【AI前沿】83K Star,6种后端,从零长出技能——Hermes Agent凭什么抢走OpenClaw的用户?

【AI前沿】83K Star,6种后端,从零长出技能——Hermes Agent凭什么抢走OpenClaw的用户?

用户1589488
发布于 2026-06-02 11:37:24
发布于 2026-06-02 11:37:24

同样是开源AI Agent,OpenClaw选择「接入一切」,Hermes Agent选择「记住一切」。两条路线之争的背后,是AI Agent从工具到伙伴的范式跃迁。
PART 1:先讲一个时间线
2026年2月25日,Nous Research在GitHub上安静地推了一个仓库:hermes-agent。
没有Product Hunt首发,没有YC Demo Day,没有KOL集体喊单。就一个README和一行安装命令。
然后事情失控了。
- 第1周:Star破1万。社区的反应是"又一个Agent框架?"
- 第2周:Star破3万。反应变成"等等,这东西怎么越用越聪明?"
- 第6周:Star破6万。开始出现「从OpenClaw迁移到Hermes」的教程。
- 截至4月13日:83.3K Star,424位贡献者,4113次Commit。
作为对比:OpenClaw用了近一年才稳定在247K Star(现在涨到355K+)。Claude Code的开源替代品Claw Code两小时破5万,但那靠的是事件驱动(源码泄露+热度爆炸)。
Hermes Agent的增长曲线完全不同——它是被用出来的,不是被炒出来的。
这很罕见。
PART 2:为什么要写这篇文章
目前,我的整个工作流深度绑定在Claude Code + OpenClaw(龙虾)生态里。从晨间港股监控到日常工作研究,龙虾是核心引擎。
所以当我看到越来越多开发者从OpenClaw迁移到Hermes Agent时,第一反应是:这东西到底哪里比龙虾强?
花了两天研究完,结论是——
它不是"比龙虾强"。它根本就是另一种生物。
如果说OpenClaw是一个能力极强的工具箱,Hermes Agent更像一个会成长的实习生。工具箱装满了扳手螺丝刀,拿来就用;实习生刚来什么都不会,但三个月后它比你还懂你的项目。
这不是好坏之争。这是路线之争。
PART 3:三层记忆——Hermes Agent的核心武器
先说最关键的差异点:记忆系统。
OpenClaw的路线:全量持久化 + 向量检索
OpenClaw的记忆策略是"什么都存"。所有对话、上下文、文件操作记录全部灌进向量数据库。需要回忆时,用embedding做语义检索,拉出最相关的几条。
优点显而易见:不丢信息,上下文窗口理论上无限大。
但我在实际使用中遇到过一个很具体的问题:用到第三个月,噪音太大了。
你让它回忆"我上周对股票分析系统做了什么修改",它可能把三个月前一次无关的调试记录也拉出来,因为语义上确实沾点边。向量检索的精度随数据量线性下降——这不是bug,这是架构的天生缺陷。
Hermes Agent的路线:有限记忆 + 主动压缩
Hermes Agent的设计哲学完全相反。
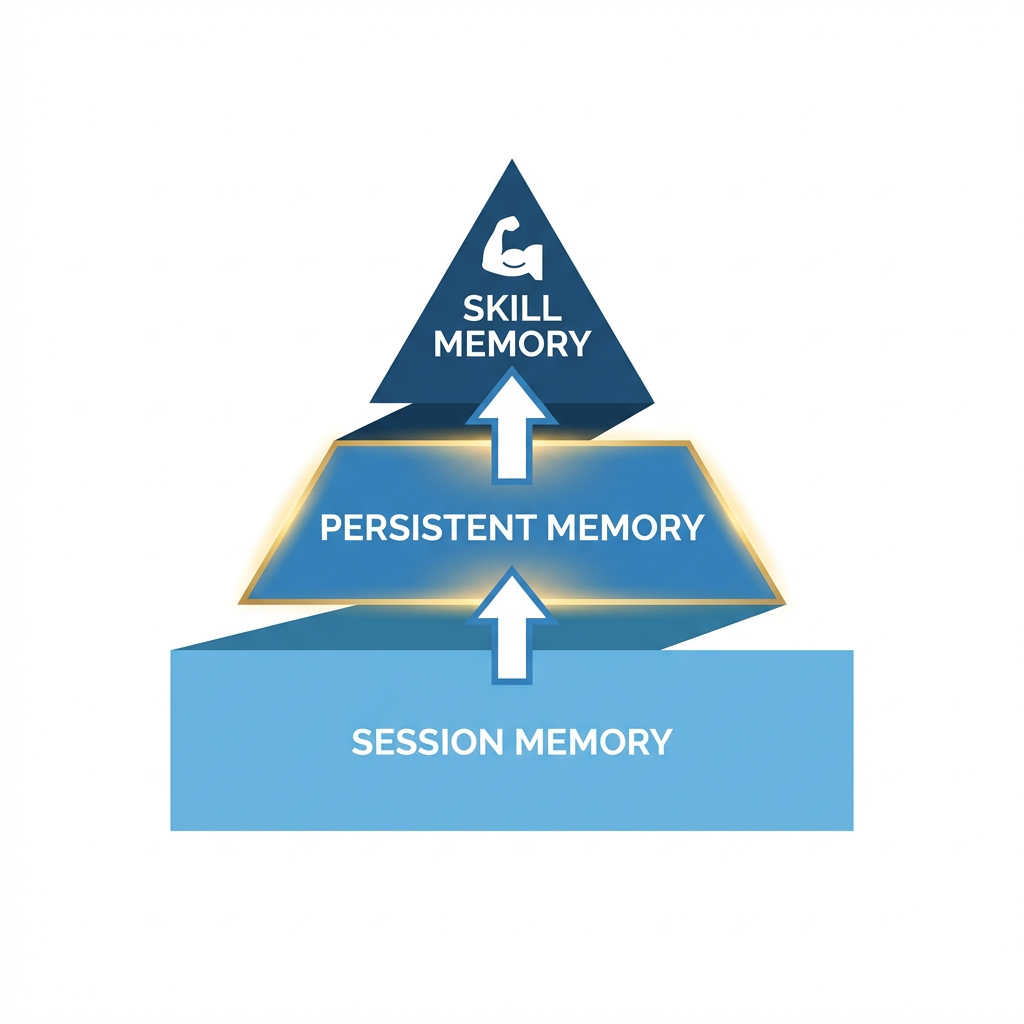
它的记忆系统分三层:
层级 | 容量 | 类比 | 机制 |
|---|---|---|---|
会话记忆 | 当前上下文窗口 | 短期记忆 | 标准LLM上下文 |
持久记忆 | MEMORY.md + USER.md ≈ 1300 tokens | 长期记忆 | 主动压缩、合并、淘汰 |
技能记忆 | SKILL.md 文件集合 | 肌肉记忆 | 从经验中自动生成 |
注意那个数字:1300 tokens硬上限。
这不是限制。这是设计。
Hermes Agent的设计者认为:对LLM来说,少量精准的记忆比大量模糊的记忆更有价值。当记忆接近上限时,Agent会自动做三件事:
- 合并相似条目
- 删除过时信息
- 压缩多条记录为一条摘要
用CSDN一篇对比文章的原话说:
“更像是人在整理笔记,而不是数据库在堆数据。”
讽刺的是,我在WorkBuddy里的MEMORY.md机制,跟这个设计理念几乎一模一样。
我的MEMORY.md不超过1KB,记的都是"港股自选股列表"“企业微信Webhook Key”"养虾系列存放路径"这种高复用信息。日志文件按日存、30天后蒸馏。这套机制是我自己在实践中摸索出来的——而Hermes Agent把它做成了产品级的内置能力。
这说明一件事:好的Agent记忆系统应该是有限的、可压缩的、主动管理的。 全量存储反而是懒惰的做法。
PART 4:自学习循环——最让我警觉的功能
记忆系统是基础设施。真正让Hermes Agent从"又一个Agent框架"变成"有点东西"的,是它的闭环自学习机制。
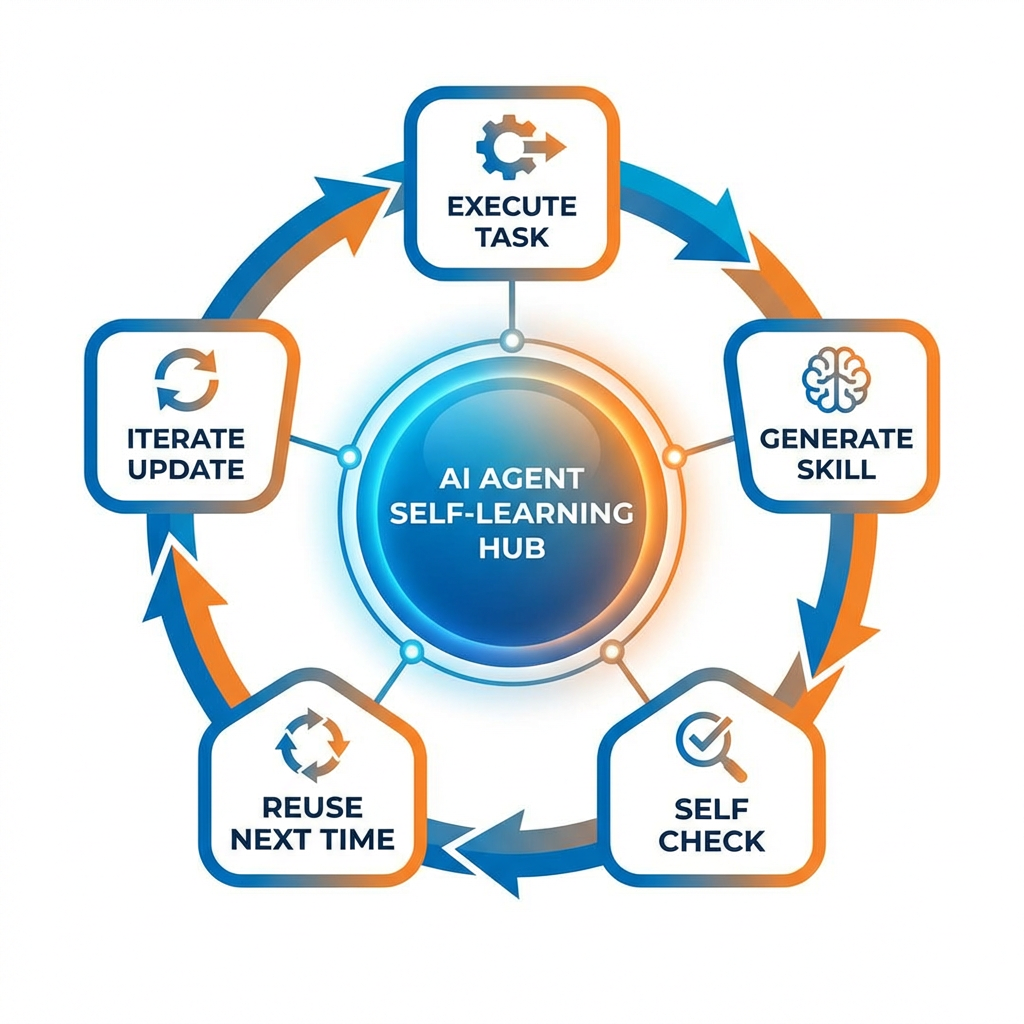
运作原理:
- 触发条件:完成一个需要5次以上工具调用的复杂任务
- 自动产出:生成一份SKILL.md——包含操作步骤、踩过的坑、验证方法
- 自检机制:每15次工具调用,Agent主动暂停做一次自检(“我做到哪了?有没有偏离目标?”)
- 持续迭代:下次遇到类似任务时调用已有Skill,用完后根据新经验更新它
用户实测数据:一个月后,同类任务的平均工具调用次数从25次降到8-10次。
这个数字意味着什么?
意味着三件事:
- 成本下降70%(LLM API调用量直接打三折)
- 延迟降低(更少的tool call = 更快的响应)
- 准确率上升(因为它记住了什么路走不通)
作为对比,OpenClaw也有技能系统——ClawHub上有13000+社区共建的技能。但那是"通用教材":写好了给所有人用,覆盖面广,但不一定适配你的具体环境。
Hermes Agent的技能是"私人笔记":从你的操作中长出来的,包含你的项目结构、你的工具链偏好、你踩过的坑。
一个是标准化的SOP,一个是个性化的经验沉淀。两种路线,没有对错,但Hermes Agent的路线有一个碾压级优势——它的技能和你的使用时长正相关。 用得越久,差距越大。
这就是为什么早期用户不愿意迁移出去。那篇腾讯新闻的文章写得很精准:
“那种感觉就像在养一只宠物,它会记住你教它的每一件事,然后变得越来越懂你。”
我怎么说呢——作为一个养了长时间龙虾的人,这句话很戳。
PART 5:为什么Hermes Agent能爆火——三个结构性原因
回到那个最核心的问题:凭什么是它?
AI Agent框架2026年不下百个。AutoGPT、CrewAI、LangGraph、MetaGPT……为什么Hermes Agent能在6周内冲到83K Star?
原因1:卡位精准——OpenClaw太重,Claude Code太专
Claude Code只在终端/IDE里活着,不碰消息平台,不做定时任务,不持久化记忆。它是最好的编码助手,但你关掉终端它就"死"了。
OpenClaw走的是另一个极端——22个消息平台、13000个技能、全量持久化。功能极度丰富,但配置复杂度也极高。我自己用龙虾的前两周,80%时间花在调配置和排错上。
Hermes Agent恰好卡在中间:
- 比Claude Code多了持久记忆和消息平台(不用守着终端)
- 比OpenClaw轻得多(一行curl安装,5步配置)
- 比AutoGPT实用(不是"自主运行"的表演,而是实际能干活的工具)
不做最强的,做最趁手的。 这种产品感觉非常Nous Research——他们做Hermes系列大模型也是这个路线:不追SOTA榜单,追"开发者用起来最舒服"。
原因2:可感知的成长性
大多数AI产品的能力曲线是这样的:📈第一天很惊艳→📉第三天就"也就那样了"。
Hermes Agent的曲线是反过来的:📉第一天啥也不会→📈第三十天已经能独立处理你80%的常规任务。
这种"越用越好"的体验在消费品领域有一个名字叫用户粘性。在AI Agent领域,它创造了一种前所未有的锁定效应——你不是因为沉没成本不想走,是因为你的Agent真的比别人的Agent更懂你。
OpenClaw的锁定靠生态(插件、技能、MCP服务器)。Hermes Agent的锁定靠经验积累(你用的越久,它学的越多)。
后者更可怕。因为生态可以迁移,经验不可以。
原因3:Nous Research的信任背书 + MIT协议
Nous Research不是一个刚成立的创业公司。他们训练的Hermes系列大模型(Hermes 1/2/3)是开源社区最受信赖的模型系列之一。Hermes 3的技术报告在arXiv上的引用量排在开源模型前五。
MIT协议意味着:零商业限制、零遥测、数据全本地。在Anthropic封杀OpenClaw的大背景下,"不被卡脖子"变成了一个非常有吸引力的卖点。
PART 6:一个养虾人的判断
说完分析,给我自己的判断。
判断1:Hermes Agent和OpenClaw不是替代关系
文章写到这里,可能有人以为我要"叛变"——从龙虾转投Hermes。
不会。
因为两个产品解决的问题根本不同:
- OpenClaw 解决的是「我需要一个中枢来调度多个AI Agent协作」的问题。多渠道、多模型、多工具、多人协作——这是OpenClaw的领地。
- Hermes Agent 解决的是「我需要一个长期陪伴的私人Agent」的问题。自学习、持久记忆、个性化技能——这是Hermes的领地。
- Claude Code 解决的是「我需要最好的代码生成质量」的问题。SWE-bench榜首不是白来的。
三者完全可以共存。
事实上,社区已经有人在做混合方案——用Claude Code写代码,用OpenClaw做多渠道分发,用Hermes Agent做个人知识管理。
判断2:自学习是2026年Agent赛道的分水岭
2023年的Agent赛道,核心比的是"能调用多少工具"。 2024年的Agent赛道,核心比的是"上下文能塞多长"。 2025年的Agent赛道,核心比的是"能接入多少平台"。 2026年,核心比的是"能不能自己变强"。
Hermes Agent是第一个把自学习做成产品级体验的框架。不是学术Demo,不是"理论上可以",是真的一个月后tool call从25次降到8次。
如果OpenClaw不跟进类似的自学习机制,它在个人Agent场景下会被Hermes越拉越远。如果Claude Code不做持久记忆,每次开会话都要重新解释项目背景,开发者迟早会烦。
自学习机制不是nice-to-have。它是接下来三年的主战场。
判断3:警惕"养宠物"心理
最后一个判断,泼一盆冷水。
“越用越懂你"的另一面是"越用越离不开”。
当你的Hermes Agent积累了半年的技能和记忆,你切换到另一个框架的成本就变得极高。这不是技术壁垒——hermes claw migrate能搬走SOUL.md和配置——但那些从你日常操作中自动生成的SKILL.md、从你的反馈中精炼的记忆压缩策略,这些是不可迁移的隐性知识。
某种程度上,这比OpenClaw的生态锁定更深。生态锁定你至少看得到(13000个技能在那摆着),经验锁定是无形的。
所以我的建议是:用Hermes Agent,但保持方法论的可迁移性。 你的核心认知——怎么拆任务、怎么做质量验证、怎么设计工作流——必须存在于你自己的脑子里,而不是Agent的SKILL.md里。
这条建议其实对所有AI工具都适用。
最后
从ep10.5的OpenClaw被封杀,到ep13番外的Claw Code 4天重写,再到今天的Hermes Agent 83K Star。
2026年AI Agent赛道的节奏已经快到不讲道理了。
但节奏越快,越要抓住不变的东西。
OpenClaw教会我"接入一切"的能力。Hermes Agent教会我"记住一切"的价值。Claude Code教会我"执行一切"的底线。
三种哲学,三条路线,最终都指向同一个问题:
你要建造的到底是一个工具,还是一个伙伴?
我的答案是:两者都要。但如果只能选一个——
我选伙伴。工具会被淘汰,伙伴会成长。
关注「一深思AI」,看一个普通人怎么在AI时代活下去。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号