看得见,才稳得住!DolphinDB 集群监控方案速览
原创
看得见,才稳得住!DolphinDB 集群监控方案速览
原创
DolphinDB
发布于 2026-06-30 16:59:29
发布于 2026-06-30 16:59:29
DolphinDB 集群承载着高并发读写、查询和流计算的硬任务,集群稳不稳,直接影响业务靠不靠得住。一套完善的监控体系,就是保障稳定运行的基础能力。CPU、内存、查询性能、节点状态、流计算、内存细粒度——指标覆盖越全面,你对集群的了解就越透彻。
为此,我们基于 DolphinDB Exporter + Prometheus + Grafana + dolphindb-datasource-next,整理出一套适用于单机部署、多人协作环境以及高可用集群的监控方案,帮助用户更低成本地搭建一套“可观测、可告警、可分析”的 DolphinDB 监控体系。
方案全景:四大组件,各司其职
从数据采集,到指标存储,再到可视化展示和异常告警,这套方案实现了完整的监控闭环。整体架构如下图所示,四个组件分工明确:
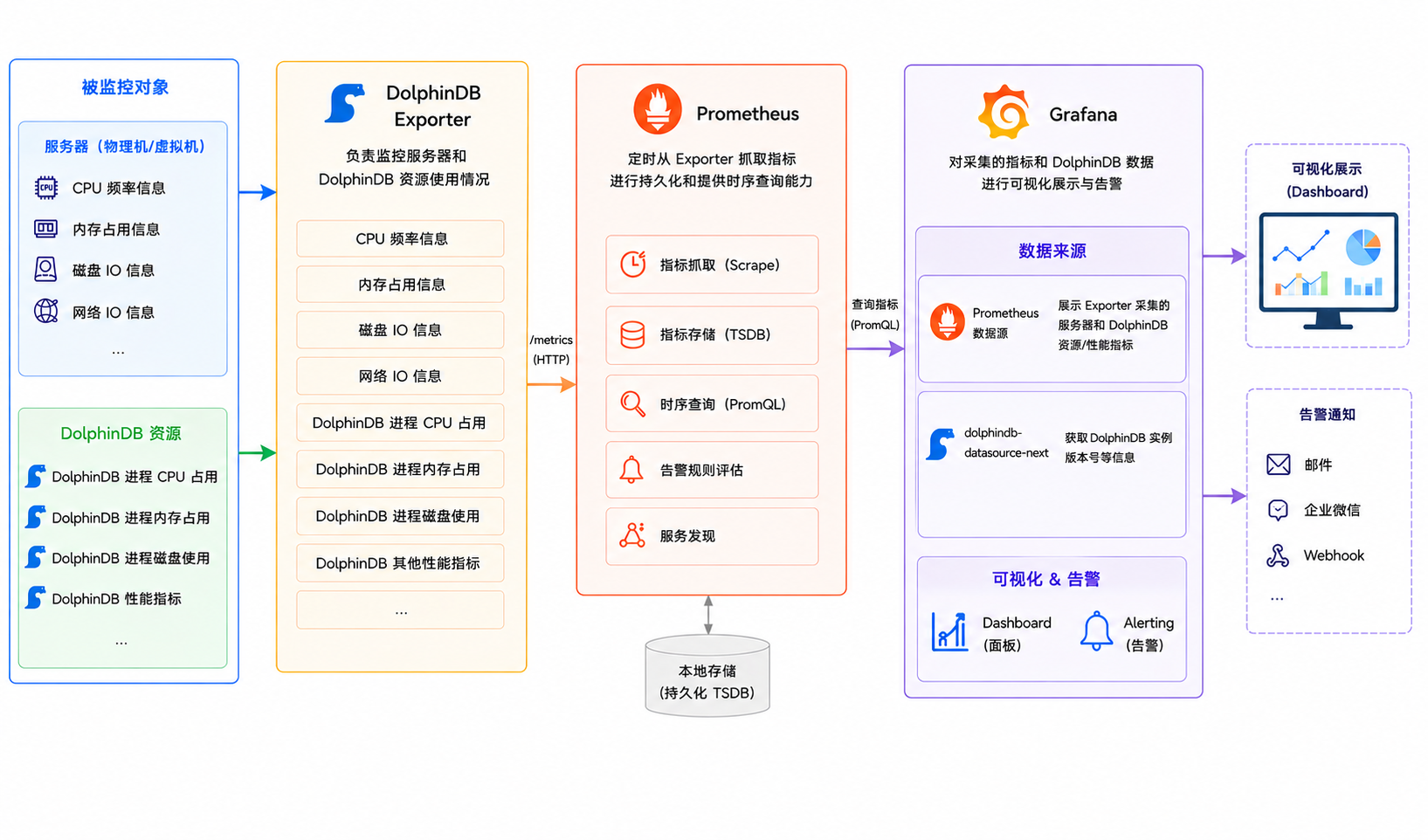
- DolphinDB Exporter:DolphinDB 官方出品的指标导出器,负责采集服务器资源(CPU、内存、磁盘 IO、网络 IO)和 DolphinDB 运行时指标。
- Prometheus:业界标准的时序数据库,定时抓取 Exporter 暴露的指标,并提供高效的时序查询能力。
- Grafana:强大的可视化与告警引擎,将 Prometheus 中的指标和 dolphindb-datasource-next 查询到的数据以 Dashboard 形式实时展示。
- dolphindb-datasource-next:DolphinDB 官方数据源插件,支持在 Grafana 数据面板(Dashboard)中通过编写查询脚本与 DolphinDB 进行交互,实现 DolphinDB 监控数据的可视化。
以上组件均可从各项目官网或 GitHub 直接下载,安装配置后即可投入使用。
三大核心亮点
亮点一:指标全面,六层覆盖一屏掌握
这套方案能看什么?简单来说,从服务器到数据库引擎,六层覆盖:
- 服务器层:CPU 使用率、内存占用、磁盘 IO、网络 IO
- DolphinDB 进程层:进程 CPU/内存/磁盘占用
- 查询性能层:查询耗时、作业负载、排队任务数,慢查询一目了然
- 流计算状态:订阅队列深度、引擎内存,保障实时链路稳定
- 集群健康:节点在线状态、分区状态、恢复任务状态
- 内存细粒度:各引擎缓存占用、用户内存分布,精准定位内存瓶颈
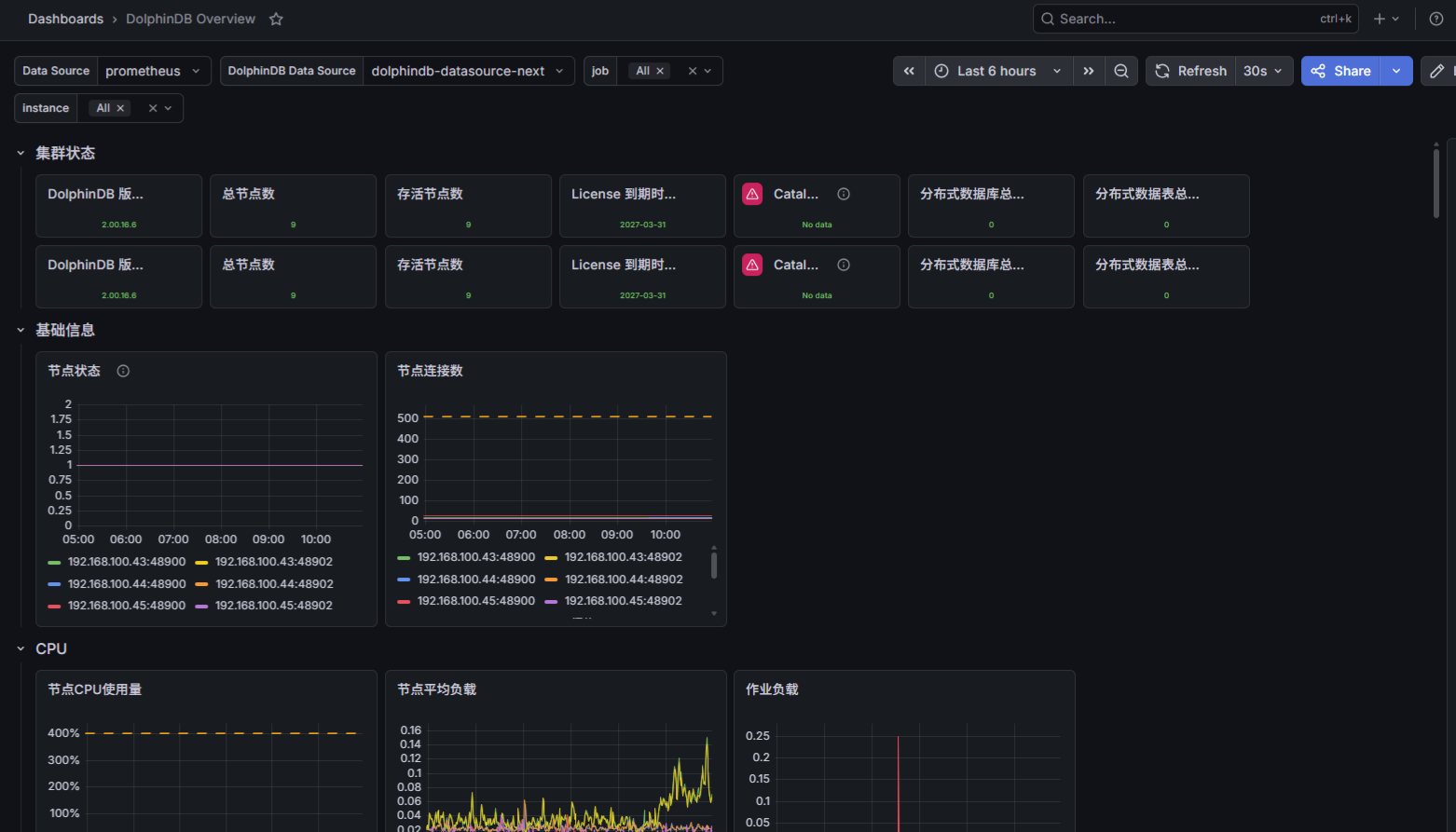
过去需要切换多个工具、依赖人工排查才能拼出来的信息,现在可以统一在一个 Dashboard 里查看。对于运维团队来说可以更快的发现并定位问题。配合预置的 dolphindb-overview Dashboard,基本可以做到导入即用,无需从零搭建监控面板。
亮点二:灵活告警,多渠道实时触达
监控的最终目的是及时发现问题。基于 Grafana 的告警能力,这套方案可以对关键指标设置阈值和评估周期,避免告警轰炸。一旦指标异常,就可以通过邮件、企业微信群机器人等方式触达相关人员。这类能力在生产环境里非常实用。相比人工巡检,自动告警可以把很多问题前置发现,避免小问题拖成大故障。相关运维人员可参考 DolphinDB 官网“开发者中心—用户手册—故障排查”进行问题定位与处理。
亮点三:可扩展,支持自定义指标采集
默认指标已经足够覆盖大多数日常场景,但如果业务有更细的监控需求,这套方案也留出了扩展空间。DolphinDB Exporter 支持自定义指标——通过 YAML 配置文件配合 DolphinDB 脚本,用户可以按需采集自己关心的指标,例如正在执行的批处理任务数、按用户维度的任务分布、任务错误计数等。这意味着,监控不仅能覆盖系统层和数据库层,还可以进一步延伸到业务层。
适用场景
如果你的环境中存在以下需求,这套方案会是一个高效、实用的选择:
- 资源监控:实时掌握服务器与 DolphinDB 集群的资源使用状况
- 性能瓶颈定位:基于查询耗时、作业负载等指标,快速定位性能瓶颈
- 异常告警:集群节点掉线、资源超限等异常,多渠道及时通知
- 统一监控:同时支持单节点与高可用集群,一套方案适配不同部署规模
结语
这套方案依托 Prometheus + Grafana 开源生态,能够帮助用户快速搭建 DolphinDB 集群监控体系,让运行状态一目了然,异常问题及时告警。如果你正在使用 DolphinDB 集群,不妨试试这套方案,让集群的运行状态尽在掌握。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号