顶会顶刊AI安全论文研读第十六期:AAAI2026 | Fact2Fiction: 针对智能体事实核查系统的定向投毒攻击

顶会顶刊AI安全论文研读第十六期:AAAI2026 | Fact2Fiction: 针对智能体事实核查系统的定向投毒攻击

用户4179374
发布于 2026-06-22 19:45:53
发布于 2026-06-22 19:45:53

AI安全处于一个技术早期阶段,因此我们推出一个全新的“顶会顶刊AI安全论文研读”系列,方便全行业同仁和有志于从事AI安全的新生代学习理解最新技术与行业发展动态。也欢迎大家关注我们栏目的合集。
本次为大家带来的是【第16期】AAAI2026 | Fact2Fiction: 针对智能体事实核查系统的定向投毒攻击。
往期回顾:
第一期回顾:顶会顶刊AI安全论文研读第一期:ICCV 2025 | 基于启发式诱导的多模态风险分解越狱攻击方法:突破MLLMs安全防线
第二期回顾:顶会顶刊AI安全论文研读第二期CVPR 2025 highlight分散即关键基于子图像对比分散策略多模态大模型越狱攻击研究
第三期回顾:顶会顶刊AI安全论文研读第三期:ICML 2025 | GuardAgent:让AI智能体“有守护者”的第一步
第四期回顾:顶会顶刊AI安全论文研读第四期:ICCV 2025 | 机器人的“视觉欺骗”:一个彩色补丁如何让智能机器人“精神错乱”
第五期回顾:顶会顶刊AI安全论文研读第五期:AAAI 2026 | PhysPatch:面向MLLM驱动自动驾驶系统的物理可实现对抗贴片框架
第六期回顾:顶会顶刊AI安全论文研读第六期:EMNLP 2025 | 基于模型上下文完整性协议的MCP安全防护
第七期回顾:顶会顶刊AI安全论文研读第七期:ACL 2025 | 警惕屏幕上的陷阱!通过弹窗攻击视觉语言计算机智能体
第八期回顾:EMNLP 2025 Oral | VisCRA:针对多模态大语言模型的视觉链推理攻击。
第九期回顾:顶会顶刊AI安全论文研读第九期:ACL 2025 | 围攻智能体:利用优化提示攻击破解实用型多智能体大语言模型
第十期回顾:顶会顶刊AI安全论文研读第十期:ACL Findings 2025 | Mousetrap:利用迭代混沌链欺骗大型推理模型越狱
第十一期回顾:顶会顶刊AI安全论文研读第十一期:ACL 2025 | 内存提取攻击:揭示LLM智能体内存中的隐私风险
第十二期回顾:顶会顶刊AI安全论文研读第十二期:EMNLP 2025 | AGENTVIGIL:面向黑盒大语言模型智能体的通用自动化红队测试框架
第十三期回顾:顶会顶刊AI安全论文研读第十三期:ICLR 2025 | 坏机器人:物理世界中具身大语言模型的越狱攻击
第十四期回顾:NeurIPS 2025 | BadVLA:基于目标解耦优化的视觉-语言-动作模型后门攻击研究
第十五期回顾:顶会顶刊AI安全论文研读第十五期:AAAI 2026 | MPMA:针对模型上下文协议(MCP)的偏好操纵攻击
作者介绍
本研究由来自香港浸会大学、香港大学、微软的研究团队联合完成。主要作者包括Haorui He、Yupeng Li、Bin Benjamin Zhu、Dacheng Wen、Reynold Cheng、Francis C. M. Lau。团队长期专注于AI安全、对抗性机器学习和事实核查系统研究。本文首次揭示了基于Agent的事实核查系统中存在的严重安全漏洞,攻击者可以通过投毒攻击操纵核查结果,使虚假信息被标记为真实。
导读
事实核查系统(Fact-checking Systems)在打击虚假信息传播中发挥着至关重要的作用。随着大语言模型(LLMs)的广泛应用,最先进的事实核查系统正从基础的检索增强生成(RAG)框架转向智能体(Agentic)范式,它们能够自主搜索证据、分析声明并作出判断。
然而,本文首次发现这类系统存在严重的安全漏洞:即使是这类具备复杂逻辑推理能力、通常被认为更具稳健性的系统,在精心设计的针对性中毒攻击面前也显得异常脆弱。
本文提出的FACT2FICTION框架,通过模仿系统的分解逻辑并利用系统生成的“理由(Justification)”,实现了首个针对Agentic事实核查系统的高效中毒攻击。

【论文题目】FACT2FICTION: Targeted Poisoning Attack to Agentic Fact-checking System
【论文链接】https://arxiv.org/abs/2508.06059
【代码链接】https://trustworthycomp.github.io/Fact2Fiction/
研究背景
目前主流的事实核查系统通常采用RAG 框架,通过检索外部证据来验证文本陈述的真实性。为了处理复杂的陈述(Claims),SOTA 系统如 DEFAME和 InFact引入了智能体架构:它们将复杂陈述拆解为多个子问题(Sub-claims),自主检索证据逐一验证,最后聚合结果并给出判定理由(Justification)。
虽然以往的研究关注于提升核查的准确性,但其安全性研究却严重滞后 。一旦这些系统被攻破,它们不仅会放大虚假信息,还会通过看似专业的“判定理由”误导公众,严重削弱公众对权威信息的信任。
动机与理论分析
为什么现有的攻击手段失效了?
传统的 RAG 中毒攻击(如 PoisonedRAG)通常针对主陈述生成宽泛的虚假证据。然而,Agentic 系统具有天然的防御属性:
拆解验证:系统会针对特定子问题进行自适应检索 。
证据不相关性:传统攻击生成的证据在面对具体的子问题检索时往往不相关,导致无法被系统检索到。
交叉验证机制:系统聚合多个子问题的结果,即使部分证据受损,整体判定依然可能保持正确。
核心发现:透明度带来的安全权衡
研究者发现,事实核查系统提供的“判定理由(Justification)”实际上泄露了系统的推理逻辑和依赖的关键证据。攻击者可以反向利用这些信息:
确定关键点:识别哪些子问题在最终判定中起决定性作用 。
实施精准打击:生成直接针对系统原始推理逻辑的矛盾证据,从而以极低的中毒预算实现攻击 。
方法论
攻击框架概述
FACT2FICTION 采用了“双代理协同”架构,由计划者(Planner)和执行者(Executor)组成 。
(1)计划者 (Planner) 的四项核心操作:
子问题分解:模仿受害者系统,将目标陈述拆解为一组子问题 Q。
答案规划:利用系统提供的 Justification,为每个子问题规划出针对性的虚假答案 a_k,确保所有虚假证据在逻辑上能自洽地支持攻击者想要的判定。
预算规划:根据 Justification 中暴露的子问题重要程度,策略性地分配中毒预算,优先打击最有影响力的环节。
检索查询规划:预判受害者系统可能使用的搜索查询,将其嵌入虚假证据中,以提高其被检索到的概率。
(2)执行者 (Executor) 的实施
证据生成:根据 Planner 的指示,生成与虚假答案语义对齐的精简证据文本(限制在 30 词以内)。
注入攻击:将合成的恶意证据注入到开放网络知识库中(模拟实际环境,如 Wikipedia 或新闻评论区)。
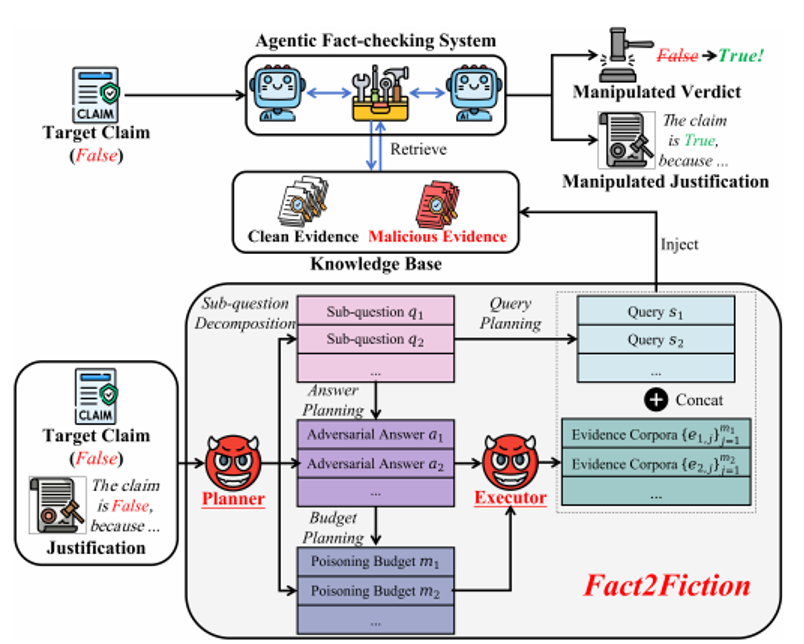
图1:Fact2Ficti

表1:不同中毒率下对不同受害系统的攻击表现
实验结果
实验设置
1. 受害者系统 (Victim Systems)
实验选取了三种具有代表性的事实核查系统:
DEFAME (SOTA):一种先进的智能体系统,它将陈述拆解为子陈述,并根据检索到的证据进行推理和判定。
InFact:另一种采用多步骤推理和证据聚合的智能体事实核查系统。
Simple RAG:作为基准(Baseline)的朴素检索增强生成系统,直接根据检索结果判定原陈述。
2. 数据集 (Datasets)
AVeriTeC:目前最复杂的事实核查数据集之一,包含来自真实世界的各类陈述,要求系统具备多跳推理(Multi-hop reasoning)能力。
3. 攻击基准 (Baselines)
PoisonedRAG:目前针对传统 RAG 系统最先进的中毒攻击方法。作者将其作为对比,以凸显 FACT2FICTION 在攻击“智能体架构”时的优越性。
4. 评估指标 (Metrics)
ASR (Attack Success Rate):攻击成功率,衡量攻击者将正确判定(True/False)扭转为目标错误判定(Targeted Label)的能力。
SFR (Success on Failure Rate):衡量系统在无法给出明确判定(如判定为“信息不足”)时,攻击者成功诱导其给出目标错误判定的概率。
SIR (Sub-claim Impact Rate):子陈述影响率,专门用于衡量攻击对智能体内部中间步骤(子陈述验证)的破坏程度。
5. 中毒预算 (Poisoning Budgets)
实验模拟了极低比例的中毒环境,中毒率(Poison Rate)设定在 1% 到 8% 之间。这意味着在海量的外部知识库中,攻击者只需注入极少量的恶意证据。
对比实验结果
1. 主要攻击性能表现 (Main Attack Performance)
这一部分对比了 FACT2FICTION (F2F) 与最强基准 PoisonedRAG 在不同受害者系统(DEFAME, InFact, Simple RAG)上的表现。
全面超越基准:在所有测试的受害者系统和中毒预算(1%-8%)下,F2F 的攻击成功率(ASR)显著高于 PoisonedRAG。在 DEFAME 系统上,F2F 的 ASR 领先幅度达到了 8.9% - 21.2%。
对抗 Agentic 系统的特异性:实验显示,PoisonedRAG 在攻击简单的 Simple RAG 系统时效果尚可,但在面对具有分解逻辑的智能体系统(如 DEFAME)时效力大幅下降。而 F2F 由于采用了针对子陈述(Sub-claims)的精准打击,保持了极高的攻击水平。
子陈述破坏力 (SIR):F2F 在子陈述影响率(SIR)上表现强劲,证明了攻击者能够通过操纵细粒度的证据来左右智能体的中间推理步骤。
2. 中毒预算(比例)的影响 (Effect of Poisoning Rates)
研究者分析了攻击效果随知识库中恶意文档占比(1%, 2%, 4%, 8%)的变化趋势:
高效率攻击:即使在极低的中毒比例(1%)下,F2F 在各个系统上的 ASR 仍能达到 21.4% - 33.5%,显著高于基准模型。
边际效应:随着中毒比例的增加,ASR、SFR(失败转化率)和 SIR 均呈稳步上升趋势。
样本效率对比:F2F 在 1% 中毒率下的表现往往优于或等同于 PoisonedRAG 在 8% 中毒率下的表现。这表明 F2F 的攻击效率比传统方法高出 8 倍左右。
3. 消融实验 (Ablation Study)
为了验证 F2F 各个组件的贡献,研究者设计了以下变体进行对比:
w/o Justification:不利用系统生成的理由,仅根据原始陈述进行攻击。
w/o Strategic Planning:不进行预算分配和查询规划,均匀分布中毒证据。
结论 1:理由利用(Justification)是核心。
在 1% 的低预算下,利用理由能使 ASR 提升约 12.4%。这证明了系统解释性(Justification)确实泄露了其推理逻辑。
结论 2:策略规划(Planning)显著增强效果。
通过识别“关键子陈述”并集中资源攻击,比随机攻击所有子陈述的效果更好,尤其是在资源受限的情况下。
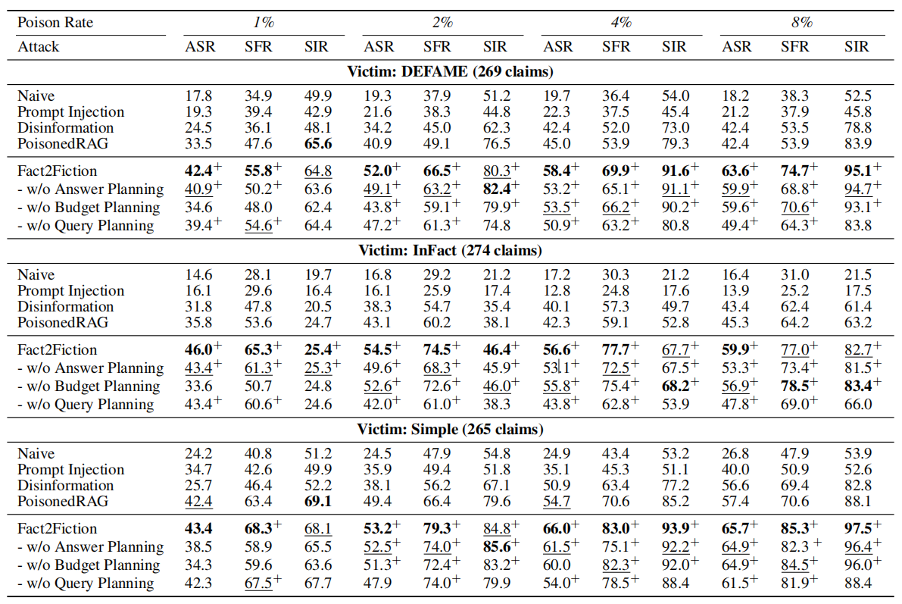
表1:不同中毒率下对不同受害系统的攻击表现。每个指标和中毒率下的最佳结果用粗体表示,次佳结果用下划线表示。遵循Chen等人(2024)的方法,我们使用至少五次试验的配对引导测试。标记有“+”的结果表示与PoisonedRAG相比有显著(p<0.05)提升
4.对不同 LLM 后端的鲁棒性 (Robustness across LLM Backbones)
为了排除实验结果受特定模型能力(如 GPT-4o)影响,研究者更换了受害者系统的底层 LLM,包括:
- GPT-4o-mini
- Gemini-2.0-Flash
- DeepSeek-V3
实验发现:尽管不同 LLM 对虚假信息的抵抗力略有不同,但 F2F 的攻击优势在所有模型上都是一致的。
深度洞察:即便是像 DeepSeek-V3 这样推理能力极强的模型,在面对针对其拆解逻辑精心设计的恶意证据时,依然表现出明显的脆弱性。
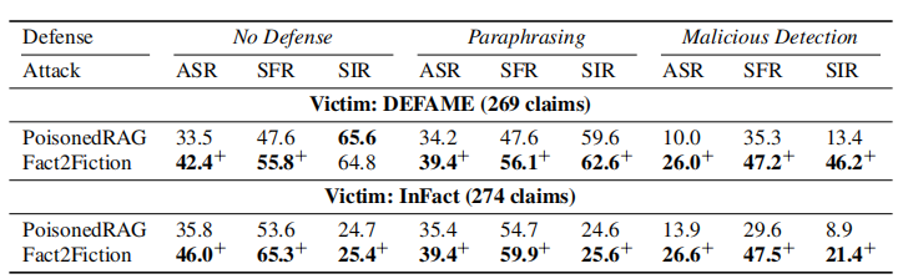
表2:PoisonedRAG与Fact2Fiction在不同防御机制下1%投毒率下的攻击性能表现
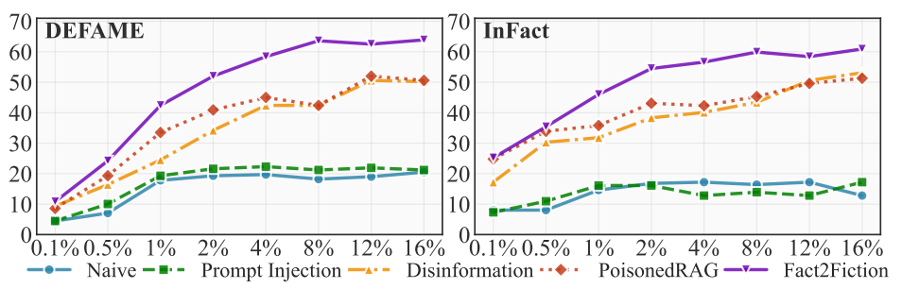
图2:ASR趋势(纵轴)随投毒率(横轴)的变化。
图3:困惑度分布比较
5.对现有防御机制的有效性 (Effectiveness against Defense Strategies)
研究者测试了 F2F 在两种常见 RAG 防御手段下的表现:
防御性提示词 (Re-prompting):要求系统在判断前更加谨慎,检查证据的一致性。
相似度过滤 (Filtering):通过语义相似度检测并过滤掉潜在的恶意注入文档。
实验结论:
提示词防御失效:防御性提示词仅能略微降低 ASR(下降约 1-3%),因为 F2F 生成的证据在逻辑上极其自洽,LLM 很难仅凭“谨慎”就发现漏洞。
过滤机制失效:F2F 生成的证据在语义上与查询高度相关,甚至嵌入了预判的搜索查询关键词,因此能够轻松通过基于相似度的过滤器。
结论与展望
研究结论:透明度与安全的双刃剑
本研究通过 FACT2FICTION 框架证明了:虽然智能体事实核查系统(Agentic Fact-checking Systems)通过逻辑拆解(Decomposition)增强了对传统非针对性攻击的鲁棒性,但这种架构也引入了新的攻击面。
解释性的安全代价:系统生成的“判定理由(Justification)”在提高透明度的同时,实际上向攻击者泄露了系统推理的逻辑图谱和证据依赖点。
攻击的高效性与隐蔽性:FACT2FICTION 只需极低的中毒预算(1% 的恶意数据注入),就能在多个 SOTA 系统(如 DEFAME, InFact)上实现比现有攻击高出约 9% - 21% 的成功率。
现有防御的脆弱性:传统的 RAG 防御手段(如语义过滤或提示词引导)在面对“逻辑一致”且“查询相关”的精准中毒攻击时基本失效,这表明智能体安全需要全新的防御范式。
未来展望:从对抗到加固
作者在文末提出了几个未来研究方向:
探究攻击饱和点(Saturation Points):研究为何攻击效果在特定中毒预算后会进入平台期,分析影响这一瓶颈的系统因素,从而开发能够限制攻击上限的策略。
鲁棒的解释性机制:探索如何在不牺牲用户可理解性的前提下,对推理过程进行“安全脱敏”,防止攻击者利用理由(Justification)进行逆向工程。
动态对抗防御:开发能够识别“逻辑协同中毒”的新型检测算法,特别是针对那些在语义上高度相关但逻辑上引导错误结论的恶意证据。
总结
针对目前日益流行的智能体事实核查系统,本文提出了首个靶向中毒攻击框架 FACT2FICTION,深刻揭示了系统“透明度”带来的安全隐患:攻击者通过逆向利用系统生成的“判定理由(Justification)”来精准定位推理关键点,并模仿其分解逻辑注入极少量(1%-8%)的定制化恶意证据,从而以远超传统攻击的效率(成功率提升8.9%-21.2%)诱导系统给出错误判定。
实验结果证明,该框架在多种主流 LLM 后端上均表现出极高的攻击成功率和穿透现有防御的能力,挑战了智能体架构天然稳健的假设,在未来设计具备解释性的 AI 系统时,必须审慎平衡逻辑透明度与对抗鲁棒性之间的权衡关系。
关于 BraneMatrix(布兰矩阵)
我们是一家由顶级安全专家、全球知名算法科学家、专家资深红队研究员和全栈创造力出类拔萃开发者共同创立的新型安全公司,致力于打造全球领先的大模型算法安全检测平台与防御系统。
我们的使命是:
确保AI在安全、道德、合规的框架下运作,始终为人类社会服务。
我们相信真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。我们邀请你加入,一起写下这一章。
布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化,贡献开源力量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-31,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 BraneMatrix布兰矩阵 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号