ECCV 2026 | GeoSR:让VLM真正用上几何信息,静态/动态空间推理均达SOTA!

ECCV 2026 | GeoSR:让VLM真正用上几何信息,静态/动态空间推理均达SOTA!

Amusi
发布于 2026-06-24 19:32:30
发布于 2026-06-24 19:32:30
导读:视觉语言模型已经很会“看图说话”,但一遇到距离、方向、视角变化、运动关系这类空间问题,仍然容易露怯。NUS xML Lab 提出的 GeoSR 关注一个更细的问题:几何信息明明已经作为 token 加进模型了,为什么 VLM 还是不一定会用?论文给出的答案是,单纯注入几何 token 远远不够,还要在训练时削弱外观捷径,并在融合时让模型按需依赖几何证据。
静态空间推理:naive 几何融合提升有限,GeoSR 在 VSI-Bench 上取得 51.9 平均分 | 动态空间推理:naive 几何融合可能退化,GeoSR 达到 66.1 平均准确率 |
|---|
论文信息
- 论文标题:Make Geometry Matter for Spatial Reasoning
- 方法名称:GeoSR
- 会议:ECCV 2026
- 作者:Shihua Zhang, Qiuhong Shen, Shizun Wang, Tianbo Pan, Xinchao Wang
- 机构:National University of Singapore
- 论文:https://arxiv.org/abs/2603.26639
- 代码:https://github.com/SuhZhang/GeoSR
- 项目主页:https://suhzhang.github.io/GeoSR/
- 模型:https://huggingface.co/SuhZhang/GeoSR-Model
1. 看见,不等于理解空间
过去几年,VLM 在图像理解、视频问答、多模态对话上进展很快。它们可以识别物体、描述场景、总结事件,甚至完成不少复杂问答。但空间推理并不是简单的语义识别。
比如:
- “从摄像头视角看,车在 2 秒到 4 秒之间的方向如何变化?”
- “床旁边的人面向凳子时,电视在左前方还是右后方?”
- “沙发、桌子、冰箱、洗碗机中,哪一个离电视最近?”
- “两个物体速度相近且发生遮挡时,谁移动得更快?”
这些问题要求模型理解 3D 结构、相对位置、视角变化、运动连续性和时序关系。对于自动驾驶、机器人导航、具身智能和视频理解来说,这类能力非常关键。
一个自然的思路是:既然普通 2D 视觉 token 不够,那就把 3D 几何信息也加进去。近年来不少方法都会利用预训练 3D 基础模型,从单目图像或视频中提取 geometry tokens,再与 VLM 的 vision tokens 融合。
听起来很直接,但 GeoSR 发现:几何 token 被加进去,不代表模型真的会用。
2. 关键发现:几何信息可能被忽略,甚至帮倒忙
GeoSR 的出发点很有意思。论文并不是简单说“加入几何信息可以提升空间推理”,而是先指出一个反直觉现象:
在常见的 naive token fusion + standard fine-tuning 设定下,geometry tokens 经常只是一个可有可无的旁路信号。模型仍然倾向于依赖 2D 外观线索完成回答。
更进一步,在动态空间推理里,不受控制的几何融合甚至可能带来负效应。
下表来自论文中的诊断实验,可以直观看到这个问题:
设置 | VSI-Bench 静态空间推理 | DSR-Bench 动态空间推理 | 现象 |
|---|---|---|---|
不使用几何分支 | 49.8 | 64.0 | 仅依赖 2D vision tokens |
naive 几何融合 | 50.2 | 62.8 | 静态提升很小,动态反而下降 |
GeoSR | 51.9 | 66.1 | 让几何信息真正参与推理 |
这说明,问题不只是“有没有几何信息”,而是“模型是否把几何信息当成可操作证据”。如果融合方式过于粗糙,模型可能继续走外观捷径;如果几何与外观被无差别混合,几何线索还可能被稀释,最终影响动态场景中的判断。
3. GeoSR:让几何信息“有效”且“合理”地被使用
GeoSR 沿用几何感知 VLM 的基本范式:视觉分支提取 2D vision tokens,文本分支编码问题,几何分支从单目图像或视频中提取 geometry tokens,最后通过融合模块送入 VLM 进行回答。
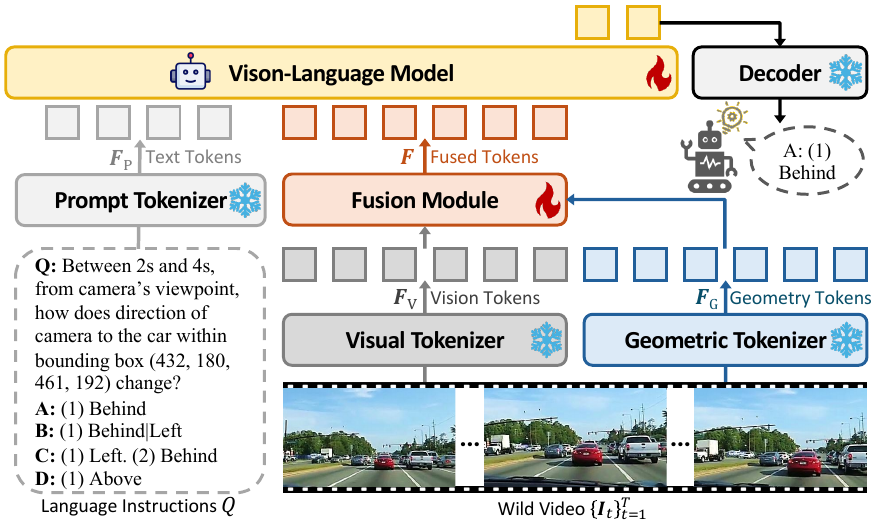
几何感知 VLM 基本框架
几何感知 VLM 基本框架
但 GeoSR 的重点不是重写这条 pipeline,而是回答一个更核心的问题:怎样让 VLM 在需要空间推理时真的去看几何证据?
为此,GeoSR 设计了两个互补模块:
- Geometry-Unleashing Masking:在训练阶段削弱 2D 外观捷径,让模型不得不求助几何信息。
- Geometry-Guided Fusion:在融合阶段用细粒度门控决定哪里更该相信几何,哪里更该保留视觉线索。
这两个模块分别对应“有效使用几何”和“合理使用几何”。
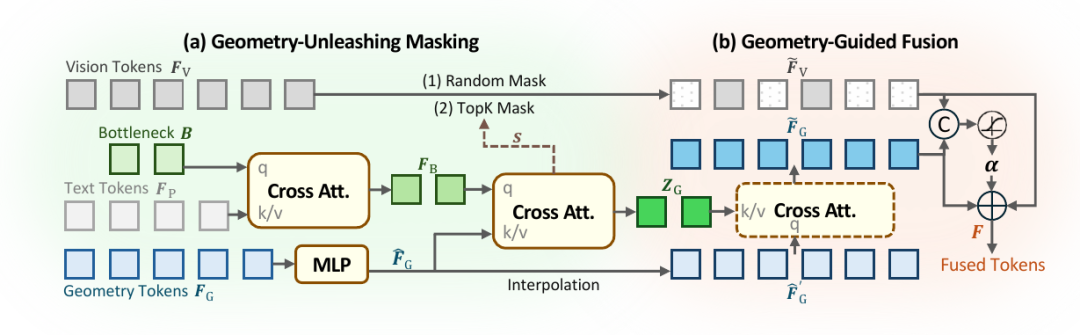
GeoSR 方法总览
GeoSR 方法总览
3.1 Geometry-Unleashing Masking:先把外观捷径堵住一部分
很多空间问题并不一定需要完整理解几何,模型可能通过局部纹理、物体类别、常见场景偏置猜出答案。这样的“捷径”在训练中会让 geometry tokens 被边缘化。
GeoSR 的做法很直接:训练时有策略地 mask 掉一部分 2D vision tokens,降低模型对外观线索的依赖,迫使它从几何分支中寻找证据。
在静态空间推理中,GeoSR 采用类似 MAE 的随机 mask。静态场景大多是刚性环境,视角和可见性变化是主要挑战,随机遮挡一部分 vision tokens 就能有效抑制外观捷径。
在动态空间推理中,问题会更复杂。视频里涉及物体运动、摄像机运动、遮挡和时间连续性,随机 mask 未必能对准真正关键的位置。因此 GeoSR 利用问题相关的几何注意力做 TopK mask:先通过 bottleneck tokens 从文本问题中提取意图,再去 geometry tokens 中定位与问题最相关的几何证据,然后 mask 对应位置的 2D vision tokens。
换句话说,动态场景中 GeoSR 不是随便遮,而是优先遮掉与问题相关、同时对应关键几何证据的 2D 位置。
3.2 Geometry-Guided Fusion:几何不是处处都有用,应该按需路由
只做 masking 还不够。即使模型被迫看几何,如果融合方式仍然只是简单相加或拼接,几何信息依旧可能在后续表示中被稀释。
GeoSR 因此提出 Geometry-Guided Fusion。它使用一个 token-wise、channel-wise 的可学习门控,在每个位置、每个通道上自适应决定视觉特征和几何特征的占比:
F = alpha * V + (1 - alpha) * G
其中 V 表示经过处理的视觉特征,G 表示几何特征,alpha 是由模型学习得到的细粒度门控。这样一来,几何信息不再被粗暴地统一注入,而是在真正有帮助的位置被放大。
这也是 GeoSR 和普通几何融合方法的关键区别:它不是把 geometry tokens 当成一批额外上下文,而是把它们变成可以按需路由的推理证据。
4. 实验结果:静态、动态空间推理均达到最佳表现
GeoSR 分别在静态空间推理和动态空间推理基准上进行验证。
静态空间推理采用 VSI-Bench。该基准包含来自 288 个真实视频的 5000 多个 QA 样本,主要考察刚性场景中的视角变化、可见性变化和几何关系理解,任务覆盖目标计数、绝对距离、目标尺寸、房间尺寸、相对距离、相对方向、路径规划和出现顺序等。
方法 | VSI-Bench Avg. |
|---|---|
Qwen2.5-VL-7B | 33.0 |
InternVL3-78B | 48.4 |
Spatial-MLLM | 48.4 |
VG-LLM | 50.7 |
GeoSR | 51.9 |
GeoSR 在 VSI-Bench 上取得 51.9 的平均分,相比最强几何感知基线 VG-LLM 提升 +1.2。
动态空间推理采用 DSR-Bench。该基准包含来自 575 个真实公开视频的 1484 个 QA 样本,问题涉及动态距离、方向、朝向、速度、速度比较、方向预测,以及相对参考系下的空间关系。相比静态任务,动态任务更强调时空一致性,尤其考验模型对运动和遮挡的理解。
方法 | DSR-Bench Avg. |
|---|---|
Qwen2.5-VL-7B | 23.5 |
Qwen3-VL-30B-A3B-Instruct | 31.1 |
VG-LLM | 38.4 |
GSM | 58.9 |
GeoSR | 66.1 |
GeoSR 在 DSR-Bench 上达到 66.1 的平均准确率,相比 GSM 提升 +7.2,并在论文报告的所有动态子任务类别上取得第一。
这个提升尤其值得注意:动态空间推理里,naive 几何融合可能低于不加几何的版本,而 GeoSR 通过 masking 和 gated fusion 把几何信息重新变成了有效证据。
5. 消融实验:两个模块缺一不可
论文进一步分析了 GeoSR 两个核心组件的贡献。
组件设置 | VSI-Bench Avg. | DSR-Bench Avg. |
|---|---|---|
GeoSR 完整模型 | 51.9 | 66.1 |
用原始融合替换 Geometry-Guided Fusion | 50.0 | 64.7 |
只保留 Geometry-Unleashing Masking | 49.6 | 58.1 |
只保留 Geometry-Guided Fusion | 50.9 | 64.9 |
只使用原始 naive fusion | 50.2 | 62.8 |
不使用几何分支 | 49.8 | 64.0 |
可以看到:
- 只做 masking,不设计好的融合机制,几何信息仍然很难被充分利用。
- 只做 gated fusion,不抑制外观捷径,模型依然可能低估几何分支。
- 在动态任务上,naive fusion 甚至低于 no-geometry 版本,进一步印证“几何信息不是加进去就一定有用”。
GeoSR 的优势来自两件事同时成立:训练时减少外观捷径,推理表示中按需路由几何证据。
6. 计算开销:提升明显,额外成本很小
GeoSR 的额外参数主要来自几何投影和门控模块。论文在单张 H200 GPU 上统计了动态推理开销:
方法 | 推理时间 | 参数量 | 峰值显存 |
|---|---|---|---|
Qwen2.5-VL-7B | 0.37s | 8.76B | 18.04GB |
几何感知 baseline | 0.40s | 9.16B | 18.81GB |
GeoSR | 0.41s | 9.23B | 18.95GB |
相对于几何感知 baseline,GeoSR 的推理时间仅从 0.40s 增加到 0.41s,显存从 18.81GB 增加到 18.95GB,额外开销较小。
在训练设置上,GeoSR 使用 Qwen2.5-VL-7B 作为 backbone。静态场景使用 VGGT 提取几何 token,动态场景使用 π^3(pi^3)捕捉动态几何线索。静态训练采用 SPAR-7M 和 LLaVA-Hound 数据划分,动态训练采用 DSR-Train。所有实验在 4 张 H200 GPU 上进行,每张显存 141GB;静态训练约 14 小时,动态训练约 20 小时。
7. 定性结果:更稳的空间判断
项目页给出了静态和动态空间推理的定性对比。整体来看,GeoSR 在一些需要估计相对方向、路径规划、距离关系和动态运动变化的问题上更加稳定。

VSI-Bench 定性结果
VSI-Bench 定性结果

DSR-Bench 定性结果
DSR-Bench 定性结果
论文也特别展示了两类仍然存在歧义的样本:一类是两个物体速度非常接近,视觉上难以判断谁更快;另一类是遮挡导致相对空间关系不清晰。这提醒我们,空间推理 benchmark 本身也存在标注可靠性和视觉证据充分性问题。GeoSR 提升了模型利用几何的能力,但数据和评测协议仍然是后续研究中不可忽视的一环。
8. 总结
GeoSR 的核心贡献可以概括为一句话:它让几何信息从“被注入的旁路 token”变成“真正参与推理的证据”。
这篇工作的价值不只在于刷新了 VSI-Bench 和 DSR-Bench 的结果,更在于它指出了几何感知 VLM 中一个容易被忽略的问题:geometry tokens 并不会自动生效。模型可能继续依赖 2D 外观捷径,甚至在动态场景中被不受控制的几何融合干扰。
GeoSR 用 Geometry-Unleashing Masking 抑制外观捷径,用 Geometry-Guided Fusion 进行细粒度几何路由,分别解决“是否使用几何”和“如何使用几何”两个问题。对于面向机器人、自动驾驶、具身智能和视频理解的空间推理模型来说,这种思路提供了一个很清晰的方向:不是堆更多模态信号,而是让关键模态在该发挥作用的地方真正发挥作用。
资源链接
- 论文:https://arxiv.org/abs/2603.26639
- 代码:https://github.com/SuhZhang/GeoSR
- 项目主页:https://suhzhang.github.io/GeoSR/
- 模型权重:https://huggingface.co/SuhZhang/GeoSR-Model
@misc{zhang2026geosr,
title={Make Geometry Matter for Spatial Reasoning},
author={Shihua Zhang and Qiuhong Shen and Shizun Wang and Tianbo Pan and Xinchao Wang},
year={2026},
eprint={2603.26639},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.26639}
}
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号