vLLM的语义路由框架:把"改策略"从工程问题变成配置问题

vLLM的语义路由框架:把"改策略"从工程问题变成配置问题

唐国梁Tommy
发布于 2026-06-25 21:32:11
发布于 2026-06-25 21:32:11
这篇来自 vLLM 开源社区的工作不是在刷榜,而是在解决一个实际的系统工程问题:当企业同时运行十几个来自不同提供商的语言模型,一条请求进来,谁来决定路由给哪个模型?依据什么?安全策略怎么执行?如果你的团队正在构建或维护多模型推理网关,这篇文章的内容和你的实际工作高度相关。它没有提出算法突破,但给出了一套系统性的工程框架。

论文名称:vLLM Semantic Router: Signal Driven Decision Routing for Mixture-of-Modality Models
论文链接:https://arxiv.org/pdf/2603.04444
github:https://github.com/vllm-project/semantic-router路由问题被低估了多久
大多数人对 LLM 路由的直觉是:把简单问题发给小模型,复杂问题发给大模型。这是对的,但只是冰山一角。
一个真实企业场景的路由系统需要同时处理这些问题:这条请求是否包含 PII(个人身份信息),能不能发出公司网络?这个用户的权限等级是否允许访问高级模型?当前请求是文本生成还是图像生成,要不要路由至扩散模型?现在各提供商的延迟和成本情况怎样,哪个性价比最高?模型返回的响应有没有幻觉?
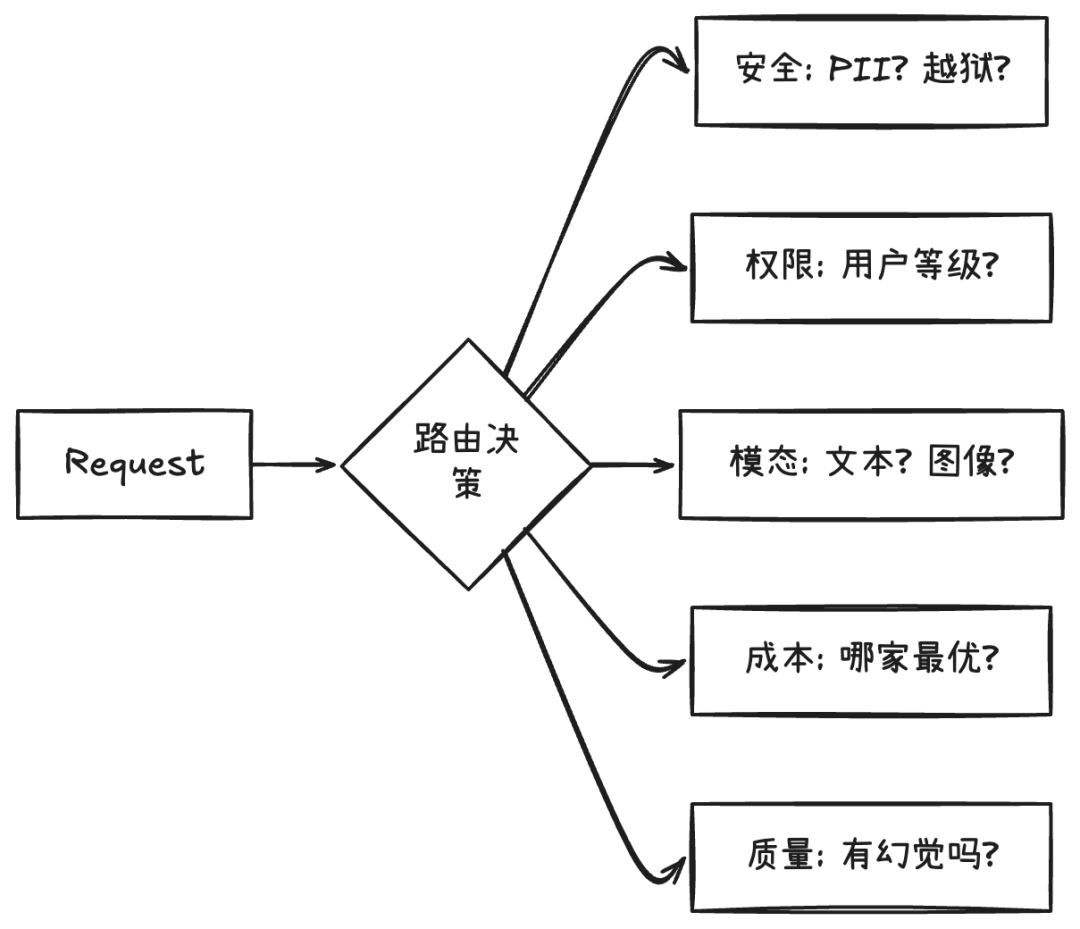
每一个问题单独处理都不难。但当你需要把它们组合成一套覆盖"医疗合规部署""开发者成本优化""多云企业级"三种截然不同场景的路由策略时,传统方式的局限就暴露了——策略逻辑散落在代码里,修改一个场景的 PII 阈值需要改代码、测试、重新部署。
这就是为什么 vLLM 社区用了 50+ 位工程师、600+ 次合并提交来做这件事。
核心思想:把策略从代码中剥离出来
这篇论文最本质的贡献,用一句话说:
用可组合的信号-决策-插件架构(Composable Signal Orchestration)将路由策略从代码中剥离,通过配置文件的不同组合,在同一套系统上服务完全不同的部署场景。
系统被分为三层:

Layer 1 – 信号提取层,负责从每条请求中提取结构化特征。信号分两类:启发式信号(关键词匹配、上下文长度、语言检测、权限角色)延迟小于 1ms;ML 信号(领域分类、嵌入相似度、模态检测、事实性判断)延迟在 10–120ms。两类信号并行执行,只计算当前配置实际用到的类型——这是一个关键工程优化,在只激活 3–5 种信号的典型配置下,可减少 50–70% 的信号提取总延迟。
Layer 2 – 决策引擎层,将信号向量输入 Boolean 决策树,匹配出最优决策 。每个决策规则可以写成任意深度的 AND/OR/NOT 组合,例如 AND(domain=healthcare, modality=vision, NOT(complexity=high))。基于经典 Boolean 代数的函数完备性定理,这套表达能力在理论上可以覆盖所有可能的路由策略。
Layer 3 – 插件链层,每个决策携带自己的插件执行链:越狱检测 → PII 过滤 → 语义缓存查询 → RAG 注入 → 模型选择 → 端点路由,响应侧执行幻觉检测和缓存写入。
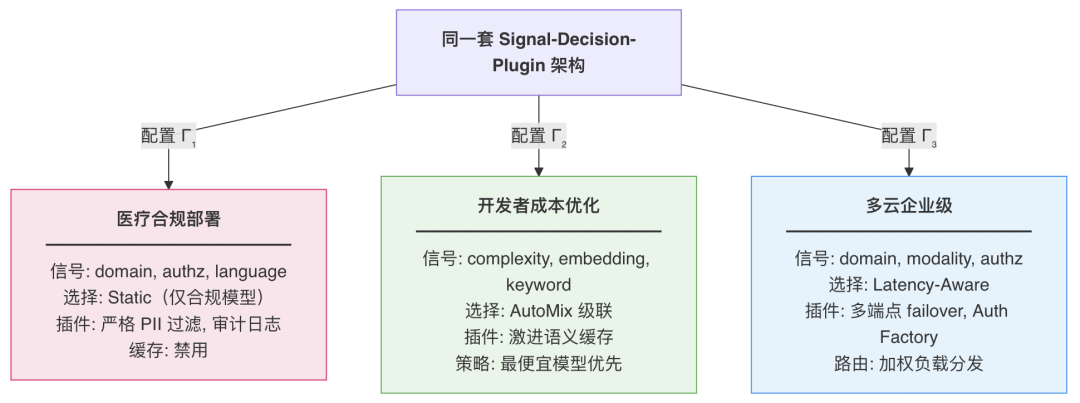
这三层之间通过干净的接口解耦。切换部署场景,等价于加载一个不同的配置文件 ,底层信号提取代码和插件实现代码完全不变。
图:可组合部署场景 — 同一套架构通过加载不同配置 Γ,服务截然不同的业务需求。
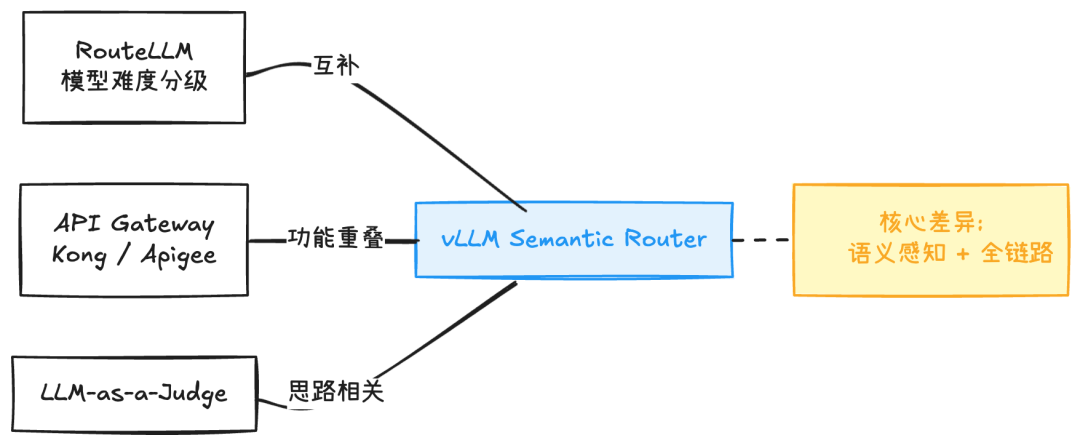
与同类方案(RouteLLM、RouterDC、AutoMix)的本质区别在于:前者都在解决"选哪个模型"这一个子问题,而这个框架解决的是"选模型"之外的所有问题——信号提取、安全策略执行、多提供商协议翻译、有状态多轮对话管理——并将它们统一在同一个可组合的架构中。
实验结果:哪些数字可信,哪些要打问号
论文给出了几个值得关注的数字:
LoRA 多任务内存节省:6 个分类任务(领域分类、越狱检测、PII、事实性、反馈、模态)共享一个 150M 参数基础模型 + 轻量 adapter,相比 6 个独立微调模型节省约 6× 内存(575MB vs 3438MB)。这个数字计算上没问题,逻辑也直接。 HaluGate 哨兵门控:40–60% 的查询被分类为非事实性,直接跳过 Detector 和 Explainer 两个重计算阶段,预期检测总成本降低约 50%。这个数字有条件依赖——如果真实工作负载中事实性查询占 80% 以上(比如金融问答场景),收益会大幅缩水。
图:HaluGate 三阶段门控流水线 — Sentinel 在请求侧过滤非事实性查询,仅对需要核查的响应执行 Detector + Explainer。

语义缓存命中率:精确重复查询命中率 100%(这是废话),改写后的同义查询在相似度阈值 0.92 下命中率 60–80%。这个范围很宽,实际业务中缓存召回率对阈值选择非常敏感,论文没有提供阈值-召回率的完整曲线。
需要指出的是,论文没有提供与 RouteLLM、OpenRouter 等现有方案的端到端性能对比表。它的实验更像是子系统验证(信号提取延迟、LoRA 内存对比),而非与竞争方案的横向评测。这在很大程度上是因为这个框架的定位不是刷某个路由 Benchmark,而是作为生产系统工具——但这也让学术上的有效性评估存在较大缺口。RouterBench 和 RouterArena 的协作评测说"正在准备中",是一个明显的未竟工作。
值得关注的设计细节
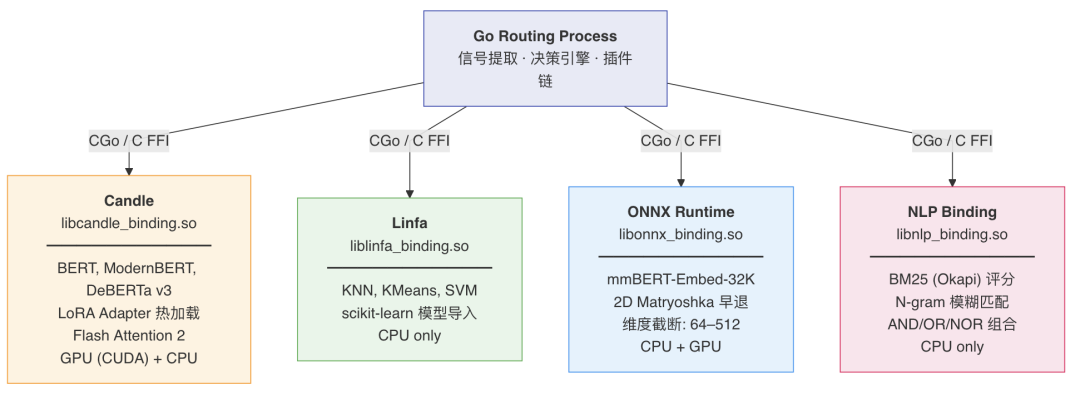
多运行时推理架构是这篇论文中另一个被低估的贡献。系统同时集成了四个 Rust 原生推理后端——Candle(GPU 加速 transformer 分类)、Linfa(CPU KNN/SVM)、ONNX Runtime(embedding 计算)、NLP Binding(BM25/N-gram 关键词匹配)——通过 CGo/C FFI 暴露给 Go 主进程。
这个设计选择消除了 Python GIL 竞争和跨进程 IPC 延迟,但同时也意味着极高的工程复杂度。能驾驭这套技术栈(Go + Rust + CUDA + gRPC + Envoy)的团队并不多。
2D Matryoshka 嵌入的设计值得单独关注:通过训练时的嵌套损失,embedding 模型在任意层早退(Layer 6/11/16/22)和任意维度截断(64/128/256/512)下都保持合理质量,使 CPU 推理延迟在 Layer 11 + dim 256 配置下可媲美 GPU 全模型。这对边缘部署场景(GPU 不可用)有实际价值。
和近期工作的关系
这个框架和 RouteLLM 是互补而非竞争:RouteLLM 专注于做好"强弱模型二选一"的难度分级,而 vLLM Semantic Router 把模型选择作为插件链中的一个步骤,同时处理安全、合规、多提供商等生产环境关心的问题。
它和 LLM-as-a-Judge 类方法(如 HaluGate 的 NLI Explainer 阶段所借鉴的思路)有明显的相关性,也和 API Gateway 产品(Kong、Apigee)有功能重叠——但核心差异在于它是语义感知的,传统网关不理解请求的内容。
对于正在构建 LLM 平台的工程师:这个框架更值得作为架构参考,而不是直接部署——其工程复杂度要求较高,但信号-决策-插件的三层解耦思想本身是值得借鉴的设计模式,即使你用更简单的技术栈实现一个裁剪版。
对于研究者:这篇论文提出的问题比它给出的答案更有价值——如何系统地评估多信号路由框架的路由质量,是一个真实存在且尚未有标准方法的开放问题。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号