Claude Code Agent 设计的最佳实践:从 Anthropic 工程师的洞见中汲取灵感

Claude Code Agent 设计的最佳实践:从 Anthropic 工程师的洞见中汲取灵感

用户1640761
发布于 2026-07-01 21:48:59
发布于 2026-07-01 21:48:59
图像
大家好,我是"不一样的猿生"。今天,我们来聊聊 Claude Code 在构建AI Agent 方面的最新洞见。近日,Anthropic 的 Claude Code工程师Thariq 在X上分享了一篇深度文章,引发了广泛讨论。这篇文章聚焦于 AI Agent 的设计艺术,强调从 AI 视角出发,优化工具和上下文管理。作为Claude Code 的忠实用户,你们一定在日常编程中遇到过 Agent 混乱、提示膨胀的问题。今天,就让我们基于这篇分享,拆解核心技巧,帮助大家提升 Agent 开发效率。
为什么 Agent 设计是“艺术”而非“科学”?
Thariq在文章中直言, Agent 设计更像是一门艺术,需要不断迭代和直觉引导。不同于传统的软件工程,AI Agent 涉及模型的“认知”过程——如何让 Claude Code 高效处理任务,而不被海量信息淹没?许多开发者反馈,这篇文章让他们从“RAG(Retrieval-Augmented Generation)”模式转向更智能的上下文构建, Agent 性能提升显著。
关键在于:别把 Agent 当成万能工具箱,而是设计成一个高效的“思考者”。下面,我们逐一拆解文章中的金玉良言。
工具别给太多,4–5个就够了(真的)
最常见的错误:一股脑给代理塞50个工具。 结果模型像拿到一整个五金店的浣熊,乱抓一通,调用一堆没用的东西,token烧得飞起,还经常卡死。
正确做法:像给厨师准备工具,只给最合适的4–5把刀、锅、铲子。 工具越少、越清晰、命名越“像人会用的”,模型表现越好。
举例:
- • 坏:
execute_arbitrary_query_v3_advanced - • 好:
SearchWeb、ReadFile、WriteCode、AskUser
从模型视角去想:它只看到提示里那几行工具描述。如果描述写得人类味太重(啰嗦、模棱两可),它就会做出很怪的选择。
渐进式信息披露(Progressive Disclosure)——这是最大提升点
把2万字系统提示全塞进去是最蠢的做法之一。 上下文会“腐烂”(context rot):前面重要的东西被后面噪音盖掉,模型逐渐失忆。
我们现在几乎全部用这种方式:
- • 根目录放一个简短的
summary.md(技能总览,1–2屏能看完) - • 具体工具/知识/流程放进嵌套文件夹的markdown里,例如:
- •
/skills/search.md - •
/skills/code-review/grep-patterns.md - •
/memory/company-knowledge/product-specs.md
- •
代理只在真正需要时自己去读更深层的文件(用ReadFile或类似工具)。
这就像你做菜不会一次性读完整本菜谱,只翻到“红烧肉”那页。
这条实践后,很多人的代理从“经常跑偏”直接变成“像有大脑一样靠谱”。 有人甚至说:从RAG硬塞 → 让Claude自己grep构建上下文,是质的飞跃。
用“任务”而非“待办清单”(Tasks > Todos)
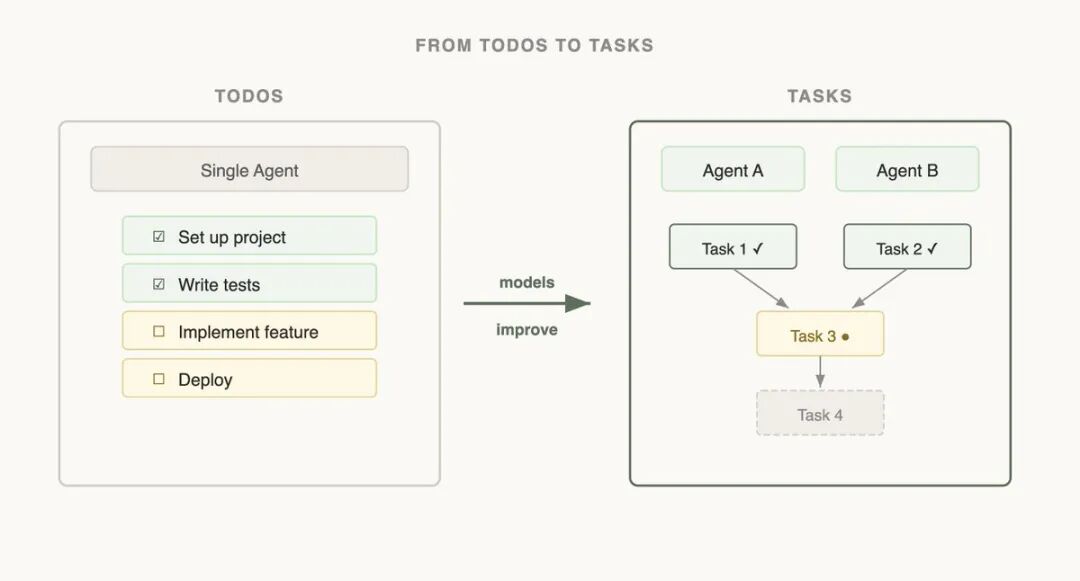
图像
传统的ToDo列表会让提示无限膨胀。 更好的方式:把状态(Memory)和计算(Interaction)解耦。
- • Memory Layer:用文件/文件夹持久化(JSON、Markdown都行)
- • Interaction Layer:当前这一步要干什么
多个子代理之间可以共享同一份Memory文件,不用在提示里重复塞状态。 这能大幅减少token消耗,也更容易debug。
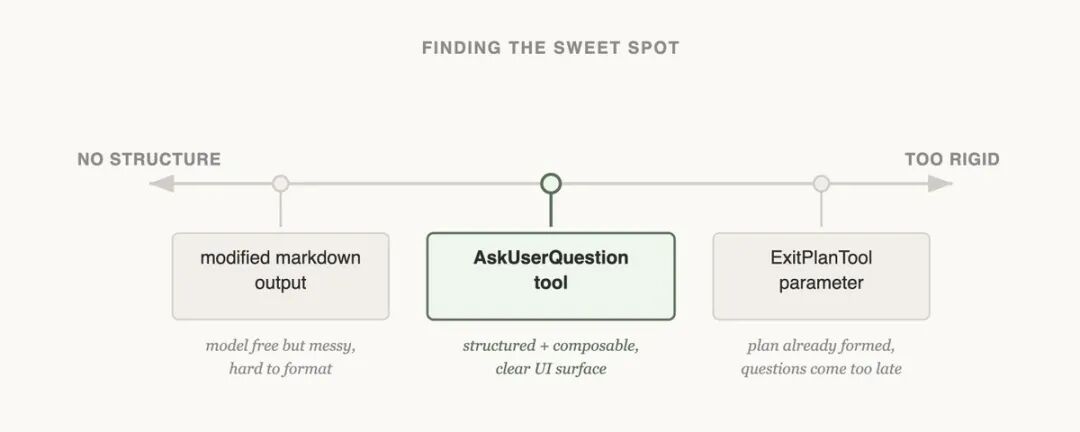
一定要有“AskUserQuestion”工具(或类似机制)
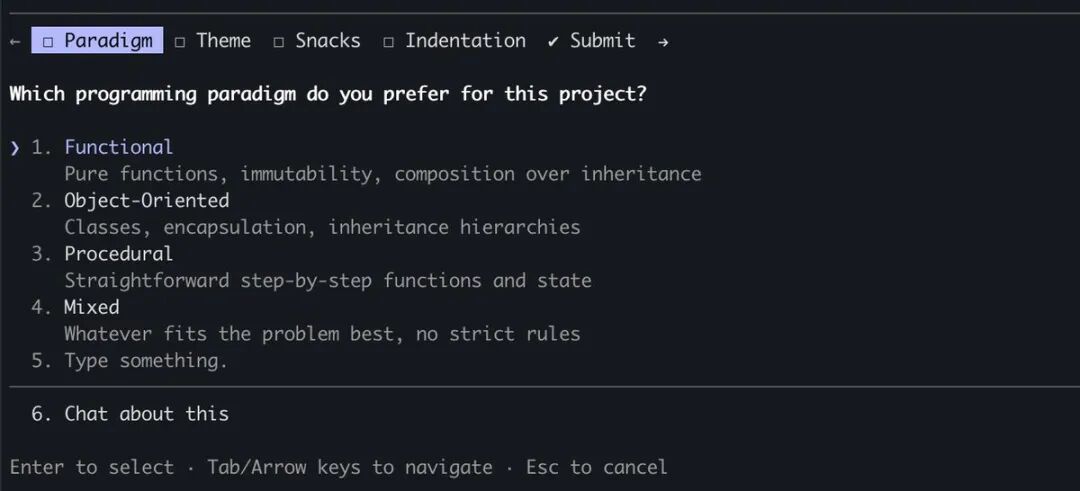
图像
当出现歧义、需要确认时,别让它自己脑补,直接问用户。 这是防止无限循环最简单粗暴有效的方法。
危险动作前必须“预览计划 + 等确认”
删文件、调用付费API、发邮件……这些操作前, 让模型先输出完整计划(步骤+预期结果),然后等你明确说“Yes”。
有人甚至做了专门的ExitPlanTool,输出结构化计划,用户确认后才真的执行。
这条不只是安全问题,还让整个系统变得可控很多。
文件系统竟然是目前最好的“AI大脑”
最意外的发现:给AI最好的长期记忆和技能扩展方式,竟然就是——好好整理的文件夹 + Markdown笔记。
- • 短总结在前面
- • 细节往深处嵌套
- • 需要时自己去翻
比起塞一个巨型提示,这干净、可维护、可版本控制、可搜索。 现在很多构建者已经把文件系统当成“代理的界面”来设计了。
从 AI 视角重塑你的 Agent
Thariq 的分享不是孤立的技巧,而是对 Agent 设计的哲学反思:像 Agent 一样思考。正如评论所言,每支 Agent 团队都会“速成”这个教训——从人性化工具到token优化,一切源于“Seeing like an agent”。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号