RNN 终于学会"翻笔记"了?Google 这篇论文让循环网络记忆力暴涨

RNN 终于学会"翻笔记"了?Google 这篇论文让循环网络记忆力暴涨

唐国梁Tommy
发布于 2026-06-25 21:31:12
发布于 2026-06-25 21:31:12
你有没有过这种体验:考试的时候,明明复习过的知识点,答题时死活想不起来?
AI 模型也有同样的烦恼。当前最火的 RNN 类模型(Mamba、RetNet、Titans 这些),处理长文本时就像一个只有固定大小草稿纸的学生——读到后面,前面的笔记就被覆盖了。
Google Research 最新的一篇论文提出了一个巧妙的解决方案:别擦草稿纸,每隔一段就拍张照存档,需要的时候翻回去查。
这个方法叫 Memory Caching(MC),,效果却好到离谱。

来自 Google Research、Cornell 和 USC 的联合团队
RNN 的"金鱼记忆"有多严重?
目前序列建模有两大阵营:
- Transformer(GPT、LLaMA):把所有历史都存在 KV Cache 里,什么都记得住,但显存随文本长度线性爆炸,又贵又慢
- 线性 RNN(Mamba、RetNet 等):把历史压缩成一个固定大小的矩阵,显存恒定、速度飞快,但——记忆容量是死的
打个比方:Transformer 是拿无限大的笔记本记东西,RNN 是拿一块白板——写满了就得擦掉旧内容才能写新的。

左:RNN 的固定白板,旧信息被覆盖;右:Transformer 的无限笔记本,全量保留
这在短文本上没问题。但当你让 RNN 读一篇 16000 词的长文,然后问它第一段里的一个细节——它大概率答不上来,因为那条信息早就被后面的内容覆盖了。
这不是"学不会"的问题,是"记不住"的问题。RNN 的遗忘不是因为信息消失了,而是被后续 token 的更新给覆盖了。
在经典的 Needle-in-a-Haystack(大海捞针)测试中,RNN 的表现堪称灾难——关键信息的召回率有时只有 4%,几乎等于瞎猜。
核心思路:给 RNN 装一个"存档系统"
Memory Caching 的核心想法,用一句话就能说清:
把长序列切成若干段,每段读完后把当时的记忆状态"拍快照"存起来,之后需要时可以回头查。
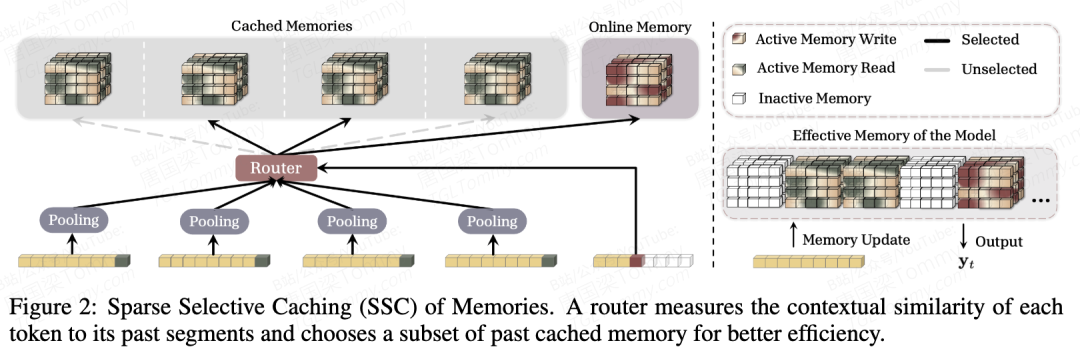
每个 token 不仅能访问当前段的在线记忆,还能检索所有历史段的缓存记忆
具体来说分三步:
- 分段压缩:把长序列切成 N 段,每段独立用 RNN 处理,生成一个"压缩记忆"
- 存档检查点:每段结束时,把记忆状态冻结存入缓存池
- 跨段检索:当前 token 需要历史信息时,对所有存档发起查询
这就像你读一本书,每读完一章就写一页摘要夹在书里。读到最后一章时,如果需要回忆第一章的内容,不用重新翻书——直接看摘要就行。
最妙的是:这是一个即插即用的插件,不改 RNN 的内部架构。Mamba、RetNet、Titans——任何现有 RNN 都能直接加上去。
用一个例子讲透整个流程
假设模型在读一段 9 句话的短文,分成 3 段(每段 3 句),最后要回答"条约在哪里签的?":
段 1:① 条约在巴黎签订。 ② 涉及贸易关税。 ③ 双方同意和平。
段 2:④ 那年冬天很冷。 ⑤ 人群聚集。 ⑥ 记者拍照。
段 3:⑦ 历史学家赞扬协议。 ⑧ 影响了欧洲政治。 ⑨ 条约在哪签的?⬅ 当前查询纯 RNN 的困境:读到第 ⑨ 句时,段 3 的记忆里只有"历史学家、欧洲、问题"这些信息,"巴黎"早就被覆盖了。查询命中率约等于零,回答失败。
加上 Memory Caching 后:段 1 和段 2 的记忆快照都在缓存里。第 ⑨ 句的查询会同时检索三段的记忆——段 1 的快照里"条约+地点"的信息与查询高度匹配,"巴黎"被成功召回。

分段压缩 → 存档检查点 → GRM 门控检索,Cache₁ 以 0.88 的权重命中答案
四种检索策略,从简单到聪明
论文不只提了一种方案,而是系统性地设计了四种聚合策略:

从零参数的 Residual 到稀疏路由的 SSC,四种策略各有取舍
1. Residual Memory(残差记忆)——最简版
把所有历史段的查询结果直接加起来。零额外参数,部署简单。
缺点是"一视同仁"——无关的段也会贡献噪声。就像你问"巴黎在哪",段 2 那些关于天气和记者的无关信息也被混进来了。
2. GRM(门控残差记忆)——最强版
这是论文效果最好的方案。核心升级:加了一个"相关性打分器"。
每段历史记忆都有一个语义摘要(段内所有 token 的均值),当前查询会和每段摘要计算相似度,得到一组权重。相关的段权重大,无关的段权重接近零。
回到刚才的例子:
- 段 1(条约、贸易、和平)→ 相关性 0.88
- 段 2(天气、人群、照片)→ 相关性 0.04
- 段 3(历史、欧洲、问题)→ 相关性 0.08
段 2 的噪声被压制到几乎为零,"巴黎"的召回置信度大幅提升。
3. Memory Soup(记忆汤)——参数融合版
不是在输出层加权,而是直接把多段记忆的模型参数做平均,融成一个"万能记忆模块"。推理只需一次前向传播,速度快,但精度略低于 GRM。
4. SSC(稀疏选择缓存)——效率优化版
当历史段数特别多时,连 GRM 也扛不住。SSC 用 MoE 风格的路由器,只挑 Top-K 个最相关的段来查,其余直接跳过。
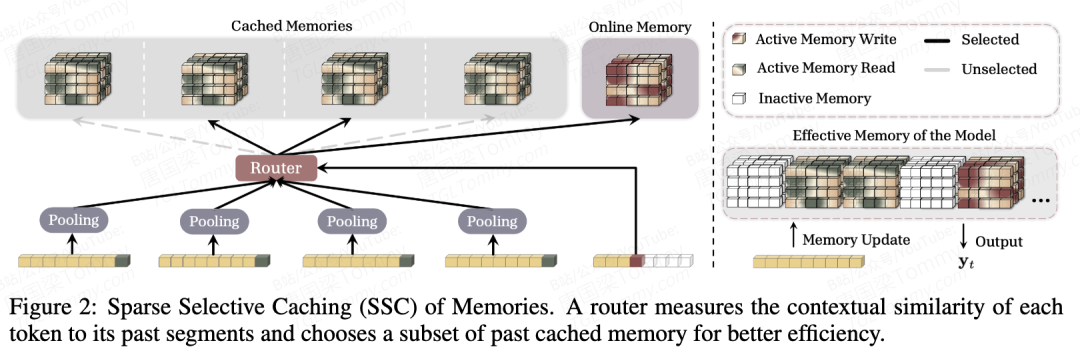
路由器计算每个段的相关性,只选中最相关的几个进行检索
实验结果:不是小幅提升,是量级突破
大海捞针:从瞎猜到能用
这组数据最震撼。在最难的 UUID 召回任务(S-NIAH-3,16K 上下文)中:
模型 | 召回率 |
|---|---|
DLA(纯 RNN) | 4% |
DLA + GRM | 18.2% |
Titans + GRM | 81.4% |
Transformer | 69.2% |
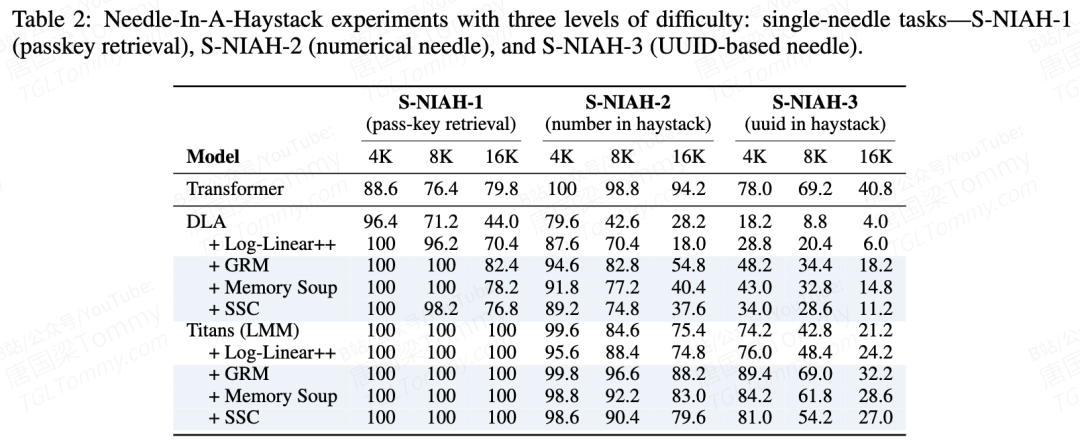
DLA 加上 GRM 后提升了 355%——MC 不是锦上添花,是从"废掉"到"能用"的关键开关。而 Titans + GRM 甚至反超了 Transformer。
语言建模 & 常识推理
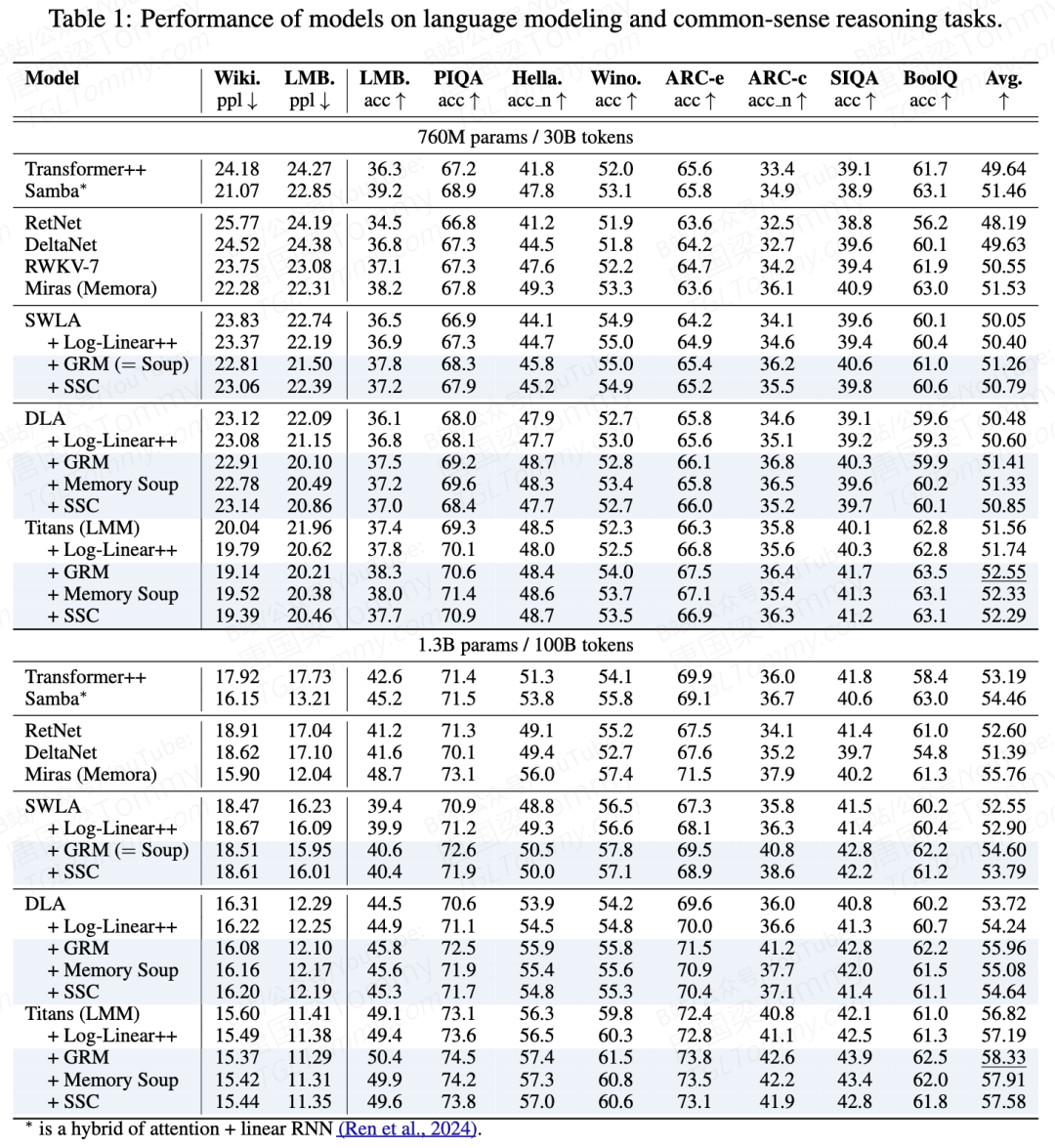
在 1.3B 参数 / 100B token 设置下,Titans + GRM 平均 58.33%,超越 Transformer++ 的 53.19%,领先约 5 个百分点。这在语言建模领域算是相当大的差距了。
长文档检索
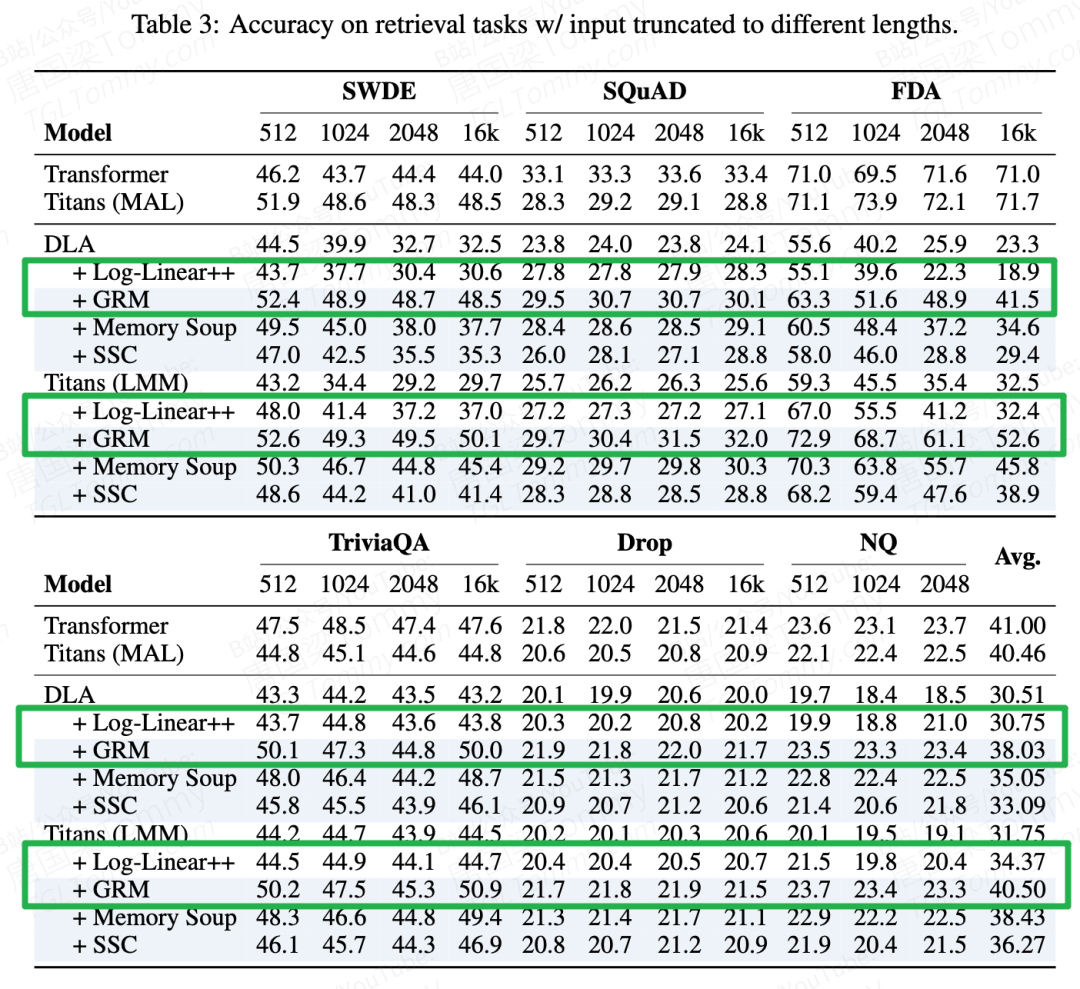
在 SQuAD、TriviaQA 等检索任务上,GRM 变体同样稳定领先,尤其在输入长度拉到 16K 时优势更加明显——正是 RNN 最吃力的场景。
一个优雅的统一视角
论文还证明了一个让人拍案叫绝的理论结论:
标准 Attention 就是分段大小为 1 的 Memory Caching。
当每个 token 都是独立一段时,MC 退化为对全序列做精确检索——这不就是 Attention 干的事吗?
这意味着 Transformer 和 RNN 不是两种对立的架构,而是同一个框架的两个极端:
- 分段大小 = 1 → 纯 Attention()
- 分段大小 = L → 纯 RNN()
- 分段大小 = C → MC(,可调)
通过一个旋钮(分段大小 C),你可以在效率和记忆力之间平滑切换。这也从理论上解释了为什么 Hybrid 模型(Mamba + Attention 混搭)有效——它们无意中在做一种粗糙的 Memory Caching。

调节分段大小 C,就能在纯 RNN 和纯 Attention 之间平滑插值
有哪些局限?
公平地说,MC 不是万能药:
- 段长需要调参:最优分段大小对任务和架构很敏感,目前没有自适应方案,需要手动搜索
- 深度记忆的显存开销:对 Titans 这种用 MLP 做记忆的模型,每个检查点要存一整个 MLP 的参数,段数多了显存可能反超 KV Cache
- 短序列反而变慢:文本不到 512 token 时,分段检索的额外开销得不偿失
- 极长序列仍有挑战:序列超过百万 token 时,即便 SSC 也扛不住,需要更激进的层级缓存方案
而且这篇论文(2026 年 2 月提交)目前还没经过同行评审,复现性存疑——尤其是需要定制 CUDA kernel 这一点,对一般团队并不友好。
最后的思考
Memory Caching 给我最大的启发是:有时候最好的解决方案不是重新发明轮子,而是给现有轮子加个好用的配件。
MC 没有设计新的 RNN 架构、没有发明新的注意力机制,它只是说:嘿,你每隔一段存个档不就完了?
这种"不改内核、只加插件"的思路,在工程上特别有吸引力。你不需要从头训练一个新模型,现有的 Mamba、RetNet 都能即插即用。
但我更好奇的是:如果我们把这个思路推到极致会怎样?
比如给 MC 加上类似操作系统的页面置换算法(LRU/LFU),动态淘汰不常用的检查点?或者把 MC 用在视频理解上,给数小时的长视频做记忆分段缓存?
RNN 和 Transformer 之争也许从来不是"谁取代谁"的问题,而是如何在同一个连续谱上找到最优点。MC 给出了一个漂亮的答案,但这条路才刚开始走。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号