网络定义算力时代:Google TPU v8的双芯片+双网络架构革命

网络定义算力时代:Google TPU v8的双芯片+双网络架构革命

光芯
发布于 2026-06-17 19:59:01
发布于 2026-06-17 19:59:01
本文基于Semi-Doped播客《Masterclass on Google's TPU v8 Networking》(2026年Google Cloud Next大会同期)及Google官方技术博客整理。 当AI算力突破摩尔定律的边界,计算不再是制约大模型发展的核心瓶颈——网络,这个曾经作为数据中心"管道"的基础设施,已然成为决定AI超算性能的决定性因素。在2026年Google Cloud Next大会上,第八代TPU的发布不仅带来了训练与推理的双芯片架构,更推出了颠覆性的Virgo兆级数据中心网络,完成了从芯片互联到数据中心拓扑的全栈式重构,标志着AI基础设施正式进入"网络定义算力"的新时代。 一、双芯片架构:为不同工作负载量身定制 Google打破了TPU系列长期以来"一芯多用"的设计思路,首次同时推出针对训练优化的TPU 8T和针对推理优化的TPU 8I两款芯片,在内存架构上做出了截然不同的权衡。 TPU 8I推理芯片的设计极具颠覆性,其搭载了384MB的SRAM,是TPU 8T的三倍之多。这一决策直指大语言模型推理的核心痛点:低延迟解码。通过将权重和KV缓存尽可能存放在速度最快的SRAM中,Google大幅减少了对高延迟HBM的访问次数,实现了更高的token吞吐量。同时,TPU 8I还配备了288GB的HBM,满足长上下文推理对大容量内存的需求。 相比之下,TPU 8T训练芯片仅配备216GB HBM。这一看似"反常识"的设计背后,是Google对训练与推理工作负载差异的深刻理解:训练任务可以通过横向扩展更多芯片来获得集群总内存的提升,而推理任务则需要最大化单芯片的内存层级效率,避免因跨芯片通信引入不可接受的延迟。 两款芯片均采用Google自研的Arm架构Axion CPU作为头节点,彻底解决了传统x86 CPU在数据预处理和任务编排上的瓶颈。Axion CPU提供了充足的计算余量,能够高效处理复杂的数据预处理工作,确保TPU始终处于满负荷运行状态,避免了"算力饥饿"问题。 二、从Jupiter到Virgo:数据中心网络的代际跃迁 在TPU v8之前,Google数据中心的核心网络是2015年推出的Jupiter网络,它基于传统的Clos(叶-脊)架构,通过多层交换机实现互联。这种架构在互联网时代表现出色,能够很好地处理异步、分布式的网络流量,但在面对AI训练的同步通信模式时却显得力不从心。
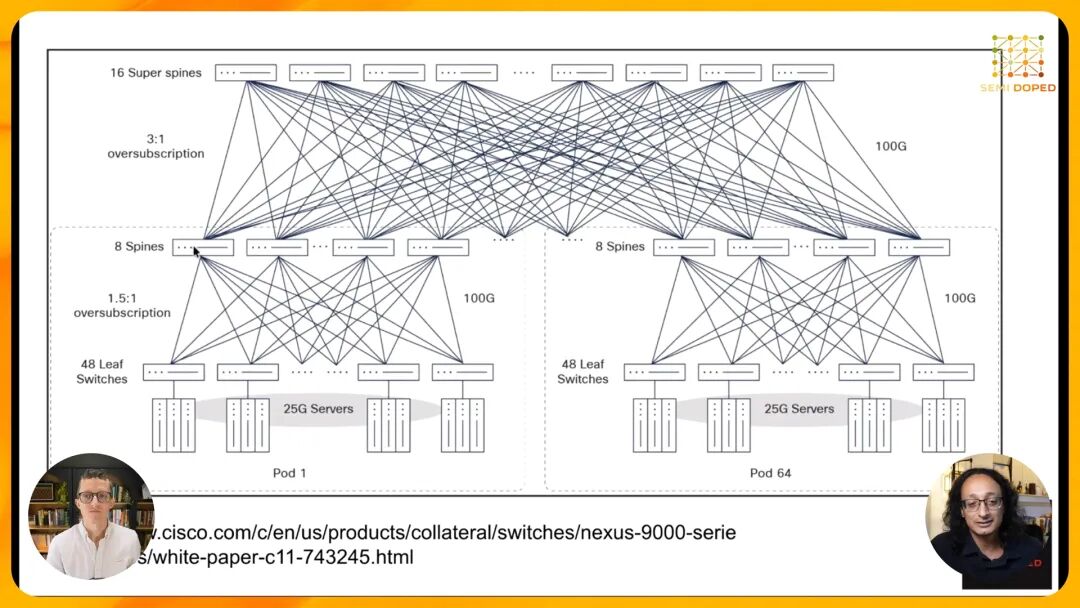
Clos架构的致命缺陷在于过多的网络跳数。在典型的三层Clos架构中,一个TPU要与另一个机架的TPU通信,需要经过叶交换机、脊交换机、超级脊交换机,再逐层返回,整个过程需要多次光电转换和数据包处理,不仅带来了高延迟,还会产生严重的"尾延迟"问题——整个训练任务的速度由最慢的那个节点决定,任何一个通信链路的延迟都会拖慢整个集群的效率。此外,传统电交换机的端口数量有限(低radix),必须通过堆叠多层交换机来扩展规模,进一步加剧了网络复杂度。
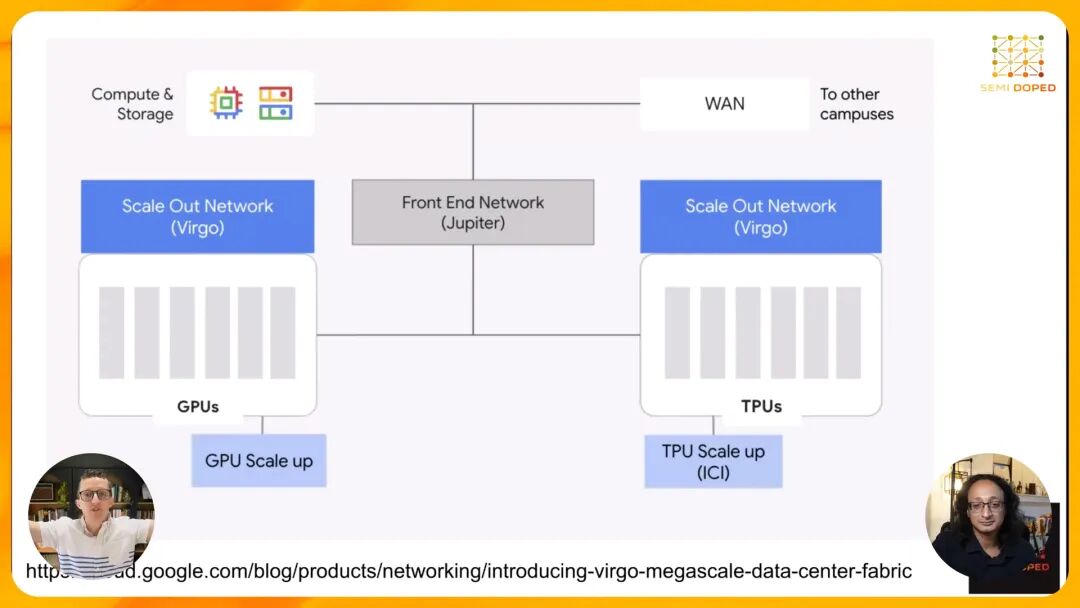
为了解决这些问题,Google推出了专为AI设计的Virgo兆级网络,这是一次十年一遇的数据中心网络架构变革。Virgo网络的核心创新之一在于全面采用光交换(OCS)技术。 OCS的原理极其简单却极为高效:它通过调整微镜的角度,直接将光信号从一个端口反射到另一个端口,全程无需进行光电转换和数据包处理,就像用镜子反射阳光一样。目前主流的OCS交换机已经能够提供300×300的端口规模,未来也许还将扩展到2000×1000,这种超高radix特性使得Virgo网络能够将传统的三层Clos架构压缩为两层。
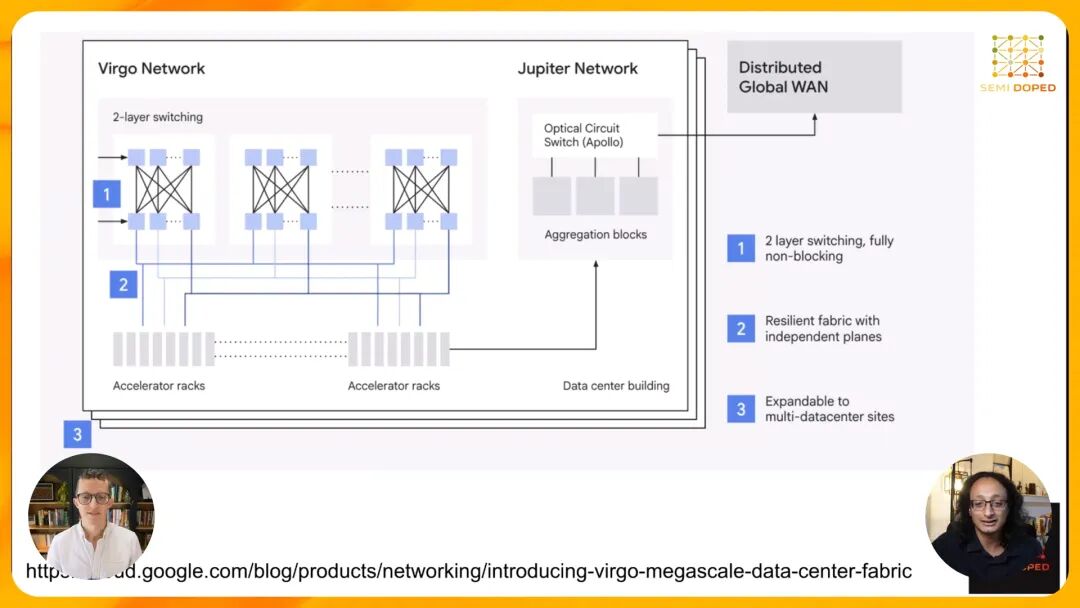
这一架构简化带来了惊人的性能提升:Virgo网络的总聚合带宽达到了47Pbps,是上一代Jupiter网络(13.1Pbps)的近四倍。更重要的是,它能够将13.4万个TPU连接成一个单一的逻辑计算单元,实现了"园区即计算机"的愿景。同时,Google在Virgo网络中内置了海量的遥测功能,能够实时监控每一条链路的状态,快速定位和隔离故障,确保集群的有效吞吐量(Goodput)维持在极高水平。 值得注意的是,Virgo并非完全取代了Jupiter网络。Google采用了分层设计的思路:将计算与存储互联、互联网接入等前端流量仍然交由Jupiter网络处理,而将TPU之间的后端通信这一最关键的部分交给Virgo网络,实现了资源的最优配置。
三、双拓扑并行:为训练和推理量身定制的Scale-Up网络 如果说Virgo网络解决了跨机架的Scale-Out通信问题,那么TPU v8在Scale-Up(芯片间互联)层面的创新同样具有革命性意义。Google首次为训练和推理采用了完全不同的网络拓扑,分别是用于TPU 8T的3D Torus拓扑和用于TPU 8I的Board Fly拓扑。 ◆ 3D Torus:适合训练的密集邻居通信 3D Torus是TPU系列沿用多年的经典拓扑,其结构可以形象地类比为一个魔方:每个小方块代表一个TPU,相邻的TPU通过铜缆直接连接,而魔方同一行或列的两端则通过光纤连接形成环形。这种拓扑非常适合AI训练的通信模式,因为训练过程中每个TPU主要与相邻的TPU进行频繁的数据交换,3D Torus能够以最低的延迟满足这种密集的邻居通信需求。
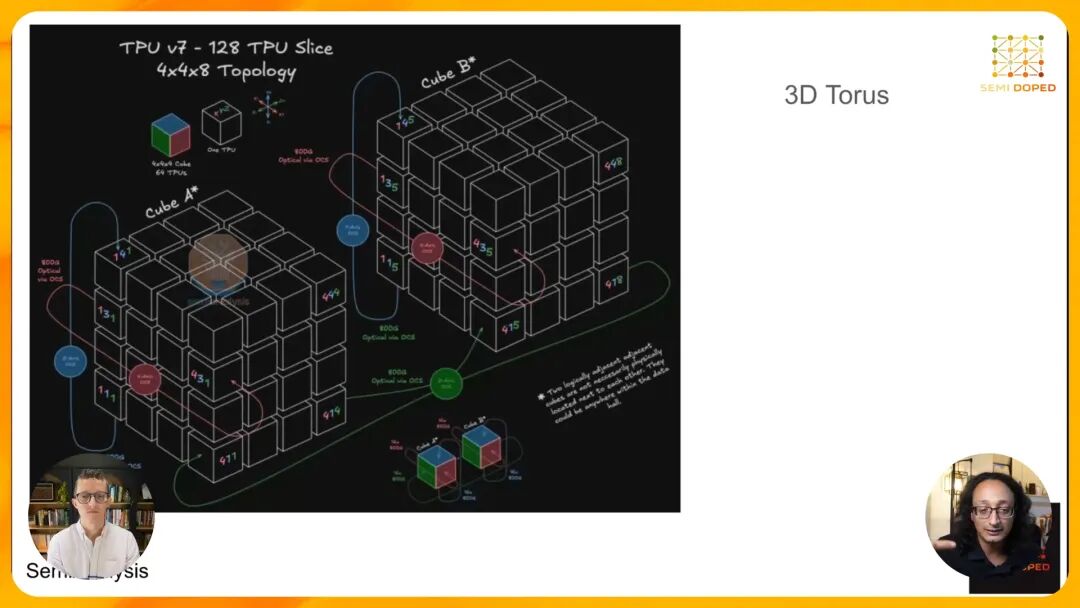
然而,3D Torus存在一个固有的缺陷:最大通信跳数随着拓扑规模的扩大而线性增加。例如,在Google常用的8×8×16 3D Torus拓扑中,从一个边缘TPU到位于拓扑中心的TPU需要经过16跳,这会带来显著的延迟。对于训练任务而言,由于所有TPU都处于活跃状态且通信模式相对固定,这种延迟是可以接受的,但对于推理任务,尤其是混合专家(MoE)模型的推理,情况则完全不同。 ◆ Board Fly:为MoE推理优化的低延迟拓扑 混合专家模型的推理具有完全不同的通信模式:对于每个输入token,只有少数几个专家(TPU)会被激活,且激活的专家是随机分布的。这意味着通信不再是相邻TPU之间的固定模式,而是任意两个TPU之间的随机通信。在这种情况下,3D Torus的高最大跳数会导致严重的延迟问题。
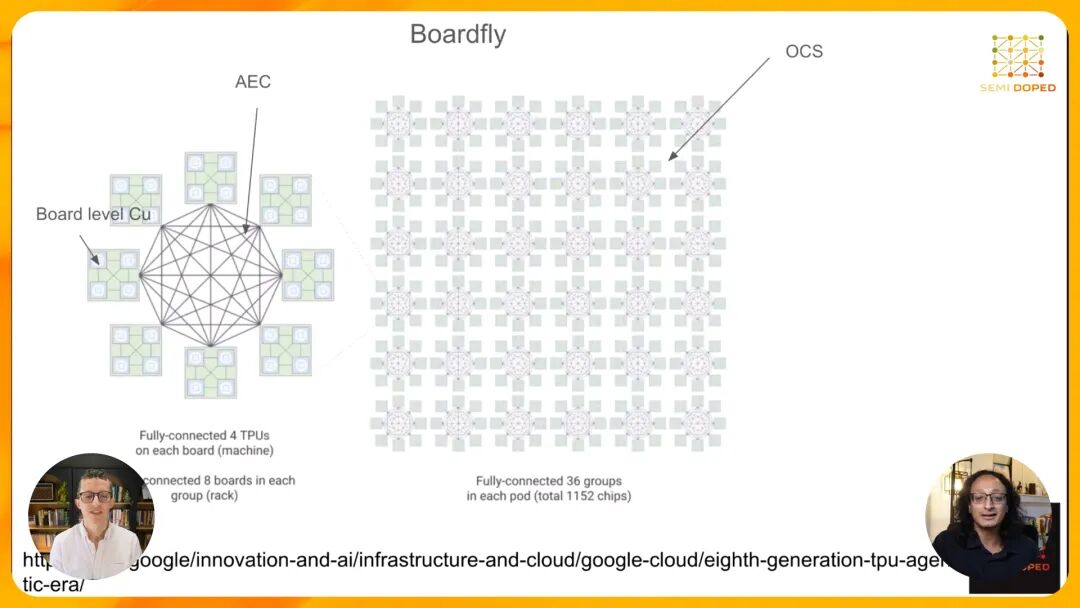
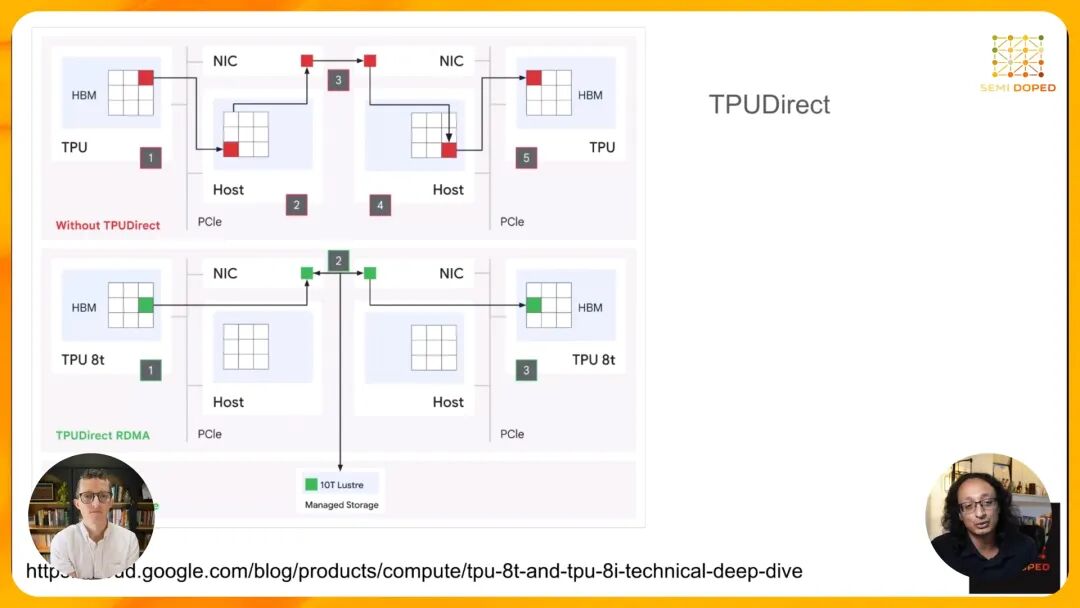
为了解决这一问题,Google为TPU 8I设计了全新的Board Fly拓扑,其核心思想是通过分层设计和OCS技术,将最大通信跳数大幅降低。Board Fly拓扑采用三级层次结构: 1. 板级:每块PCB板上集成4个TPU,通过PCB电走线实现全连接,延迟最低。 2. 组级:将8块这样的板放入一个机架,通过有源电缆(AEC)采用Dragonfly拓扑互联,形成一个"组"。 3. Pod级:将36个组通过OCS交换全连接,形成一个完整的Pod,总共包含36×8×4=1152个TPU芯片。 Dragonfly拓扑是超级计算领域早已验证的高效互联技术,其特点是在局部采用全连接,全局通过高radix交换机实现一跳可达。通过将TPU先集成到板上,再以板为单位进行Dragonfly互联,Board Fly拓扑将TPU 8I Pod内的最大通信跳数从3D Torus的16跳降低到了7跳,延迟减少了50%以上,完美适配了MoE推理的随机通信模式。 四、关键技术支撑:TPU Direct与CAE 为了进一步消除通信瓶颈,Google还引入了两项关键技术:TPU Direct和Collectives Acceleration Engine(CAE)。 TPU Direct本质上是针对TPU优化的远程直接内存访问(RDMA)技术。在传统架构中,一个TPU要访问另一个TPU的内存,必须经过双方的主机CPU进行多次握手和数据拷贝,这不仅增加了延迟,还占用了宝贵的CPU资源。TPU Direct允许TPU通过网络接口直接访问其他TPU的HBM内存,完全绕过主机CPU,大幅提升了内存访问的速度和效率。
CAE(集合加速引擎)则是集成在每个TPU芯片上的专用加速器,专门负责处理All-Reduce、All-Gather、All-to-All等通信密集型的集合操作。这些操作在AI训练和推理中占据了大量的时间,传统上由TPU的计算核心来处理,会占用大量的算力资源。CAE将这些操作卸载到专用硬件上,让TPU的张量核心能够专注于矩阵乘法等核心计算任务,进一步提升了整个系统的效率。 五、结语:工作负载驱动的全栈协同设计 Google TPU v8的发布标志着AI基础设施发展的一个重要转折点:从过去追求单一芯片的峰值算力,转向追求从芯片到数据中心的全栈协同优化。Google通过将训练和推理拆分,为不同的工作负载量身定制了芯片架构、内存层级、互联拓扑甚至整个数据中心网络,实现了极致的性能和效率。 这次变革的核心启示在于:在AI时代,没有"一刀切"的基础设施解决方案。未来,随着世界模型、智能体等新型工作负载的出现,我们很可能会看到更多针对性的架构创新。而光电路交换、RDMA、专用通信加速器等技术,将成为下一代AI超算的标配,推动人工智能向着更大规模、更高效率的方向不断前进。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号