评估:怎么证明Skill有用?七个指标+A/B测试。
- 最后讲避坑:八个常见误区——能说出这些,说明你有实战经验。
最后一句话:Skill真正考的,不是你会不会写一段说明,而是你有没有把重复经验沉淀成可复用能力的工程意识。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号