SSRL:Agent如何自我检索,告别外部工具依赖?

SSRL:Agent如何自我检索,告别外部工具依赖?

唐国梁Tommy
发布于 2026-06-25 20:59:20
发布于 2026-06-25 20:59:20
今天,我们要深入探讨一篇来自清华大学等机构的最新研究——SSRL (Self-Search Reinforcement Learning)。这篇论文聚焦于一个非常核心且实际的问题:如何让 LLM 在执行搜索任务时,减少对外部昂贵搜索引擎(如Google、Bing)的依赖,从而构建更高效、更具可扩展性的AI智能体(Agent)?

强化学习(RL)与大语言模型(LLM)的结合催生了在数学、编程等领域表现卓越的推理模型(LRMs),并拓展到工具学习、网页浏览等智能体任务中。虽然如 Search-R1 等模型展现出强大潜力,但训练依赖频繁调用外部搜索 API,因交互次数巨大而导致成本极高,限制了更复杂智能体的发展。
那么,有没有可能另辟蹊径呢?我们知道,LLM本身在预训练阶段已经“阅读”了海量的互联网数据,其内部参数中蕴含了丰富的世界知识。一个自然而然的想法是:我们能否直接激发和利用LLM的“内在知识库”,让它自己模拟搜索过程,从而在训练阶段完全摆脱对外部搜索引擎的依赖?

这正是SSRL这篇论文的核心动机。它试图回答两个关键问题:
- • 仅凭内部知识,LLM在搜索问答任务上的性能极限在哪里?
- • 能否通过一种“完全模拟”(full-sim)的强化学习范式,让模型在训练中“自我搜索”,并将学到的技能有效迁移到需要真实搜索的实际场景中(sim-to-real)?
核心思想:从“自我检索”到“强化学习”
为了解决上述问题,论文提出了一个两步走的核心思路:首先量化LLM的内在搜索能力,然后通过强化学习对其进行增强。

第一阶段:定义并量化“自我检索”
论文首先提出了一个概念:“自我检索”(Self-Search)。这指的是,我们不给LLM任何外部工具,只通过精心设计的提示(Prompt),引导它在一个生成回合中,完整地模拟 思考 -> 提出搜索查询 -> 生成搜索结果 -> 基于结果继续思考 这一系列动作。
这个过程非常像我们人类解决一个复杂问题的思考模式。例如,当被问到“《盗梦空间》的导演的妻子参演了他执导的哪部科幻电影?”时,我们的思考路径可能是:
1. 思考(Think): 首先,我需要知道《盗梦空间》的导演是谁。
2. 搜索(Search): “《盗梦空间》的导演”
3. 生成信息(Information): (LLM自己生成)“《盗梦空间》的导演是克里斯托弗·诺兰。”
4. 思考(Think): 好的,现在我知道了导演是诺兰。接下来我需要知道他的妻子是谁,以及她参演了诺兰的哪些电影。
5. 搜索(Search): “克里斯托弗·诺兰的妻子和参演电影”
6. 生成信息(Information): (LLM自己生成)“克里斯托弗·诺兰的妻子是艾玛·托马斯,她是一名制片人,并未作为演员参演其电影。” (这里可能出现事实错误,但这正是LLM内部知识的直接体现)
7. ……
8. 最终回答(Answer): 基于内部知识给出最终答案。
通过这种方式,LLM的整个推理过程被完整地表示为一个结构化的文本序列。论文发现,通过大量采样(即让模型对同一个问题生成多次不同的推理路径),LLM确实有能力在其内部知识中找到正确答案。他们使用pass@k指标来衡量这一能力,即生成k次回答中,至少有一次是正确的概率。实验表明,随着采样次数k的增加,LLM找到正确答案的概率显著提升,呈现出清晰的“缩放定律”(Scaling Law)。
这揭示了一个关键洞察:LLM内部蕴含着巨大的、可被激发的知识潜力。然而,这也引出了新的挑战:虽然正确答案可能隐藏在成千上万的采样结果中,但我们如何让模型稳定、高效地找到那个最优的解,而不是依赖于暴力采样呢?
第二阶段:引入SSRL(Self-Search Reinforcement Learning)
为了让模型学会更有效地进行“自我检索”,研究者们引入了强化学习,设计了SSRL框架。其核心思想是,将“自我检索”的过程视为一个RL任务,模型本身既是执行思考和搜索的“智能体”(Policy Model),又是提供知识的“环境”(World Model / Search Engine)。
在这个框架下,模型生成的每一个完整的“自我检索”轨迹都会得到一个奖励信号。这个奖励信号会告诉模型,这次的检索做得好不好。通过不断地优化,模型会逐渐学会如何更高效地组织思考、提出更精准的内部查询、并利用自己生成的知识,最终导出正确的答案。
SSRL的训练是“完全模拟”的,意味着它在训练过程中不需要任何一次真实的API调用,完全依赖模型自身的参数进行知识的生成和提炼。这种方式不仅极大地降低了训练成本,还使得训练过程更稳定、可控。
更令人兴奋的是,通过SSRL训练出的模型,其学习到的“如何进行结构化搜索和推理”的技能是具有泛化性的。在推理(或部署)阶段,我们可以无缝地将模型内部生成的“信息”替换为来自真实搜索引擎的结果。实验证明,这种“模拟到真实”(sim-to-real)的迁移效果非常出色,模型不仅能适应真实环境,其性能甚至还能得到进一步的提升。
方法解析:SSRL是如何炼成的?
现在,我们来深入剖析一下SSRL在技术上是如何实现的。整个框架可以分为两个核心部分:Inference-time Scaling of Self-Search(用于评估模型潜力)和 SSRL(用于提升模型能力)。
1. 自我检索的潜力评估
在正式开始强化学习之前,研究者们需要先搞清楚LLM的“家底”到底有多厚。
- • 任务形式化
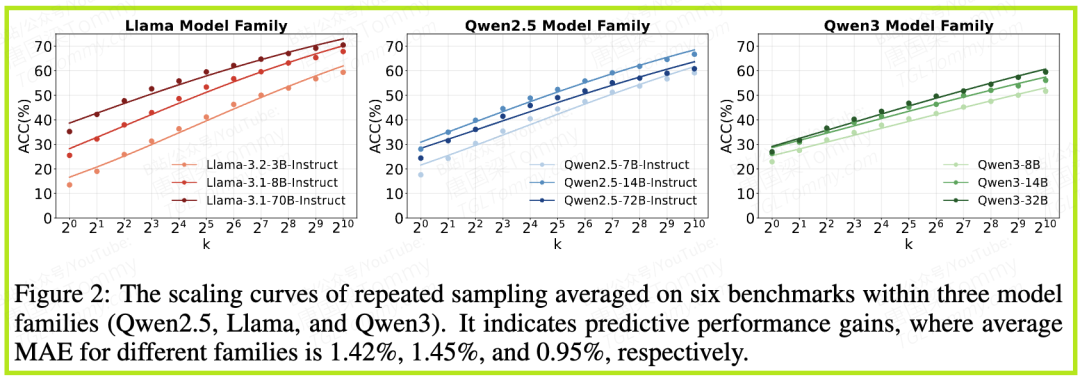
他们采用了
pass@k这一评估范式。pass@k的计算公式如下: 其中,是对一个问题总的采样次数,是其中正确回答的次数。这个公式的直观含义是:对于一个问题,我生成个答案,其中有个是正确的。现在我从这个答案中随机挑出个,这个里至少有1个是正确的概率是多少。这个指标能够很好地反映模型知识的“覆盖率”或“上限”。
- • 提示设计
为了引导模型进行结构化的自我检索,他们设计了包含
<think>,<search>,<information>, 和<answer>等XML标签的提示模板。模型被要求遵循思考 -> 搜索 -> 获取信息的循环,直到找到最终答案。这个过程是自回归的,模型在一个序列中生成所有内容,这与传统的需要与外部工具进行多轮真实交互的Agent有本质区别,效率极高。
2. SSRL的训练方法
评估完潜力后,就轮到强化学习登场了。SSRL的目标是让模型在众多可能的推理路径中,学会选择最优的那条。
- • RL目标函数传统的搜索智能体RL目标可以表示为: 这里的代表从外部搜索引擎检索到的信息。而在SSRL中,由于信息也是由模型自身生成的,所以目标函数简化为: 在这个设定中,策略模型同时扮演了推理者和内部搜索引擎两个角色。论文主要采用了GRPO(Group Relative Policy Optimization)算法进行训练。
- • 奖励模型 (Reward Modeling)一个好的奖励函数是RL成功的关键。SSRL设计了一个复合奖励,包含两个部分:
结果奖励 (Outcome Reward):这是最直接的奖励。如果最终答案
ŷ与标准答案y匹配,则奖励为+1,否则为-1。 格式奖励 (Format Reward):为了鼓励模型生成结构清晰、遵循think-search-information循环的推理链,研究者引入了格式奖励。如果模型的输出严格遵守了预定义的结构,它就会获得一个正向的格式奖励。这非常重要,因为它能确保模型学习到的“搜索”行为是规范的,便于后续与真实搜索引擎对接。 最终的总奖励是这两者的加权组合,给予结果正确性更高的权重。 - • 信息令牌掩码 (Information Token Mask)
这是一个非常有趣的训练技巧。在计算损失函数时,模型自己生成的
<information>标签内部的令牌会被掩码(mask out),不参与梯度更新。为什么要这样做呢?直观的解释是,这能防止模型“抄近道”。如果不加掩码,模型可能会倾向于生成一些简单的、它自己容易“解释”的信息,而不是真正去学习如何根据复杂信息进行推理。通过掩码,模型被强迫去关注“思考”和“回答”部分,学习如何利用信息,而不是如何生成信息,这使得它在后续接入真实、多样化的外部信息时,表现得更加鲁棒。
通过以上这些精心设计,SSRL构建了一个闭环的、自给自足的训练流程,让LLM在“自我对话”中不断提升其内在的搜索与推理能力。
实验探究:SSRL的真实实力
实验设置
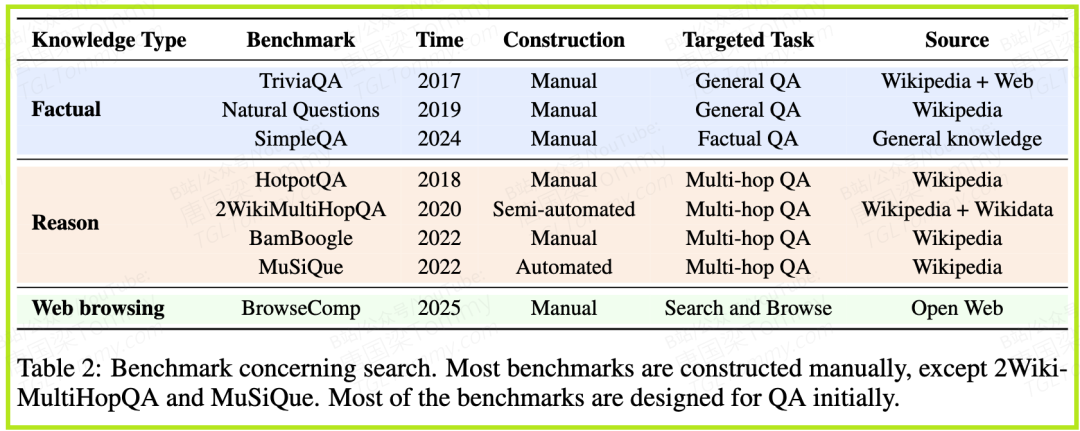
- • 基准测试:涵盖了多种问答任务,包括事实性问答(如TriviaQA, Natural Questions)、多跳推理问答(如HotpotQA, 2WikiMultiHopQA)和需要网络浏览的复杂任务(BrowseComp)。
- • 对比模型:
- • 无外部工具: Direct Answer, Chain-of-Thought (CoT)。
- • 基于RAG/搜索: Standard RAG, Search-o1。
- • 基于RL: R1, Search-R1 (使用真实搜索引擎训练), ZeroSearch (使用另一个LLM作为模拟搜索引擎训练)。
- • 基础模型:主要基于Llama系列模型(如Llama-3.2-3B, Llama-3.1-8B)进行实验,同时也包含了与Qwen系列的对比。
关键实验结果与分析
1. SSRL性能全面超越
从Table 3的核心结果来看,SSRL在所有六个基准测试的平均分上,都显著优于所有对比方法。无论是与同样使用内部知识的CoT相比,还是与那些在训练中使用了外部搜索引擎(如Wikipedia或Google)的Search-R1和ZeroSearch相比,SSRL都表现出明显的优势。
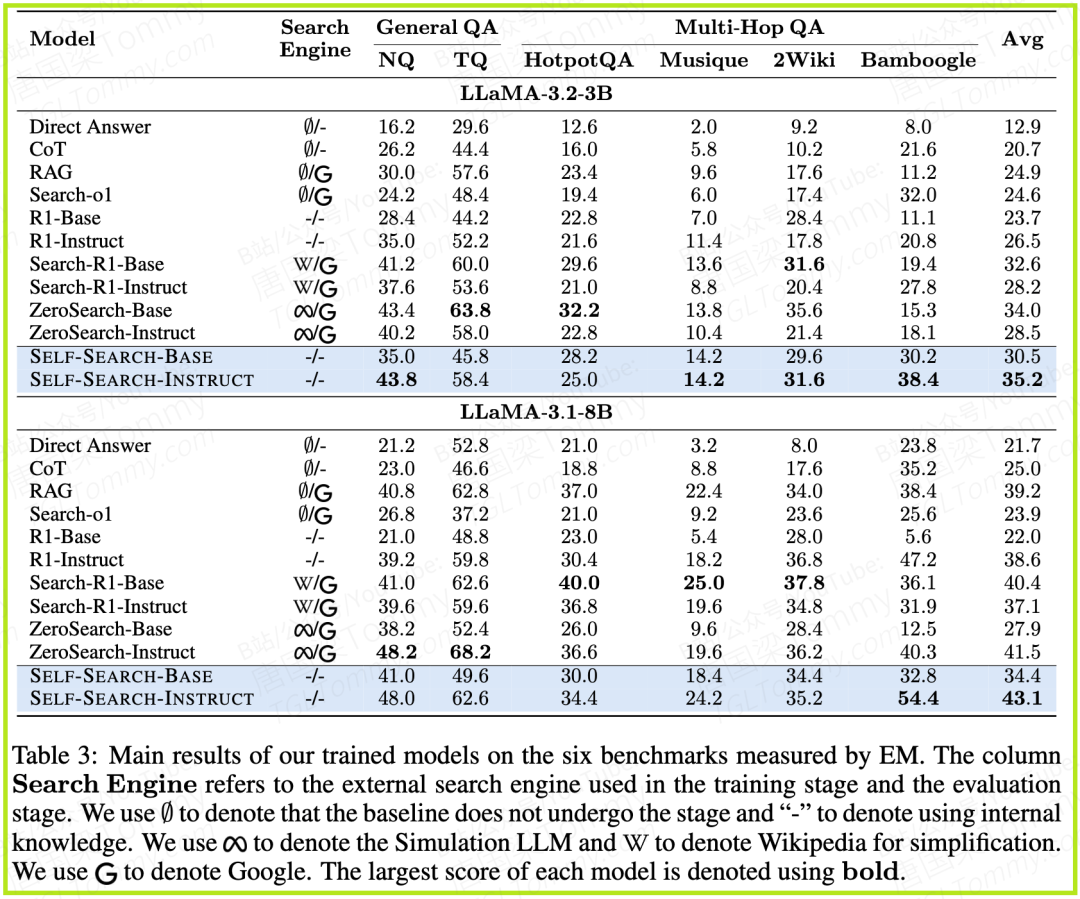
这个结果极具说服力:通过纯粹的自我模拟训练,SSRL达到的性能水平,甚至超过了那些依赖外部真实数据源进行RL训练的模型。 这证明了激发和组织LLM的内部知识是一种非常有效的策略。
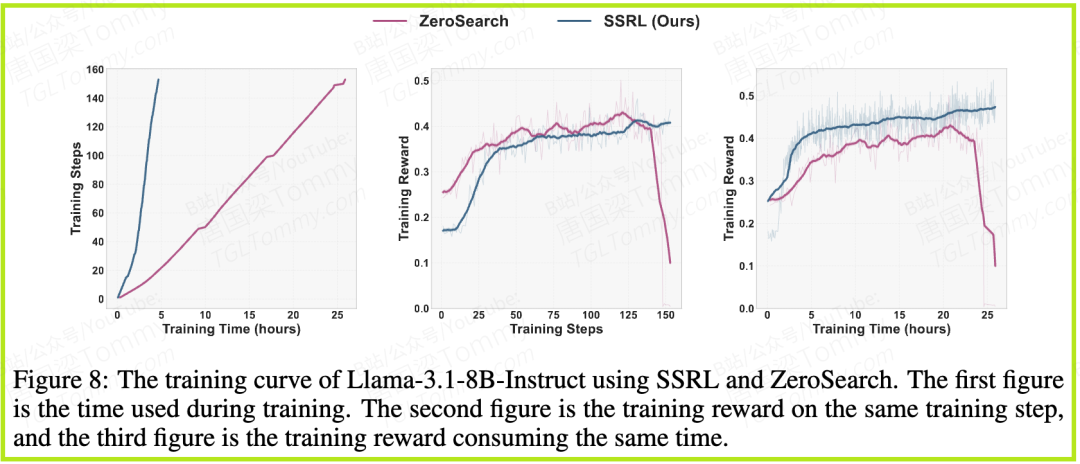
2. 训练效率的巨大优势 与ZeroSearch(它需要一个额外的、更强大的LLM来模拟搜索环境)相比,SSRL的训练效率实现了惊人的提升。Figure 8显示,达到相似的奖励水平,SSRL所需的训练时间大约是ZeroSearch的1/5.5。这得益于SSRL的“自给自足”模式,它不需要在模型之间进行额外的推理调用,极大地简化了训练流程,降低了延迟。
3. 强大的Sim2Real泛化能力
这是SSRL最激动人心的特性之一。当把SSRL训练好的模型,在推理时接入真实的Google搜索后,其性能得到了普遍的提升。Table 4展示了“Sim2Real”的结果。以Llama-3.2-3B-Instruct模型为例,纯SSRL的平均分为35.2,在接入真实搜索后(Sim2Real K=3),平均分飙升至41.9。
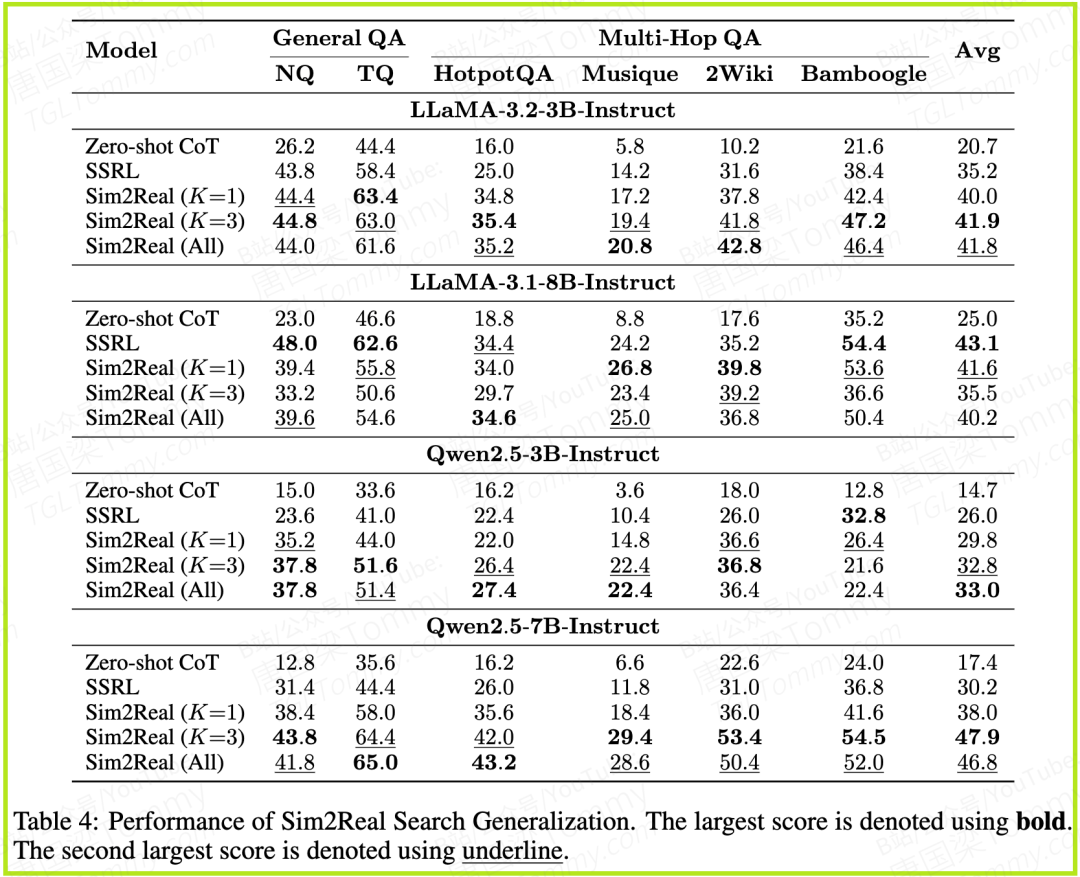
更有趣的是Figure 9的帕累托前沿图,它展示了性能与平均在线搜索次数之间的权衡。可以看到,SSRL系的Sim2Real模型(紫色、绿色点)在相同的性能水平下,通常需要更少的在线搜索次数;或者在相同的搜索次数下,能达到更高的性能。这表明,SSRL模型学会了何时应该依赖自己的内部知识,何时才需要求助外部工具,实现了“好钢用在刀刃上”。
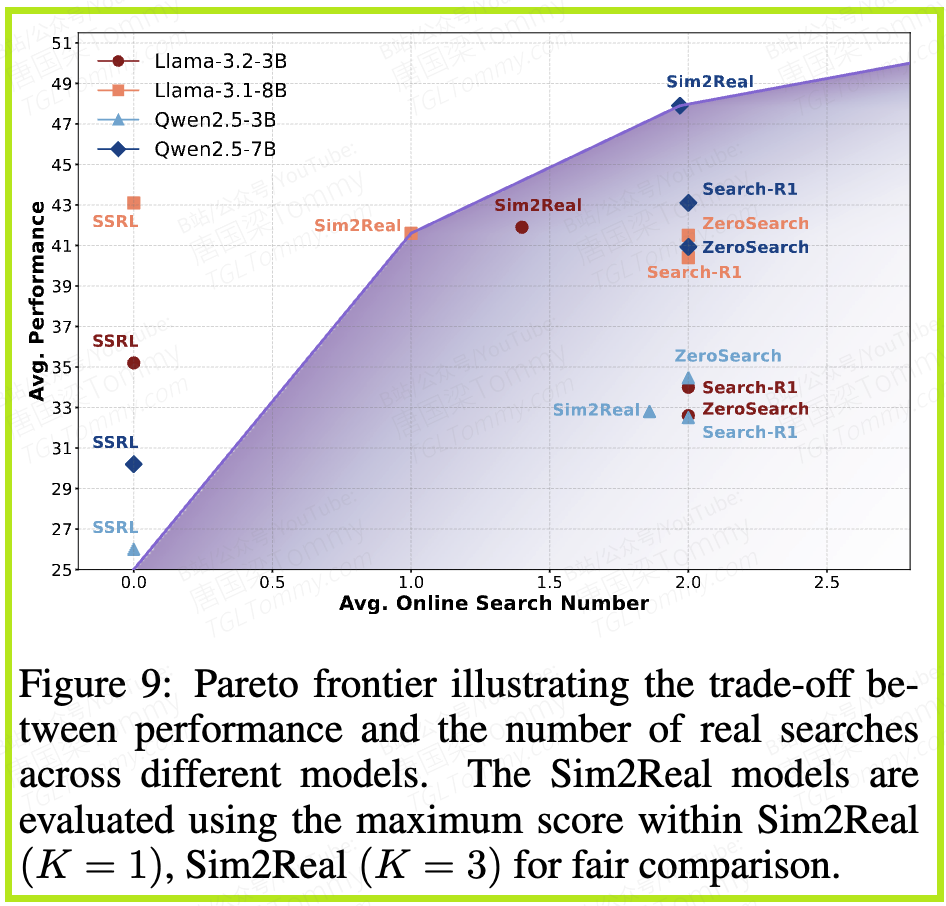
4. 对模型内在能力的深度洞察
论文的前期实验也提供了一些关于LLM内在知识的有趣发现:
- • 采样能有效提升性能上限:
pass@k的结果表明,LLM的知识广度远超单次Greedy Search所能展现的。 - • Llama比Qwen更擅长“自我检索”:尽管Qwen在数学推理等任务上表现优异,但在这些知识密集型任务中,Llama家族的模型展现出更强的内在知识储备和利用能力。
- • 简单的多数投票(Majority Voting)效果不佳:这说明从多个采样结果中选出正确答案本身就是一个难题,也凸显了用RL来学习最优选择策略的必要性。
总结与启示
SSRL为我们揭示了一个充满想象力的未来:AI智能体或许可以不那么依赖于时刻在线的、昂贵的外部工具,而是更多地依靠自身强大的内在知识库来解决问题。
当然,SSRL也并非终点。如何更可靠地提取知识、如何处理LLM内部知识的“幻觉”和过时问题、以及如何将这种自我检索能力扩展到更复杂的多模态任务中,都将是未来值得探索的方向。
论文名称:SSRL: Self-Search Reinforcement Learning
第一作者:清华大学
论文链接:https://www.arxiv.org/abs/2508.10874
最新日期:2025年8月14日
github:https://github.com/TsinghuaC3I/SSRL.git本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号