Nat Mach Intell | 在化学空间的边缘:AI 如何对从未见过的分子做出可靠预测

Nat Mach Intell | 在化学空间的边缘:AI 如何对从未见过的分子做出可靠预测

MindDance
发布于 2026-06-08 13:49:23
发布于 2026-06-08 13:49:23
原文:Molecular deep learning at the edge of chemical space 期刊:Nature Machine Intelligence, 2026 团队:荷兰埃因霍温理工大学 Francesca Grisoni 课题组
一个让 AI 药物发现头疼的悖论
机器学习正在重塑早期药物发现。但有一个根本性的矛盾横亘在中间——我们最想要的,恰恰是模型最不擅长的。
药物研发追求的是结构新颖的活性分子(hits):它们能填补未被满足的临床需求、绕开已有专利、克服耐药性。换句话说,真正有价值的发现往往位于已知化学空间之外。
可机器学习模型偏偏在面对训练数据之外的分子(也就是我们平时一直说的OOD)时频频失手。这个问题对分子尤其严重——分子是离散数据,稍微改动一个原子或一个环系,就可能跳出模型学过的分布。
雪上加霜的是数据稀缺。高质量的活性标注实验昂贵又耗时,训练集往往只有几百个分子;而真正要筛选的化合物库,动辄数十亿。一边是几百个见过的分子,一边是数十亿个没见过的分子,这种巨大的分布漂移,让用机器学习发现结构新颖的先导化合物成了一项近乎西西弗斯式的任务。
于是问题变成了:当模型走到它所探索过的化学空间的边缘之外,我们凭什么相信它的预测?
这篇论文给出了一个相当优雅的答案:一个叫做不熟悉度(unfamiliarity)的新指标。
一、过去是怎么处理这个问题的?
在介绍新方法之前,先看看人们过去走的两条路。
第一条是适用域(applicability domain)。简单说,就是在化学空间里给训练数据画一个圈,圈内的分子被认为可以可靠预测,圈外的就是 OOD。这个圈通常用与训练分子的相似度阈值来定义。它的问题是:完全没有用到模型自己学到的信息,而且因为本质上基于相似度,反而会把结构新颖的分子统统挡在门外——这恰恰与寻找新分子的目标背道而驰。
第二条是不确定性估计(uncertainty estimation)。它利用模型自身的预测置信度,通常通过概率建模实现。这条路理论上允许考虑结构新颖的分子,但有个致命弱点:面对 OOD 样本时,它常常给出过度自信的预测。模型可能信誓旦旦地告诉你某个它从未真正理解的分子是活性的,而你却无从分辨。
两条路各有各的盲区。这篇论文要补上的,正是中间那块拼图。
二、核心洞见:会复述,才是真懂
这篇论文的关键想法,藏在一个看似简单的类比里:
一个真正理解某样东西的人,能够凭记忆把它准确地复述或重画出来;而对于一知半解的东西,复述往往支离破碎。
把这个直觉搬到分子上:如果一个模型能把某个分子压缩进自己的内部表示,再解压还原成原来的样子,那说明这个分子对模型来说是熟悉的;反之,如果还原得乱七八糟,说明这个分子落在了模型学过的分布之外。
基于这个假设,作者提出用重建能力(reconstruction ability)作为衡量分子是否 OOD 的直接代理指标,并由此定义了不熟悉度。
这其实是对一个传统做法的反转。在生成式化学里,自编码器的重建任务通常是为了生成新分子,或者提升预测性能;而这篇论文把重建质量本身拿来当作 OOD 检测的信号。
三、方法:联合分子模型
具体怎么实现?作者搭建了一个叫做联合分子模型(Joint Molecular Model,JMM)的架构。它本质上是一个半监督的自编码器,可以拆成三个部分:
编码器:分子先被表示成 SMILES 字符串(一种用文本编码分子拓扑与原子、键类型的方式)。然后一个一维卷积神经网络(1D-CNN)把 SMILES 编码成一个压缩的潜在向量 z。
解码器:一个带长短期记忆(LSTM)的循环神经网络,把潜在向量 z 再解码回 SMILES 字符串。
预测头:同样的潜在向量 z,被送进一个近似贝叶斯分类器,用来预测分子性质(比如生物活性),同时估计预测的不确定性。
关键在于联合二字:重建任务和性质预测任务共享同一个潜在表示 z,并且一起训练。这样既保证了潜在空间同时为两个任务编码了相关信息,又让重建质量能够反映模型对这个分子的理解程度。
整个编码器-解码器先在 ChEMBL 的约 120 万个无标注分子上做了预训练,让模型先学会 SMILES 字符串的语法,然后用每个带标注的数据集做微调。
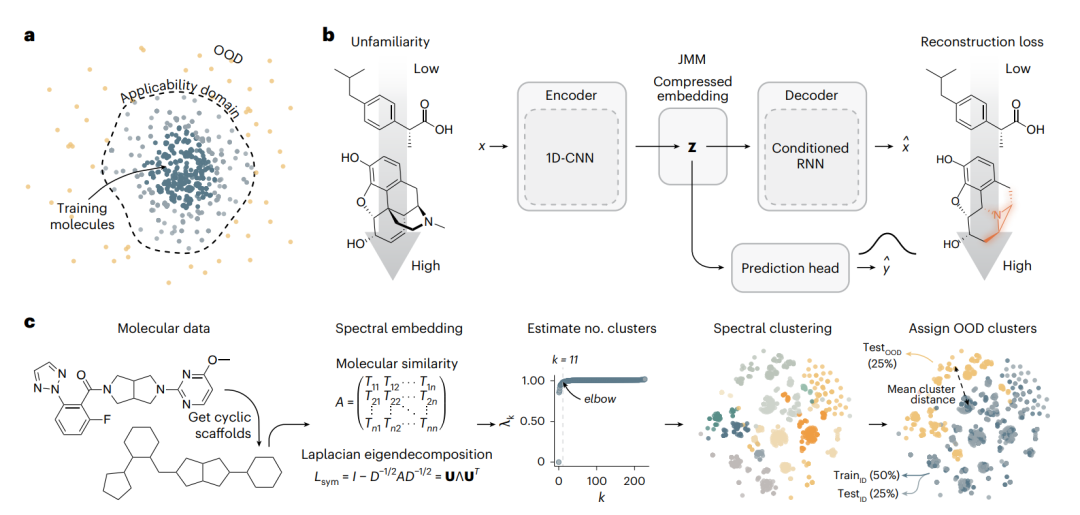
图 1 | 用联合建模估计分子数据的不熟悉度。a,适用域的概念示意:在化学空间中靠近训练数据的分子位于模型适用域内,边界之外的分子被视为 OOD。b,JMM 的架构:通过重建损失估计一个分子对模型有多不熟悉。c,通过谱聚类把分子数据分成同分布组与 OOD 组,从而制造分子分布漂移(以 OX2R 数据集为例)。
图 1 | 用联合建模估计分子数据的不熟悉度。a,适用域的概念示意:在化学空间中靠近训练数据的分子位于模型适用域内,边界之外的分子被视为 OOD。b,JMM 的架构:通过重建损失估计一个分子对模型有多不熟悉。c,通过谱聚类把分子数据分成同分布组与 OOD 组,从而制造分子分布漂移(以 OX2R 数据集为例)。
不熟悉度的数学定义其实很直接。重建损失被定义为所有 SMILES token 的负对数似然(按 token 长度归一化),而不熟悉度就是重建损失取对数:
重建损失越低,不熟悉度越低,反之亦然。一句话:模型把这个分子还原得越糟,它对这个分子就越不熟悉。
四、它真的管用吗?检测分布漂移
光有想法不够,得验证它真的有效。
作者收集了 33 个带实验标注的数据集,覆盖各种生物学性质和规模。为了制造可控的分布漂移,他们用了一个巧妙的办法:先对分子的环骨架(去掉环外取代基的核心环系)做谱聚类,保证结构相似的分子被聚到一起;然后把彼此距离最远的那些簇(约占 25% 的分子)拿出来作为 OOD 测试集(testOOD),剩下的分成训练集(trainID,约 50%)和同分布测试集(testID,约 25%)。
第一个问题:这样划分出来的 testOOD,真的和其他两组来自不同分布吗?作者用三种互补的相似度度量(ECFP 指纹相似度、结构核心重叠 MCS、CATS 药效团相似度)验证,结果一致:testOOD 与训练集、testID 之间都有统计显著的差异,而训练集和 testID 之间没有差异。分布漂移制造成功。
第二个问题:这种漂移真的会损害预测性能吗?会。作者训练了几个成熟的基线模型(随机森林加 ECFP、多层感知机加 ECFP、随机森林加 CATS),它们在 testOOD 上的表现一致地比 testID 差。这正是 OOD 数据的典型特征。
真正的考验:作者在每个数据集上算出所有分子的不熟悉度,看 testOOD 和 testID 有没有区别。结果非常清晰:testOOD 分子的不熟悉度显著高于 testID 分子。
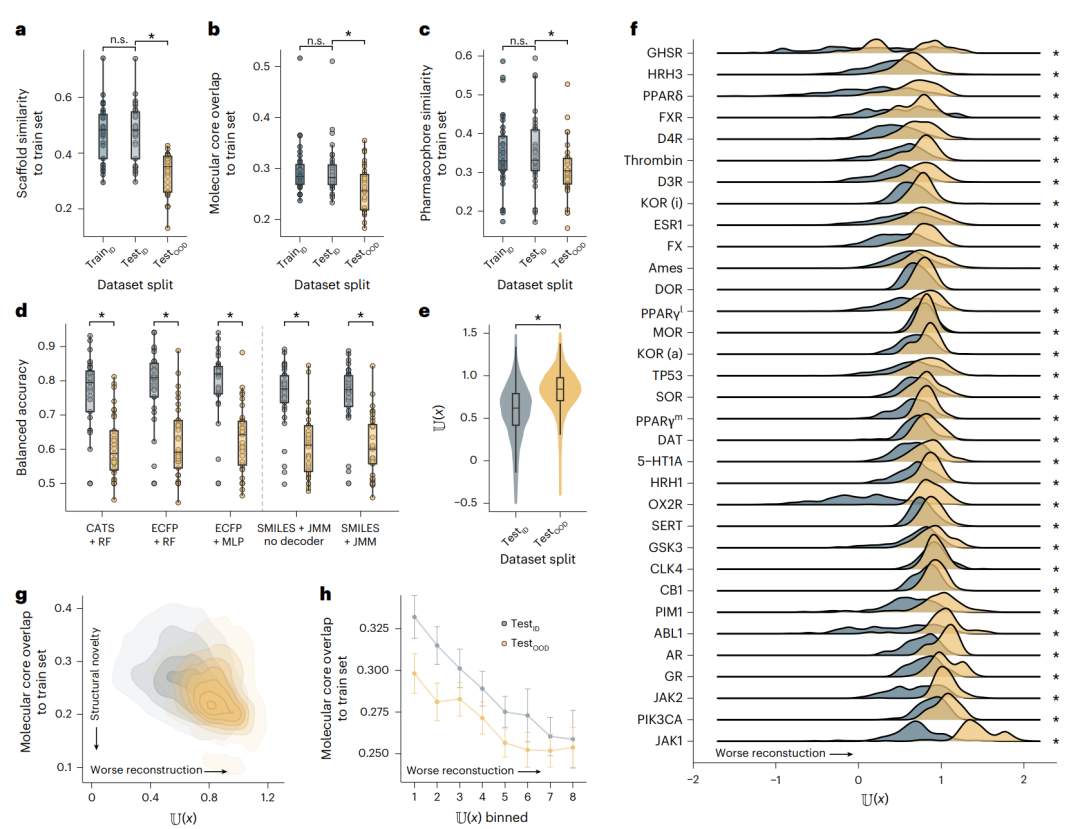
图 2 | 用不熟悉度检测人为制造的分子分布漂移。a–c,三种相似度度量下各数据划分相对训练集的相似度(testOOD 显著低于 testID 与 trainID)。d,各基线模型与 JMM 在测试集上的预测性能(性能在 testOOD 上一致下降)。e,所有数据集中 testID 与 testOOD 分子的不熟悉度分布(testOOD 显著更高)。f,逐数据集的不熟悉度分布。g–h,不熟悉度与分子核心重叠相似度的关系。星号表示统计显著差异,n.s. 表示不显著。
图 2 | 用不熟悉度检测人为制造的分子分布漂移。a–c,三种相似度度量下各数据划分相对训练集的相似度(testOOD 显著低于 testID 与 trainID)。d,各基线模型与 JMM 在测试集上的预测性能(性能在 testOOD 上一致下降)。e,所有数据集中 testID 与 testOOD 分子的不熟悉度分布(testOOD 显著更高)。f,逐数据集的不熟悉度分布。g–h,不熟悉度与分子核心重叠相似度的关系。星号表示统计显著差异,n.s. 表示不显著。
更重要的是一个排除性的发现:这种不熟悉度的差异,并不是由 SMILES 字符串长度、复杂度、分支数、分子图复杂度、分子量或官能团数量驱动的。换句话说,模型重建分子的能力,取决于这个分子离训练分布有多近,而不是这个分子本身有多复杂。这正是不熟悉度作为 OOD 指标的合理性所在。
顺带一提性能问题:JMM 在 testID 上的平衡准确率是 0.75,略低于纯 ECFP 模型的 0.78,但差距很小,与现有文献中 SMILES 模型与 ECFP 模型的对比一致。而且关键是:加不加重建解码器,对分类性能没有影响。也就是说,解码器让我们近乎免费地获得了不熟悉度估计,而没有牺牲分类器的性能。
五、和其他指标比,强在哪?
不熟悉度好用吗?作者把它和三类成熟的可靠性度量做了系统对比:数据驱动的训练集相似度、模型驱动的嵌入距离(分子 z 向量到训练集嵌入的马氏距离)、以及模型驱动的预测不确定性。
几个关键结论值得拎出来说。
第一,所有这些指标都和模型性能相关,但不确定性和不熟悉度的相关性最强。当不确定性或不熟悉度高时,模型的活性预测错误更多;反之则预测更准。
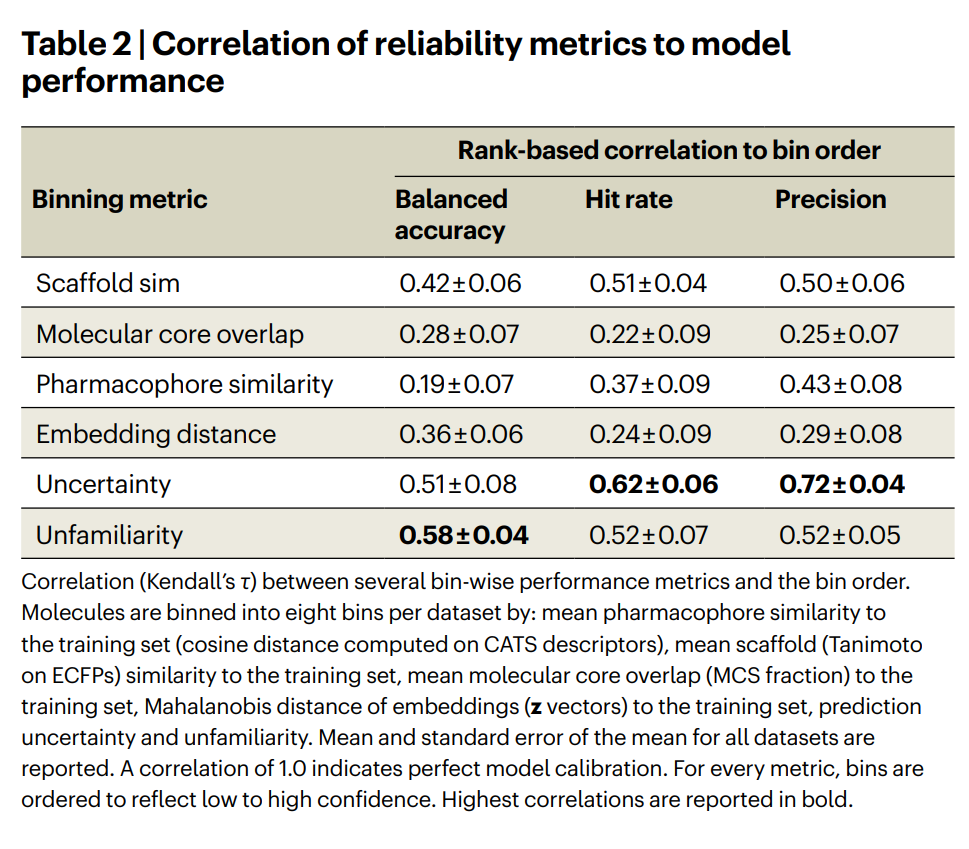
表 2 | 各可靠性指标与模型性能的相关性。各指标(用于分箱)与平衡准确率、命中率、精确率之间的秩相关(Kendall's τ)。相关系数为 1.0 表示完美校准。最高相关性以粗体标出。
表 2 | 各可靠性指标与模型性能的相关性。各指标(用于分箱)与平衡准确率、命中率、精确率之间的秩相关(Kendall's τ)。相关系数为 1.0 表示完美校准。最高相关性以粗体标出。
第二,也是最有意思的一点:不熟悉度和不确定性这两个指标本身几乎不相关(Spearman 相关系数仅 0.10)。这意味着它们捕捉的是关于预测可靠性的互补信息——这正是引入不熟悉度作为不确定性补充的理由。两个指标可以并用,从两个不同角度判断同一个预测靠不靠谱。
第三,模型驱动的指标全面优于数据驱动的指标。这说明模型能从训练数据里提取出预定义的相似度度量无法捕捉的信息。
第四,不熟悉度甚至比嵌入距离更好。这有点反直觉——嵌入距离用的是分类器直接使用的内部分子表示,按理说应该很有信息量。但结果是:一个模型能否从内部表示重建出分子,比这个内部表示本身更能反映预测的可靠性。简单的嵌入距离度量,捕捉不到那些影响具体任务结果的化学细微差别。
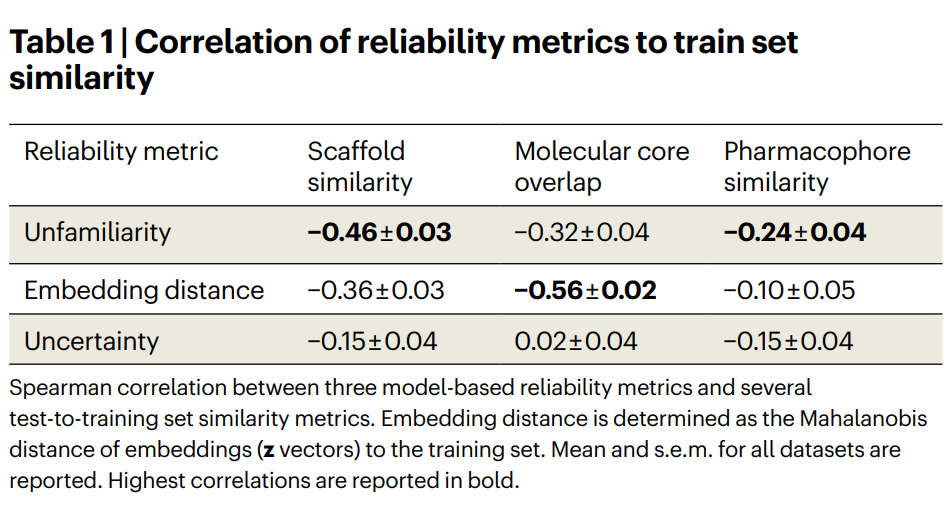
表 1 | 三种模型驱动的可靠性指标与训练集相似度的相关性。不熟悉度、嵌入距离、不确定性分别与三类测试集-训练集相似度之间的 Spearman 相关系数。最高相关性以粗体标出。
表 1 | 三种模型驱动的可靠性指标与训练集相似度的相关性。不熟悉度、嵌入距离、不确定性分别与三类测试集-训练集相似度之间的 Spearman 相关系数。最高相关性以粗体标出。
作者用一个漂亮的概率视角总结了三者的区别:嵌入距离主要反映 p(x)(分子本身的分布),不确定性关联 p(y|x)(给定分子的标签分布),而不熟悉度整合了两者,提供了对 p(y, x|x) 的洞察。这让不熟悉度成为一个把结构信息与预测置信度联系起来的整体性可靠性指标。
六、放到真实的大规模筛选里,差异更戏剧
小数据集上的结论,在真实的大规模筛选场景里还成立吗?
作者把分析扩展到了 140 万个分子(来自 Asinex、Specs、Enamine 三个商业筛选库)。这些库虽然没有活性标注,无法直接评估性能,但分子数量更大、更多样,更接近真实的虚拟筛选场景。
结果揭示了不熟悉度和不确定性之间一个相当戏剧性的差异。
筛选库的分子和训练集的结构重叠,比 testOOD 还要低。按之前的结论,这意味着我们应该预期性能会进一步下降。
但是,预测不确定性几乎没察觉到这种分布漂移。不确定性在筛选分子和 testID 分子之间的差异很小(KS 统计量 D = 0.181,效果微弱)。如果只看不确定性,你会以为这 140 万个分子都在模型的操作范围之内——这显然是个危险的误判。
而不熟悉度则清晰地揭示了强烈的分布漂移(KS 统计量 D = 0.999,几乎是满分)。
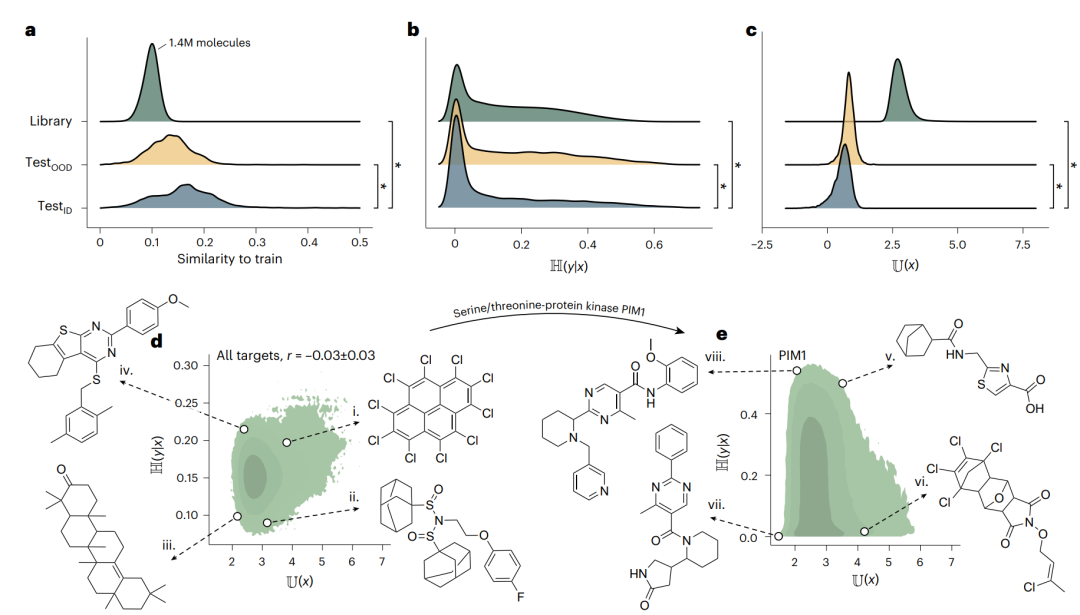
图 3 | 在 140 万个商业可得分子上的虚拟筛选。a,testID、testOOD 与筛选库分子相对训练集的 Tanimoto 相似度分布。b,三组分子的预测不确定性分布(筛选库与 testID 差异很小,D = 0.181)。c,三组分子的不熟悉度分布(筛选库与 testID 差异极大,D = 0.999)。d,所有靶点上不确定性与不熟悉度的关系;e,针对 PIM1 激酶的对应关系。其中标注了几个被预测为广谱活性的分子。
图 3 | 在 140 万个商业可得分子上的虚拟筛选。a,testID、testOOD 与筛选库分子相对训练集的 Tanimoto 相似度分布。b,三组分子的预测不确定性分布(筛选库与 testID 差异很小,D = 0.181)。c,三组分子的不熟悉度分布(筛选库与 testID 差异极大,D = 0.999)。d,所有靶点上不确定性与不熟悉度的关系;e,针对 PIM1 激酶的对应关系。其中标注了几个被预测为广谱活性的分子。
这个对比太有说服力了。同一批数据,不确定性视而不见,不熟悉度一目了然。这正印证了之前文献的担忧:不确定性估计在强 OOD 数据上是不可靠的。
而且,不熟悉度揭示的分子洞察是有化学意义的。高不熟悉度的分子往往结构非典型(比如一些奇怪的多卤代结构);低不熟悉度的分子则展现出生物活性分子的典型特征——类固醇骨架、已知的活性核心(比如针对 PIM1 激酶时,低不熟悉度的分子含有嘧啶酮等知名药效团)。
还有一个重要的排除:不熟悉度和药物相似性(QED)、合成可及性都没有关系。这说明低不熟悉度并不是简单地在捕捉这个分子像不像药——它捕捉的是更深层的、与模型学到的分布相关的东西。而所有这些结构洞察,都是不确定性估计无法提供的。
七、搬进湿实验室的前瞻性验证
到这里,所有结论都还停留在计算层面。这篇论文最有分量的部分,是把方法搬进了真实的湿实验室。
作者针对两个有药理学意义的激酶靶点做了前瞻性虚拟筛选:PIM1 和细胞周期蛋白依赖性激酶 1(CDK1)。特别值得一提的是,CDK1 的数据完全没有在研究的其他任何地方用过,是一个彻底独立的测试案例。
对每个靶点,作者用全部可用数据训练了一个 JMM(PIM1 有 1443 个训练分子,CDK1 只有 312 个),然后在约 18 万个药物样分子的商业库上预测活性。
分子的排序用了一个多目标优化的办法——计算每个分子到乌托邦点(utopia point,多个目标的几何最优)的距离。三个目标分别是预测活性、预测不确定性、不熟悉度。作者故意设计了三种不同的权衡组合,来观察不确定性和不熟悉度在分布漂移下各自的表现:
- 方法 A:高活性、高不确定性、低不熟悉度
- 方法 B:高活性、低不确定性、低不熟悉度
- 方法 C:高活性、低不确定性、高不熟悉度
为了把模型逼到训练分布之外,作者还做了一道额外的过滤:凡是与训练集或与已选分子的 Tanimoto 相似度大于等于 0.70 的化合物,统统排除。最终选出的 60 个分子(每个靶点 30 个,每种方法 10 个),全都与各自的训练集结构相距甚远——最大 Tanimoto 相似度只有约 0.28。
实验结果(在 10 µM 单浓度下测试):PIM1 拿到 4 个初步命中(抑制率大于 50%)加 6 个弱命中(抑制率大于 25%);CDK1 拿到 1 个初步命中加 5 个弱命中。
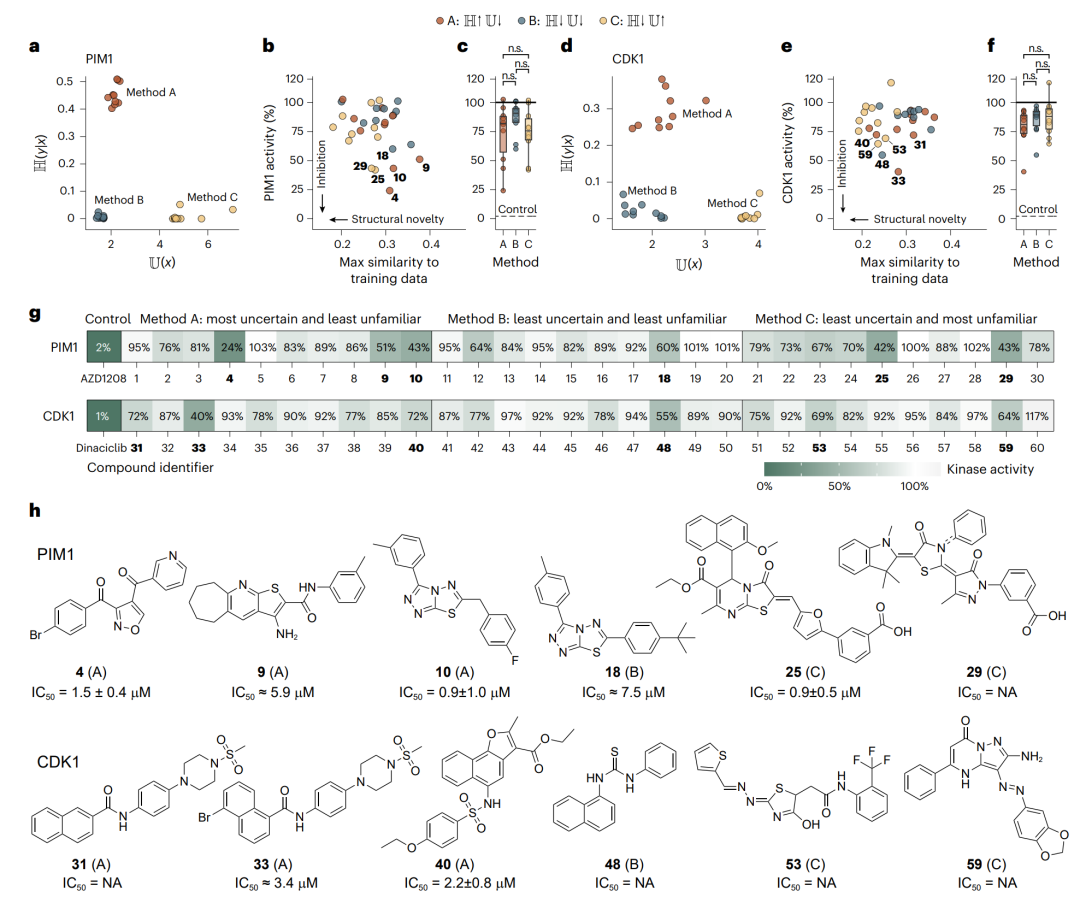
图 4 | PIM1 与 CDK1 的实验筛选。a 与 d,用三种不确定性-不熟悉度组合(方法 A/B/C)从约 18 万化合物中选出的十个最优分子。b 与 e,所选分子在 10 µM 下的实测激酶活性及其与训练分子的最大相似度(活性越低代表抑制越强)。c 与 f,各方法实测活性的箱线图。g,全部 60 个化合物在 10 µM 下的实测蛋白活性热图。h,PIM1 与 CDK1 各六个最有潜力化合物的结构与测定的 IC50(无法测定者标记为 NA)。
图 4 | PIM1 与 CDK1 的实验筛选。a 与 d,用三种不确定性-不熟悉度组合(方法 A/B/C)从约 18 万化合物中选出的十个最优分子。b 与 e,所选分子在 10 µM 下的实测激酶活性及其与训练分子的最大相似度(活性越低代表抑制越强)。c 与 f,各方法实测活性的箱线图。g,全部 60 个化合物在 10 µM 下的实测蛋白活性热图。h,PIM1 与 CDK1 各六个最有潜力化合物的结构与测定的 IC50(无法测定者标记为 NA)。
随后对每个靶点活性最高的 6 个化合物做了剂量-反应曲线和 IC50 测定。PIM1 的 6 个化合物都表现出剂量依赖的抑制,其中化合物 4、10、25 呈现清晰的 S 形部分抑制曲线,达到了低或亚微摩尔级的效力(IC50 分别约为 1.5 µM、0.92 µM、0.87 µM)。CDK1 这边因为训练集更小,抑制普遍较弱,只有化合物 40 给出了完整的剂量-反应曲线(IC50 约 2.9 µM)。
把这些数字放进背景里看才知道分量:这次筛选 PIM1 的命中率约 17%,CDK1 约 7%。而传统的激酶聚焦筛选活动,命中率通常只有 0.1% 到 5%。更难得的是,所有命中化合物与训练分子的最大子结构相似度都低于 38%,而且完全来自纯前瞻性的、机器学习引导的选择。
最关键的一个观察:7 个具有低微摩尔效力的化合物里,有 5 个来自选择方法 A(低不熟悉度、高不确定性)。而依靠低预测不确定性来选分子的方法 B 和 C,并没有带来明显优势。
这个结果意味深长。它说明在分布漂移下,低不熟悉度比低不确定性更能预示成功——即便这些分子按传统相似度看都很新颖,模型在它学到的表示空间里仍然觉得它们熟悉,而这种熟悉感才是预测可靠的真正信号。当然作者也诚实地指出,每种方法测试的化合物数量有限,也没有完整的 2×2 析因设计,所以无法得出统计上严格的结论。
八、它到底贡献了什么,又意味着什么?
退一步看,这篇论文真正提供的,是一个全新的视角来回答那个老问题:我们什么时候该相信一个分子机器学习模型的预测?
过去的两个答案——画相似度的圈(适用域)和看模型的置信度(不确定性)——各有各的盲区。不熟悉度补上了一块拼图:它通过模型重建分子的能力,同时捕捉了分子的结构距离和预测的可靠性。
更难得的是,它和不确定性是互补而非冗余的。两个指标各自都和性能相关,但彼此独立。这意味着你可以同时使用两者,获得对预测可靠性更立体的判断。
作者据此提出了几个明确的建议:用不熟悉度取代传统的、基于相似度的适用域定义;在筛选大规模分子库时采用不熟悉度,因为它能揭示那些被相似度忽略、被不确定性低估的分布漂移。更长远地看,因为不熟悉度的地形图实际上揭示了模型学到的分布里的空白区域,它有潜力指导强化学习,或者从一次性虚拟筛选拓展到主动学习这样的迭代式分子获取策略。
当然,这项工作也有它的边界。湿实验验证的化合物数量不多,CDK1 因训练集太小效果有限;命中的化合物虽然新颖且有活性,但目前还停留在微摩尔级,离真正的药物还有很长的路。但作为一个原理验证,它已经相当有说服力。
结语
回到开头那个悖论:我们最想要的,恰恰是模型最不擅长的。
这篇论文没有消除这个矛盾,但它给了我们一个诚实的工具——让模型自己告诉我们,它对眼前这个分子到底有几分把握。在化学空间那片广袤的、尚未绘入地图的疆域里,这样一盏诚实的灯,也许比一个盲目自信的向导要珍贵得多。
论文与数据:代码、数据已在 GitHub(molML/JointMolecularModel)、Zenodo 与 figshare 公开。本文为学习交流用途的解读,具体细节请以原文为准。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号