微软开源3.8B文生图模型Lens:更高效、更快、更强的基础图像生成模型

微软开源3.8B文生图模型Lens:更高效、更快、更强的基础图像生成模型

Amusi
发布于 2026-06-02 14:00:09
发布于 2026-06-02 14:00:09
微软正式开源新一代 3.8B 文生图基础模型 Lens。不同于仅发布模型权重的开源方式,本次 Lens 同时公开了模型权重、技术报告、代码仓库、Hugging Face 模型页面,以及完整的训练与优化细节,包括数据构建、模型架构、预训练策略、RL 后训练、Reasoner、few-step distillation 和 benchmark 评测。
本次开源包含 Lens-Base、Lens-RL 和 Lens-Turbo 三个版本。其中,Lens-Base 是预训练基础模型,Lens-RL 经过 RL 后训练以提升图像质量和 prompt 对齐能力,Lens-Turbo 则是 4-step inference 的高速蒸馏版本。Lens 以 3.8B 的紧凑参数规模,在显著降低训练成本的同时,在多个主流图像生成 benchmark 上取得了 SOTA 级别的性能表现。

项目地址如下:
Tech Report:
https://arxiv.org/pdf/2605.21573
GitHub:
https://github.com/microsoft/Lens
Hugging Face:
https://huggingface.co/microsoft/Lens

图1:Lens 生成样例。 Lens 支持最高 1440 分辨率的高质量图像生成,能够覆盖自然风景、人物、文本渲染、插画和复杂视觉场景等多种类型。
Lens的主要特点有:
·模型全面开源:开源 Lens-Base、Lens-RL 和 Lens-Turbo,包括 20-step 高质量版本和 4-step 高速推理版本。
·技术细节全面公开:公开数据构建、预训练、RL 后训练、Reasoner、蒸馏加速、推理配置和 ablation 分析。
·高训练效率:使用 128 张 A100 训练,训练开销约为 Z-Image 的 19.3%。
·SOTA 级性能:在 OneIG、GenEval、LongText 和 CVTG 等多个 benchmark 上取得领先表现。
·高速推理:Lens 在 H100 上生成 1024 分辨率图像仅需 3.15s,Lens-Turbo 仅需 0.84s。
·灵活生成能力:支持最高 1440 分辨率、1:2 到 2:1 任意长宽比、多语言 prompt 输入,以及 Reasoner 自动增强用户输入。
用更少的训练成本,达到更强的生成能力
训练基础文生图模型通常需要极高的算力投入。Lens 的核心目标是重新思考文生图基础模型的训练效率:不仅关注模型规模,也关注每个训练 batch 中的数据有效信息密度,以及模型的收敛速度。Lens 仅使用 128 张 NVIDIA A100 GPU 进行训练,整体训练开销约为 Z-Image 的 19.3%,但仍然在多个 benchmark 上达到甚至超过更大规模模型的表现。相比许多 6B、9B、20B 甚至更大规模的开源图像生成模型,Lens 以更紧凑的 3.8B 参数规模实现了高质量图像生成能力。
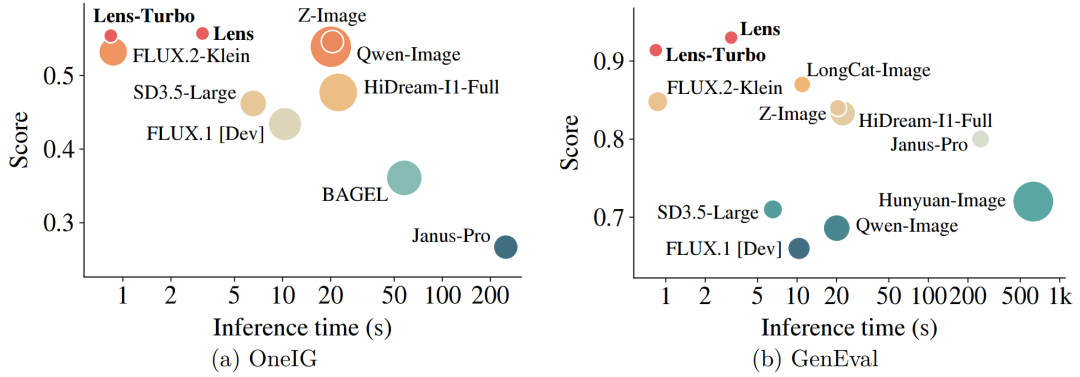
图2:推理速度与生成性能对比。 在 OneIG 和 GenEval benchmark 上,Lens 和 Lens-Turbo 在保持 3.8B 紧凑模型规模的同时,实现了领先的生成性能与更快的推理速度。
开源三大模型版本
本次开源包含三个核心版本:
Lens-Base:预训练基础模型,具备强大的 prompt following 能力和多场景图像生成能力。
Lens-RL:在 Lens-Base 基础上经过 RL 后训练优化,进一步提升图像质量、视觉一致性、物理合理性和 prompt 对齐能力。
Lens-Turbo:4-step inference 的高速蒸馏版本,无需 CFG,即可实现极快的图像生成速度。
超快推理:1024 分辨率图像最快 0.84 秒生成
Lens 不仅训练效率高,推理速度也非常快。在单张 NVIDIA H100 GPU 上:Lens 默认 20-step 推理生成一张 1024 分辨率图像仅需 3.15 秒;Lens-Turbo 使用 4-step inference,生成一张 1024 分辨率图像仅需 0.84 秒。这使得 Lens 非常适合高效率内容创作、设计辅助、交互式图像生成以及需要快速迭代的应用场景。
支持高分辨率与灵活长宽比生成
Lens 支持最高到 1440 分辨率的图像生成,并且可以在 1:2 到 2:1 的长宽比范围内进行任意比例生成。这意味着用户可以灵活生成海报、横幅、社交媒体配图、竖版封面、宽屏视觉图、设计素材等多种不同版式,而无需受限于固定分辨率或固定比例。
多语言 Prompt 输入与 Reasoner 支持
虽然 Lens 的训练数据主要基于英文 dense caption,但得益于强语言编码器和系统设计,Lens 支持多语言 prompt 输入,包括中文、英文、日文、法语等多种常用语言。
此外,Lens 还引入了 Reasoner 模块。Reasoner 可以将用户较为含混、简短或不完整的输入,自动转化为更加明确、详细、适合生成模型理解的 prompt。例如,用户只需要输入一个简单想法,Reasoner 就可以帮助补全场景、风格、主体、构图和细节描述,从而提升最终图像质量和 prompt 对齐效果。
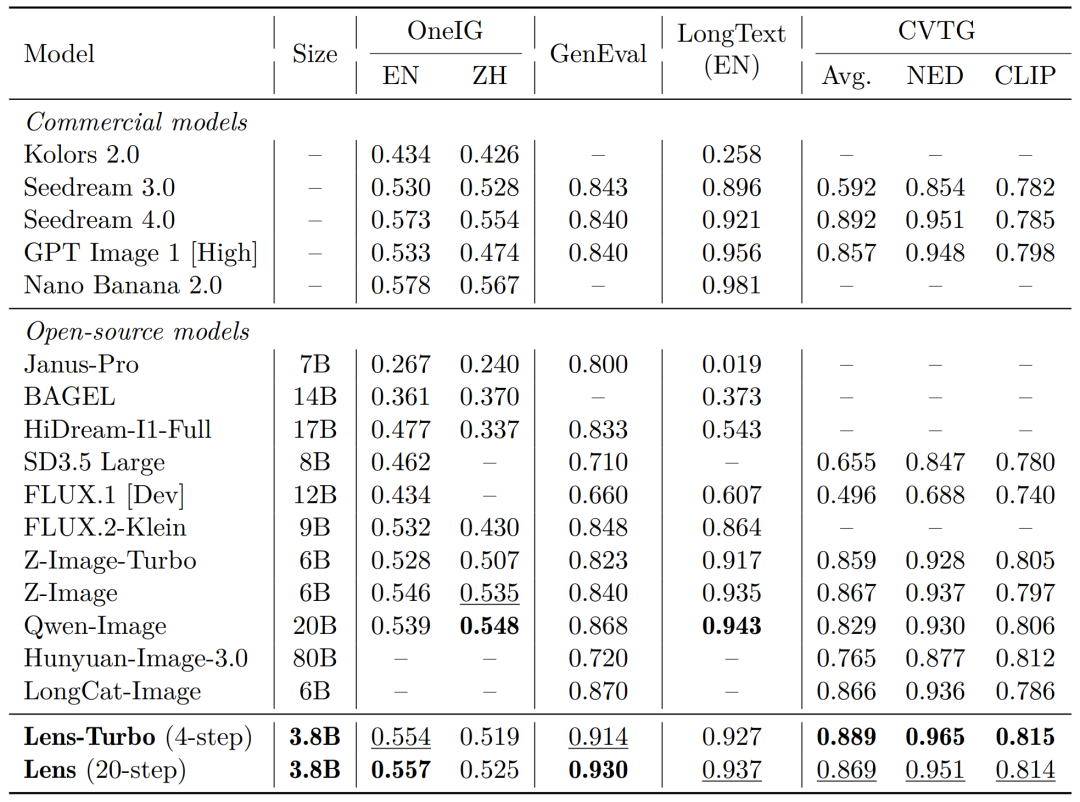
图3:Lens 与主流文生图模型的 Benchmark 对比。 Lens 在 3.8B 参数规模下,在 OneIG、GenEval、LongText 和 CVTG 等多个 benchmark 上取得了与更大模型竞争甚至领先的性能。
技术亮点
Lens 的高效训练能力主要来自以下几个方面:
第一,Lens 使用 3.8B 参数规模,在保证强生成能力的同时显著降低每一步训练和推理的计算成本。
第二,Lens 构建了大规模高质量预训练数据集 Lens-800M,并使用 GPT-4.1 生成 dense caption,使每个图文样本包含更丰富的语义信息,从而提升数据利用效率。
第三,Lens 采用多分辨率、多长宽比混合训练策略,使模型具备优秀的分辨率和长宽比泛化能力。
第四,Lens 通过语义 VAE、强语言编码器、RL 后训练、Reasoner 和 few-step distillation 等系统化设计,进一步提升模型收敛速度、生成质量和推理效率。
总结
Lens 证明了基础文生图模型不一定必须依赖极大规模参数和极高训练成本。通过提升数据密度、优化模型架构、改进训练策略和引入系统级后训练优化,3.8B 的 Lens 也可以达到 SOTA 级别的生成效果。本次微软开源 Lens-Base、Lens-RL 和 Lens-Turbo,希望为社区提供一个高质量、高效率、易部署的文生图基础模型,推动图像生成技术在研究、创作和实际产品中的进一步发展。
本文系学术转载,如有侵权,请联系CVer小助手删文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号