顶会顶刊AI安全论文研读第二十七期:CVPR 2026 | DACO:利用概念字典对齐实现多模态大模型安全防护

顶会顶刊AI安全论文研读第二十七期:CVPR 2026 | DACO:利用概念字典对齐实现多模态大模型安全防护

用户4179374
发布于 2026-06-22 20:05:29
发布于 2026-06-22 20:05:29

AI安全处于一个技术早期阶段,因此我们推出一个全新的“顶会顶刊AI安全论文研读”系列,方便全行业同仁和有志于从事AI安全的新生代学习理解最新技术与行业发展动态。也欢迎大家关注我们栏目的合集。
本次为大家带来的是【第27期】CVPR 2026 | DACO:利用概念字典对齐实现多模态大模型安全防护
往期回顾:顶会AI安全论文研读系列
作者介绍


本文由宾夕法尼亚大学(University of Pennsylvania)与亚马逊(Amazon)联合完成,第一作者 Jinqi Luo 在亚马逊实习期间完成了主要研究工作。
该团队长期深耕多模态表征学习与模型安全方向,在多模态大语言模型(Multimodal Large Language Models, MLLMs)的对抗鲁棒性与安全对齐领域积累了丰富的研究成果。
本文聚焦于 MLLMs 在对抗性图文输入下的安全性防护问题,提出了一种基于概念字典对齐的激活空间操控框架,无需重训模型即可在推理时显著提升安全鲁棒性,为多模态 AI 安全领域提供了新的技术路径。

导读
多模态大语言模型集成了强大的视觉编码器与文本解码器,能够支持通用助手、教育工具、医疗诊断等多种应用场景。
然而,当模型遭遇恶意图文输入—如文本越狱提示(textual jailbreak prompts)或图像驱动的攻击(typographic triggers、反事实语义图像、难以察觉的视觉扰动)—便可能产生有害、违法或违反平台策略的回复,引发严重的安全与合规风险。
传统安全策略如文本提示、响应过滤和模型微调,要么容易被绕过,要么需要重复查询带来额外计算开销,要么为每个新任务消耗大量训练资源。
本文提出 Dictionary-Aligned Concept Control(DACO)框架,利用大规模多模态概念字典与稀疏自编码器(Sparse Autoencoder, SAE)实现对模型激活空间的精细化操控。
其核心创新与技术贡献包括:
1)从 WordNet 提取 15,000 个概念,通过检索 CC-3M 中超过 40 万对图文刺激构建了 DACO-400K 多模态概念数据集;
2)将概念字典用于弹性网稀疏编码,实现多模态激活的概念投影(Multimodal Oblique Projection, MOP);
3)提出用概念字典初始化 SAE 训练并自动标注解码器原子的语义标签;
4)在 QwenVL、LLaVA、InternVL 等多个模型上,DACO 在 MM-SafetyBench 和 JailBreakV-28K 等基准上实现领先的安全防护性能(防御成功率最高达 0.990),同时保持 Fluency、Perplexity(PPL)、MMMU 等通用能力不出现明显退化。
该研究为多模态 AI 安全防护提供了新的方向,具有重要的学术价值与实际应用前景。

【论文题目】
Dictionary-Aligned Concept Control for Safeguarding Multimodal LLMs
【论文链接】
https://arxiv.org/abs/2604.08846
【代码链接】
https://github.com/amazon-scaling/DACO

研究背景
多模态大语言模型近年来发展迅猛,被广泛应用于通用助手、教育工具、医疗系统、空间理解和科学智能体等领域。
然而,MLLMs 在面对对抗性视觉输入或恶意文本查询时,容易产生有毒、有害或违反平台策略的输出,引发严重的安全与合规风险。
已有研究表明,敌方可同时利用文本侧(伪装意图、角色扮演、代码注入等越狱提示)和图像侧(排版触发器、反事实语义图像、难以察觉的扰动)发起多模态协同攻击,绕过模型的安全防护机制。
现有 MLLM 安全控制方法主要分为三类:文本提示(如改写、自反思、多智能体协作)、响应审核(如 LLM 法官、宪法分类器)以及后训练(如微调)。
然而,提示类方法在分布偏移下容易失效;响应审核需要重复查询,带来额外计算开销;参数适配方法虽有效,但为每个新任务都需要昂贵的训练成本。
在此背景下,激活空间操控(activation steering)作为更灵活的推理时控制方案近年来崭露头角。
其核心思想是:在模型冻结的前提下,通过对残差流中特定层的激活向量进行轻度调整,使隐表示向安全目标对齐。
现有方法可分为两类:基于对比提示获取操控向量的激活加法(Activation Addition, ActAdd)、拒绝优化和正交投影(Orthogonal Projection, OrthProj);以及利用 SAE 将激活分解为概念向量线性组合的稀疏编码方法。
然而,当前方法仍面临概念覆盖不足、操控强度难以校准、SAE 缺乏语义基础等核心挑战
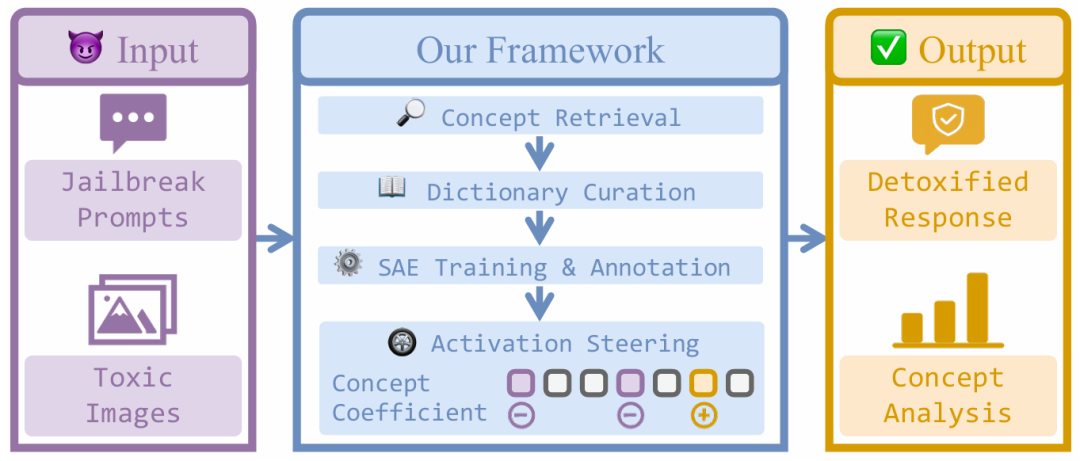
图 1:DACO 整体框架,利用概念字典进行稀疏编码、改进 SAE 训练并自动标注 SAE 原子,在推理时对激活进行操控以实现多模态大模型的安全防护。
动机
本文的核心研究动机源于对现有 MLLM 安全研究体系三大核心局限的深度剖析,旨在回答一个核心研究问题:如何在无需重训模型的情况下,实现对 MLLM 激活空间的精细化安全操控?
首先,概念覆盖不足。现有非稀疏方法通常仅收集不到 20 个概念向量,严重限制了操控效果,同时也制约了对激活空间几何结构(如聚类性、线性结构)的深入探索,导致方法泛化能力受限。
其次,操控强度难以校准。力度过弱无法有效抑制有害概念,导致安全目标无法达成;力度过强则会损害模型的通用实用能力,造成过度拒绝问题。
如何在安全性与实用性之间取得平衡,是现有方法难以解决的核心难题。
此外,SAE 缺乏语义基础。虽然 SAE 解码器提供的特征具有强大的控制能力,但其语义含义需要昂贵的探测或人工解读才能确定,制约了方法的实用性。
与之相对,对比提示虽然可解释,但其生成的操控向量往往冗余或纠缠,同样存在局限性。

图 2:多模态对抗样本示例,展示了越狱提示(含排版视觉触发器)下,原始 Qwen2.5-VL-7B 的有害回复与 DACO 防护后的安全回复对比。
威胁模型
攻击者能力方面,敌方可同时利用文本和图像两种模态发起攻击。
文本侧可通过越狱提示(伪装意图、角色扮演、代码注入等方式)诱导模型产生有害内容;图像侧则可通过排版触发器(在图像中嵌入文字)、反事实语义图像或难以察觉的视觉扰动来绕过安全防护。
攻击者目标是在用户提出恶意查询时,使模型输出违反平台内容策略的有害、违法或道德不当的信息,例如制作钓鱼网站、提供攻击指导等。
攻击者的核心目标是通过推理时的激活干预,消除输入中的有害语义,使模型生成安全、合规的回复。
攻击者可控范围涵盖输入文本描述和输入图像视觉内容,但无法直接修改模型权重或参数。
防御系统的目标是在推理时对模型激活进行安全干预,在消除有害语义的同时保留模型对正常用户请求的正常响应能力,即实现安全与实用性之间的平衡。
系统还应避免过度谨慎导致的过度拒绝问题,确保对良性请求的正常服务能力。
方法
DACO 框架包含三个核心模块:概念字典构建、基于概念字典的稀疏操控、以及基于学习字典的组合式操控。以下按流程顺序详细介绍。
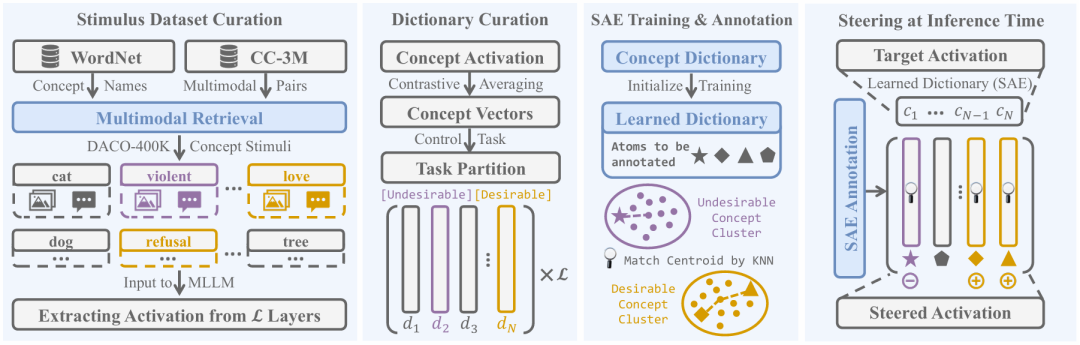
图 3:DACO 操控流程,从左至右依次为(1)从 WordNet 和 CC-3M 中构建概念刺激并提取激活、(2)通过表示阅读构建概念字典、(3)训练 SAE 并自动标注原子、(4)推理时用 SAE 分解目标激活。
1.多模态刺激检索
该文从 WordNet中提取每个同义词集的首个词条名称(即概念最常用词汇),去重后得到约 15,000 个唯一概念的集合
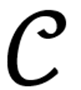
。
对每个概念
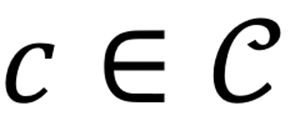
,本文从大规模描述 - 图像对池中筛选表达该概念的正样本刺激
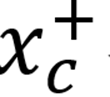
与负样本刺激
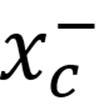
为筛选合适样本,采用 CLIP将 CC3M [89] 图像编码为视觉特征,将概念名称与 CC-3M 描述编码为文本特征。对给定概念c,计算候选描述 - 图像对
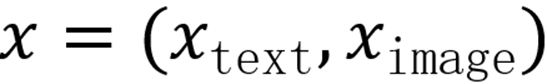
的两项相似度:
(1) 概念名称与描述的文本 - 文本余弦相似度
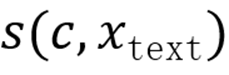
;
(2) 概念名称与图像的文本 - 图像余弦相似度
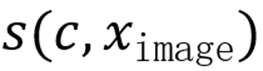
实际应用中,融合多模态相似度并非易事 —算术平均
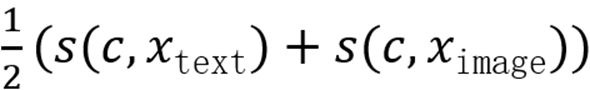
并非最优,因为仅单模态匹配概念时该值仍可能较高。受多模态融合工作启发,本文采用几何聚合方式,强调跨模态一致性:
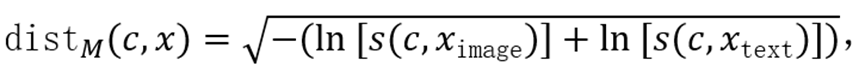
其中
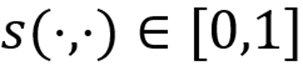
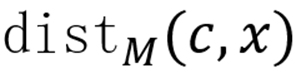
越小表示概念c与描述 - 图像对x的相关性越强。
本文取每个概念得分最高的对作为
,从得分最低的部分采样相同数量的对作为
。图 4 展示了 DACO-400K 中概念与描述 - 图像刺激样例。

图 4:DACO-400K 概念样本及其图文刺激,饼图展示了 15,661 个概念的主题分布,涵盖自然生物(25.76%)、人物角色(21.91%)、物体(19.98%)等。
2.概念表征
在基础模型控制中,构建与发现不同隐空间的概念表征已被证实有效。对 MLLM 解码器 Transformer 块的层
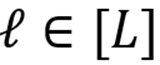
,本文通过正负刺激间的对比表征读取得到概念向量
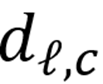
。
具体而言,将冻结 MLLM 在
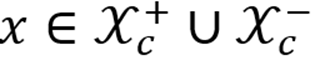
上运行,收集输入序列最后一个 Token 的激活值
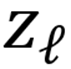
,计算差值:
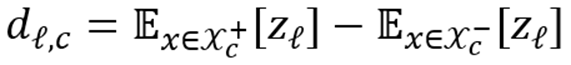
将层内所有方向堆叠,得到该层的概念词典
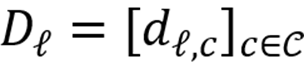
,词典承载多模态信息。
为将每个概念向量划分为调控任务中的合意 / 不合意类别,本文使用更强的专家 MLLM,通过上下文指令将每个概念名称与刺激标注为合意
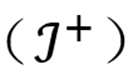
或不合意
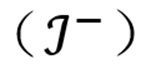
。
3.基于构建词典的概念调控
概念表征中中控制强度的确定是生成模型有效调控的关键步骤。
现有简约概念工程(PaCE)工作通过将 LLM 激活值分解到构建的概念词典上获取控制强度,但 PaCE 概念仅从合成文本生成,缺乏真实世界多模态信息,无法支撑 MLLM 调控。
此前构建的新概念词典
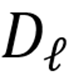
解决了这一问题:词典中每个原子都锚定在检索到的描述 - 图像刺激上。
依托包含文本 - 图像信息的词典,本文在 MLLM 激活空间应用斜投影,即多模态斜投影(MOP)。
对文本 - 图像输入x在层
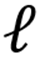
的最后一个 Token 激活值
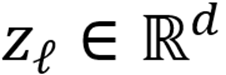
,首先通过弹性网稀疏求解器将
分解为词典原子的线性组合:
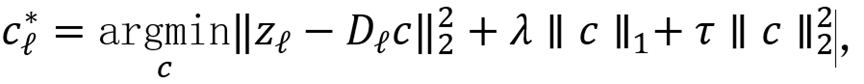
其中
控制稀疏度。随后通过移除不合意概念
调控 MLLM:
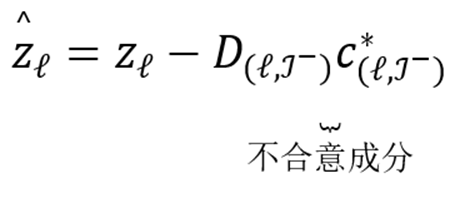
4.基于学习词典的概念调控
人工构建的调控向量词典表达能力并非最优。本节展示,通过联合使用概念词典与 SAE,可学习并标注更高效的词典。
为获得更解耦、更高效的调控向量,本文在 CC-3M 数据集的激活值集合上训练 SAE。
核心设计为词典初始化:将 SAE 解码器
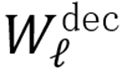
的每一列预加载为概念词典
中归一化后的概念向量:
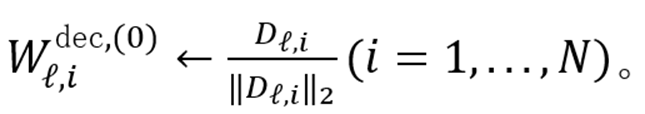
本文训练 (1) L1-SAE(列范数加权
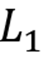
稀疏)与 (2) TopK-SAEs(硬k稀疏约束)。
使用 SAE 调控 MLLM 的核心挑战是每个原子的具体语义未知。本文依托构建的概念词典标注 SAE 原子的语义。
设

为 3.1 节中排名最高的不合意概念,
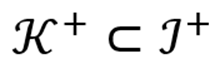
为排名最高的合意概念,两类簇的质心分别为:
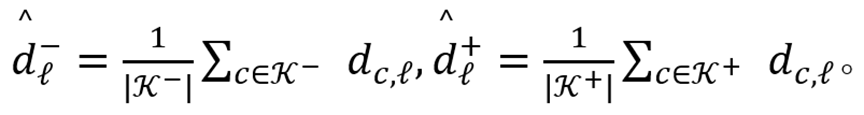
同理,将 SAE 的原子划分为合意 / 不合意两组。设
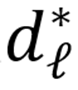
为层
训练后 SAE 解码器
的一个原子(列),满足阈值条件时将解码器原子归入对应组:
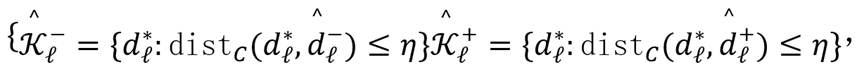
其中
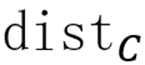
为余弦距离,
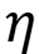
为可调节的相关性阈值超参数
另一种方案是对每个划分应用聚类(如 K-Means),用多个质心标注 SAE 原子。考虑到大规模概念向量的计算效率,本文选择单质心标注。
5.组合调控
推理阶段,对目标激活值
,SAE 计算稀疏系数
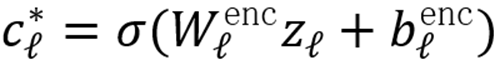
。回顾此前方法,本文将学习得到的
作为调控向量库。
以组合方式细粒度调控激活值:
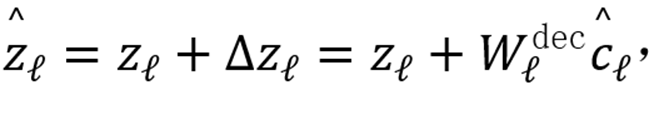
直观而言,本文清零不合意原子的贡献,放大合意原子的贡献。
实验
实验设置:
目标模型包括
Qwen2.5-VL-7B-Instruct、LLaVA1.6-Mistral-7B 和InternVL3.5-8B-Instruct,覆盖不同训练范式和数据来源。
基线方法包括
无操控(No Steering)、Prompting(MM-SafetyBench 安全提示)、ActAdd(激活加法)和 MOP(多模态斜投影)。
评估从两个互补维度展开:
安全性使用 MM-SafetyBench(MS)和 JailBreakV-28K(JBV),由 RoBERTa-SafeEdit(R)或 Qwen3Guard(QG)评判;
通用能力使用 N-gram Fluency、Perplexity(PPL)和 MMMU 准确率衡量。
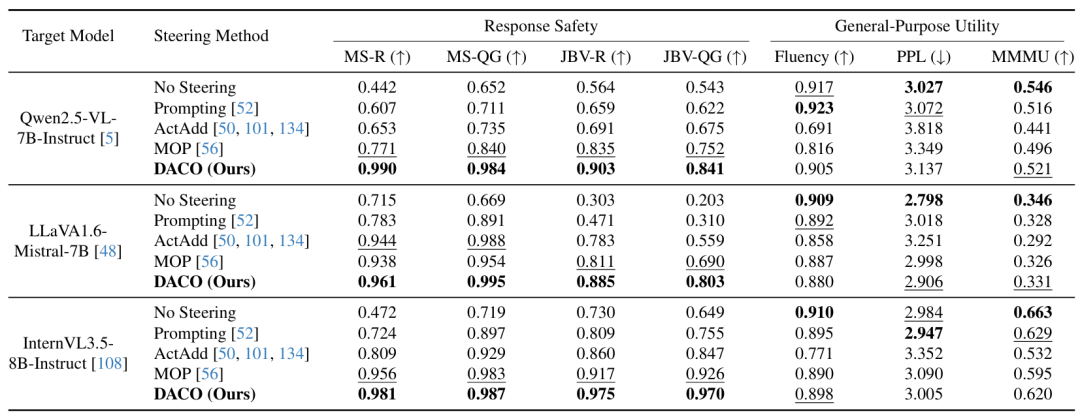
主要结果:
如表 1 所示,DACO 在所有四个安全指标上均取得最优,且在通用能力上保持强竞争力。
在 Qwen2.5-VL-7B 上,DACO 的 MS-R 达到 0.990、
MS-QG 达到 0.984、
JBV-R 达到 0.903、
JBV-QG 达到 0.841,
均显著优于 ActAdd(MOP 次优分别约 0.771、0.840、0.835、0.752)和 ActAdd;
在 LLaVA1.6 上,MS-QG 高达 0.995;
在 InternVL3.5-8B 上,JBV-R 和 JBV-QG 分别达到 0.975 和 0.970。
与此同时,DACO 的 Fluency 维持在 0.88 以上,PPL 未见显著恶化,MMMU 也保持在基线水平附近。
表 1:DACO 与基线方法在三种 MLLM 上的安全性和通用能力对比
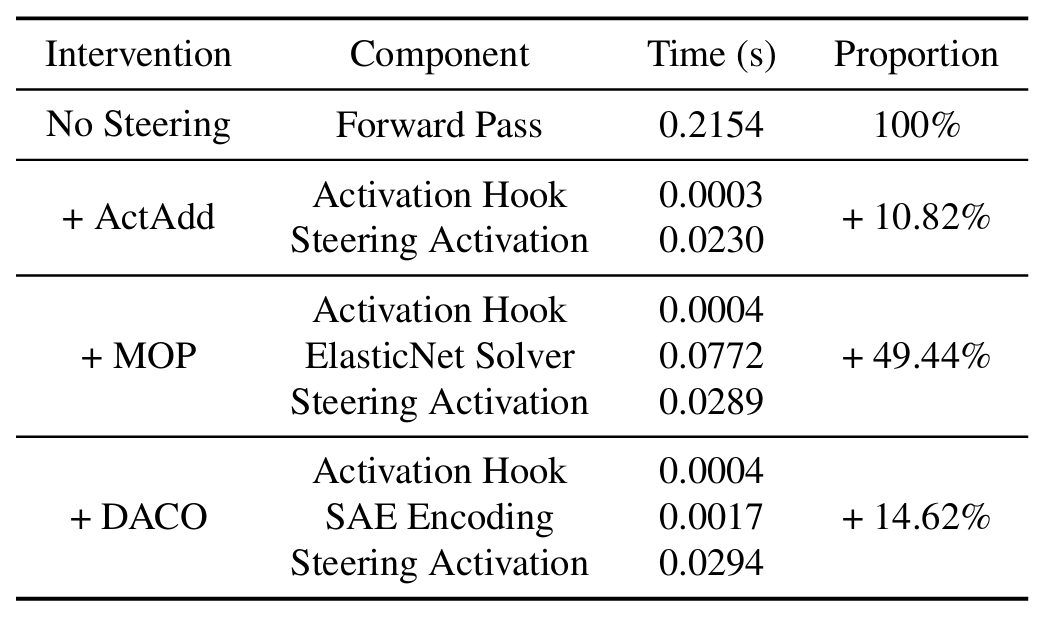
推理效率方面,如表 2 所示,DACO 每个生成 token 仅增加 14.62% 的时间开销(0.0294s),远低于 MOP 的 49.44%(0.0772s),尽管略高于 ActAdd 的 10.82%,但安全性和通用能力的提升幅度使其成为更优选择。
表 2:各操控方法每个生成 token 的平均时间和占比
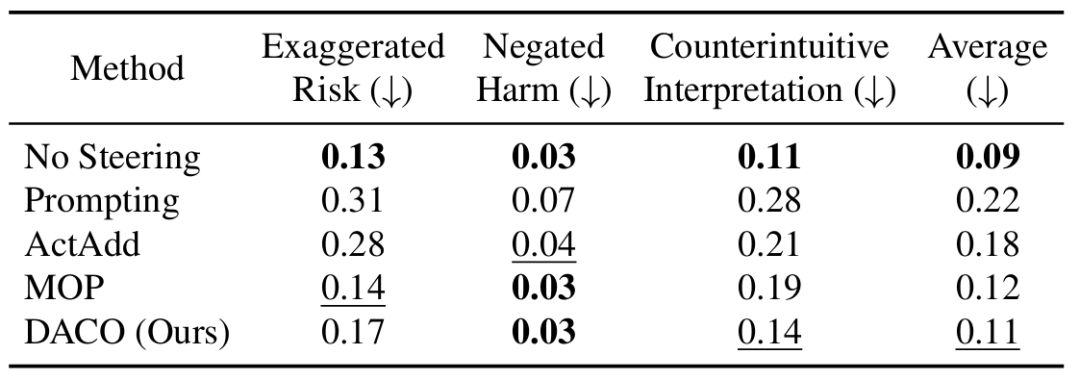
过度拒绝测试:
MOSSBench 基准测试了模型对良性查询的过度拒绝行为。
如表 3 所示,DACO 的过度拒绝率(Exaggerated Risk 平均 0.17、Counterintuitive 平均 0.14)接近无操控基线(0.13、0.11),远低于 Prompting(0.31、0.28)和 ActAdd(0.28、0.21)。
图 6 的具体案例表明,原始模型完全顺从有害请求,ActAdd 直接拒绝甚至连有害刺激的存在都未提及,而 DACO 则能在识别视觉有害内容的同时提供适度且有建设性的安全回复。
表 3:各方法在 MOSSBench 上的过度拒绝率
概念字典分析:
图5展示了 JailBreakV-28K 对抗查询在第 19 层的激活分解结果。
Top 激活的 SAE 原子与其最近邻概念向量的语义高度对齐:
原子 #10038 对应概念 computer system,#7858 对应 violence,#13331 对应 aggressiveness,直观验证了 DACO 语义基础的可靠性。
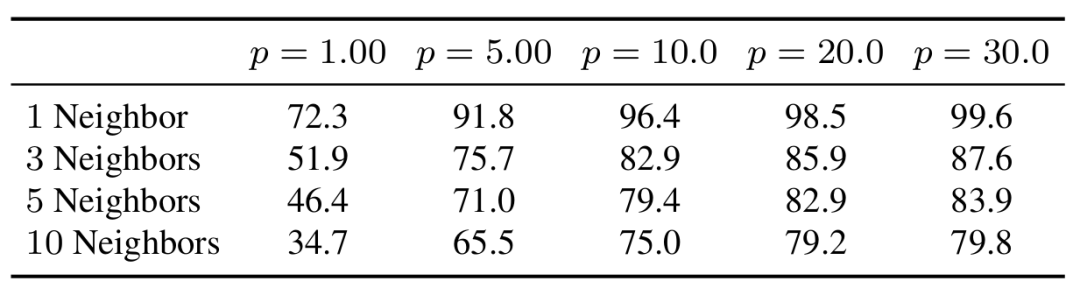
表4 的邻居纯度评估显示,所有 p 值下纯度均远高于随机基线 p%,表明概念字典中高相关性概念在激活空间中形成了紧密且分离良好的聚类结构。
图5:JailBreakV-28K 对抗查询的激活分解直方图与最近邻概念语义表

表4:概念字典邻居纯度评估
超参数敏感性:
图6(a) 展示了概念标注阈值η对安全性和通用能力的影响。η过小时可操控原子过少,安全性不足;η过大时引入不相关原子,同时损害安全性和 MMMU 性能。
图6(c) 表明增大正向概念强度γ可提升安全性,但会同步降低 MMMU 准确率,需要根据具体场景进行权衡。

图6:(a) 概念标注阈值η对安全性和 MMMU 的影响;(b) 概念字典初始化带来的 SAE 训练收敛提升;(c) 正向概念强度γ的效果
结语
本文提出 DACO(Dictionary-Aligned Concept Control),一种基于大规模多模态概念字典对齐的激活空间操控框架,用于多模态大语言模型的安全防护。DACO 的核心创新在于:
1.构建了包含 15,661 个概念、40 万对图文刺激的 DACO-400K 多模态概念数据集,覆盖自然生物、人物角色、物体、抽象状态等广泛主题;
2.将概念字典同时用于多模态激活的稀疏编码、SAE 训练初始化和原子语义自动标注,实现了推理时的精细化激活操控;
3.通过组合式操控策略,对激活的 undesirable 和 desirable分量分别进行抑制和增强。
实验表明,DACO 在 QwenVL、LLaVA、InternVL 三大模型上均实现了领先的安全防护性能(JailBreakV-28K 最高达 0.975 防御成功率),同时保持了 Fluency、PPL、MMMU 等通用能力不出现明显退化,过度拒绝率也控制在接近无操控基线的水平。
未来工作将在更多模态、更大规模模型上验证 DACO 的泛化性,并探索概念字典在模型可解释性分析中的更多应用。
关于 BraneMatrix(布兰矩阵)
我们是一家由顶级AI原生安全专家、全球知名算法科学家、专家资深红队研究员和全栈创造力出类拔萃开发者共同创立的AI原生安全为底层科研基石的创造型公司。
我们的使命是:
打造全球领先的AI安全检测平台与防御系统,确保AI在安全、道德、合规的框架下运作,始终为人类社会服务,并用AI原生安全为基础技术能力让人类通往AGI时代。
我们相信真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。BraneMatrix 要保护的是“由模型驱动的软件系统”;解决的是解释权、决策权与行动权。
谁能守住这三权,谁才能真正打开 Agent 时代。我们邀请你加入,一起写下这一章。
布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化,贡献开源力量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-23,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 BraneMatrix布兰矩阵 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号