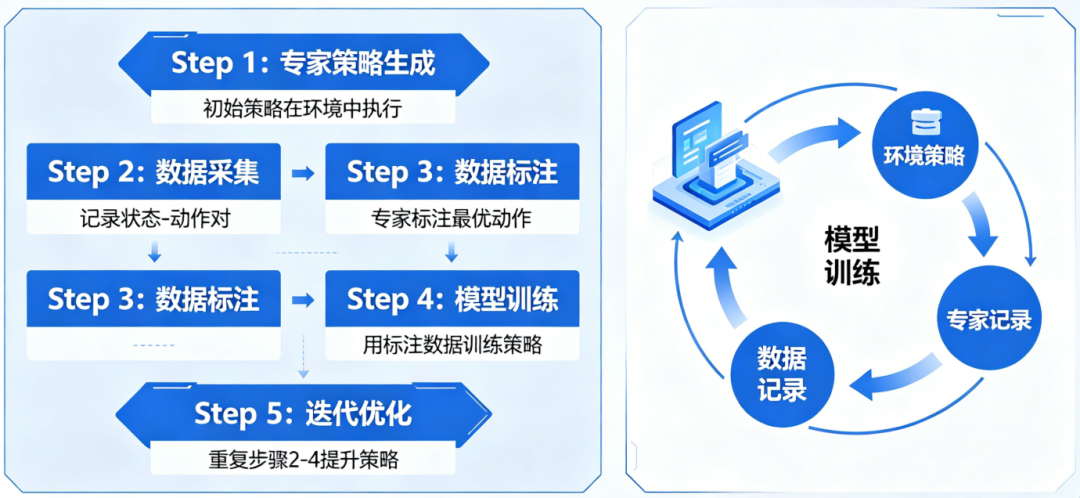
数据集聚合(DAgger:模仿学习)的原理和步骤


PART 01
核心原理
行为克隆(BC) 失败的根因: 训练时只见过专家的状态分布,测试时策略偏离专家轨迹后,进入从未见过的状态,错误逐帧累积,一发不可收拾。
数据集聚合( DAgger )的解法: 让专家在策略自己跑出的状态上打标签 ,把训练分布逐步扩展到策略实际会访问的状态空间。
本质是一个 闭环 :训练策略 → 让策略跑 → 专家标注 → 合并数据 → 重新训练。
PART 02
数学保证
BC 的累积误差上界 是 O(T2ϵ)( T 是轨迹长度),DAgger 在线性近似下可降 到 O(Tϵ) 。直觉上:每次迭代都在"修补"策略会犯错的区域。
算法:DAgger
输入:专家策略 π_expert,环境 env,迭代次数 N
输出:策略 π_θ
1. D_0 ← 用 π_expert 采集 n 条轨迹,得到 {(s, π_expert(s))} 数据集
2. for i = 0 to N-1:
2.1 在 D_i 上训练行为克隆策略 π_i
2.2 用 π_i 在环境中跑 n 条轨迹,收集状态序列 {s_t}
(注意:只收集状态,不用 π_i 的动作)
2.3 对每个收集到的状态 s_t,查询专家动作:a_t = π_expert(s_t)
→ 得到新标注数据 D_new = {(s_t, a_t)}
2.4 合并:D_{i+1} = D_i ∪ D_new
3. 在 D_N 上最终训练,返回 π_θ训练策略
π i 就是标准的行为克隆模型——用当前数据集 D i 做一次监督训练
训练 π_i(D_i):
策略网络 π = MLP() 或 ResNet()
优化器 = Adam(π, lr=1e-3)
for epoch = 1 to N:
for (s, a) in D_i: # D_i 是累积数据集
a_pred = π(s)
loss = MSE(a_pred, a) # 连续动作
# 或 CrossEntropy # 离散动作
loss.backward()
optimizer.step()
# 在验证集上早停
if val_loss 连续上升:
break
返回 πPART 03
关键设计决策
决策点 | 常见做法 | 原因 |
|---|---|---|
专家标注比例 | 不需要 100%,可按概率 β 随机标注 | 降低标注成本,β 可随迭代递减 |
迭代次数 | 通常 3-5 轮就收敛 | 边际收益快速递减 |
每轮数据量 | 与初始数据集等量 | 保证新状态有足够权重 |
是否保留旧数据 | 保留全部 | 旧数据防止遗忘 |
带随机标注的 DAgger 伪代码
for i = 0 to N-1:
π_i = train_BC(D_i)
new_data = []
for episode = 1 to n:
s = env.reset()
while not done:
a = π_i(s) # 策略自己选动作
s_next, _, done, _ = env.step(a)
if random() < β_i: # β_i 随迭代递减(如 β_i = 1.0 / (i+1))
a_expert = π_expert(s) # 仅在这些状态上问专家
new_data.append((s, a_expert))
s = s_next
D_{i+1} = D_i ∪ new_dataDAgger 的代价
优势:
- 理论上有收敛保证
- 实践中 2-3 轮迭代就能显著改善 BC
- 实现简单,在 BC 基础上加个循环即可
劣势:
- 需要专家在线,这是最大瓶颈——真实场景中专家标注成本很高
- 迭代早期策略很差,可能跑出危险/无意义的状态,专家标注负担重
- 如果专家标注有噪声(人类专家手抖),会被错误数据污染
特点:
数据合并方式
D{i+1} = Di ∪ D_new # 保留所有历史数据
错误做法:D{i+1} = D_new # 只用新数据 → 灾难性遗忘迭代间是否重新初始化网络
每轮重新训练(从头初始化) | 稳定,但慢 | ✅ 推荐 |
|---|---|---|
在上一轮 π_i 基础上继续训练 | 快,但可能遗忘旧数据 | ⚠️ 数据量小时可用 |
数据集变大后的训练策略
随着迭代进行,D_i 会越来越大。工程上:
- 每轮 随机采样 固定数量样本训练(如固定 10000 条),防止训练时间过长
- 或者 给新数据更高采样权重 ,类似 priority replay
PART 04
工程上的实用变体
由于"专家在线"成本太高,实际工程中常用这些变体来降低成本:
变体 | 做法 | 适用场景 |
|---|---|---|
β-Dagger | 随机子采样标注,β 逐轮递减 | 标注预算有限 |
Reverse DAgger | 从简单→困难的课程学习顺序 | 专家标注成本高 |
Filter DAgger | 只在策略不确定的状态上请求标注(低置信度采样) | 大幅减少标注量 |
GAIL(无标注) | 用判别器替代专家,不需要人工标注 | 无法获得专家标注时 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号