CVPR 2026 像专家标注一样思考!IBISAgent:多模态Agent自主多轮交互细粒度视觉推理框架

CVPR 2026 像专家标注一样思考!IBISAgent:多模态Agent自主多轮交互细粒度视觉推理框架

Amusi
发布于 2026-04-15 15:55:49
发布于 2026-04-15 15:55:49
【导读】IBISAgent让多模态大模型(MLLM)像人类专家标注员一样,通过自主多轮交互式推理与点击操作,逐步精化生物医学图像分割结果。无需修改模型架构,无需引入额外的隐式分割token,通过两阶段训练激发大模型内在的像素级视觉推理能力,在统一框架下首次实现高精度的生物医学目标指代与分割,全面超越现有SOTA方法。
人类专家在标注医学图像时,从不是 "看一眼就画出来"。
他们会先扫视全图、锁定可疑区域,随后在分割工具上反复点击正负样本,根据每一步生成的mask形态重新判断,不断调整策略——这是一个多轮交互、边看边想、边想边做的迭代推理过程。
然而,现有的医学多模态大模型普遍采用 "单次前向推理"范式:输入图像,输出mask,一步到位。这种方式面对生物医学图像中细微的病灶边界、复杂的解剖结构、模糊的视觉语义时往往力不从心。更深层的问题在于,为了赋予MLLM分割能力,现有方法普遍引入隐式分割token(如)并与外部pixel decoder联合微调——这一设计破坏了大模型原有的文本输出空间,导致语言推理能力退化,泛化能力大打折扣。
上述范式存在四个核心瓶颈:
单次推理无法自我纠错:一旦第一步定位出现偏差,错误持续累积,最终影响分割质量
隐式token破坏推理能力 :等token侵占文本空间,导致灾难性遗忘,细粒度视觉推理被严重压制
缺乏自主决策机制:模型只能被动执行单次指令,无法像人类专家一样主动观察、反思、调整
训练数据瓶颈:现有数据集只有最终mask,缺乏逐步交互的推理轨迹,难以直接监督多步行为
鉴于上述问题,浙江大学蔡钰祥教授、上海人工智能实验室研究员江彦开等人联合提出了 IBISAgent——一个将分割重新定义为多步视觉决策过程的 Agentic MLLM 框架。该成果已被 CVPR 2026 接收。

论文: https://arxiv.org/abs/2601.03054
代码: github.com/Yankai96/IBISAgent
主要创新点:
将分割任务建模为多步马尔可夫决策过程(MDP) ,以交错的文本推理与点击动作替代隐式token,保留MLLM完整的语言推理能力,同时实现自主多轮迭代精化
提出两阶段训练框架:首先通过冷启动SFT在自动生成的推理轨迹上建立像素级推理先验;随后引入Agentic强化学习,以细粒度奖励信号驱动模型自主探索更优决策策略,超越对轨迹的简单模仿
构建包含 456K 条高质量推理轨迹的冷启动数据集,覆盖正常标注与自我反思纠错两类轨迹,为多步视觉推理提供系统化的训练基础
方法
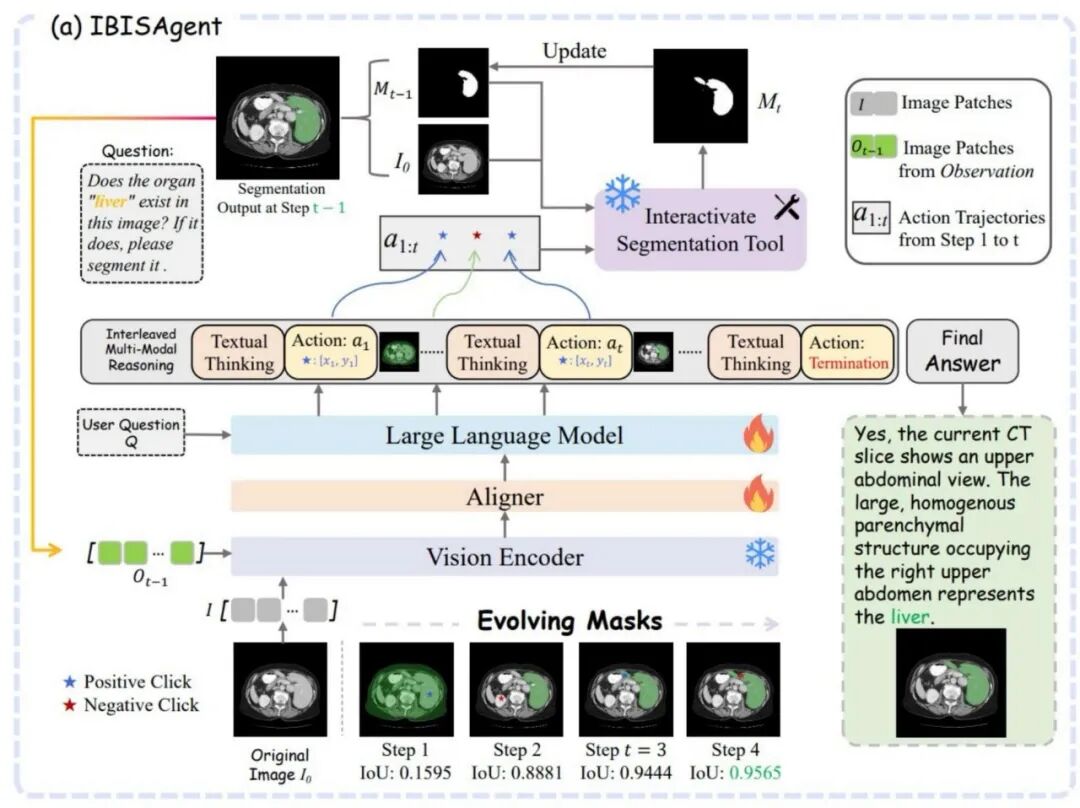
IBISAgent 将整个分割过程建模为一条多步推理轨迹,每一步由三个核心元素构成闭环:
推理(Textual Thinking) :模型对当前分割图像的状态进行推理分析,如 " 当前mask偏左,需要在右侧肿瘤边缘补充正向点击"。
行动(Action) :模型输出结构化的空间点击指令,包含三个要素:分割目标类别(Target)、点击属性(正/负,Attribute)、归一化图像坐标(Coordinate_2d)。模型可在一步中同时输出多个点击。
观测(Observation) :点击被传入交互式分割工具 MedSAM2,生成更新后的 mask,并叠加到原图上作为下一步的视觉输入反馈给模型。
这一设计的关键在于: 模型每一步都能"看到" 自己上一步分割的结果,形成视觉感知与语言推理的闭环。整个过程不引入任何新的模型组件或隐式token,分割能力完全从MLLM内在的视觉推理中涌现,并天然支持从头分割与mask精化两类任务。
IBISAgemt采用两阶段训练方案:
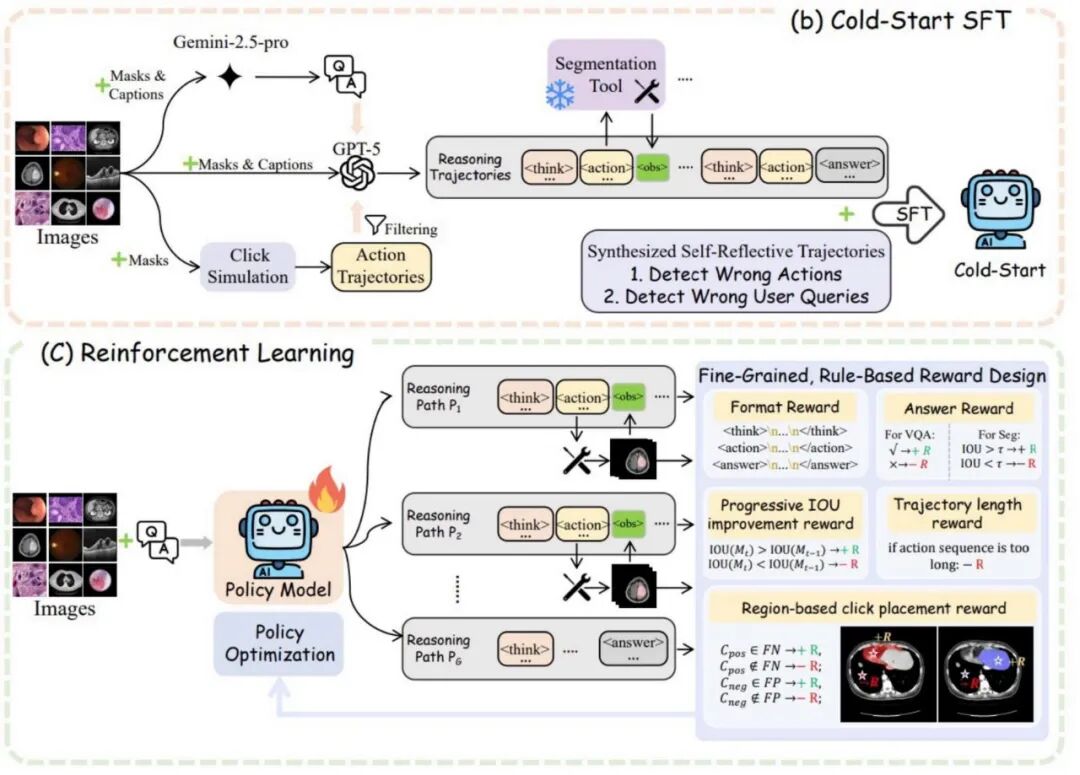
冷启动 SFT:
现有生物医学分割数据集只有最终mask,没有逐步点击轨迹。研究团队利用 BiomedParseData(340万图像-mask对, 9种成像模态)开发了自动轨迹生成算法:通过规则化的点击模拟策略自动推导点击序列,再用 Gemini- 2.5-Pro 为每步生成对应的自然语言推理。
为增强鲁棒性,额外合成两类自我反思轨迹:(1)错误自纠正——检测到错误动作后回溯并重新推理;(2)指令不一致纠正——遇到与初始mask不符的指令时主动丢弃并重新分割。最终构建出包含 456K 样本的高质量冷启动数据集。
Agentic 强化学习:
SFT之后模型仍在模仿已有轨迹,研究团队进一步引入RL,设计细粒度奖励框架在每个交互步骤提供密集反馈:
奖励信号 | 含义 |
|---|---|
格式奖励 | 输出结构是否合法 |
答案奖励 | 分割IoU / VQA准确率 |
区域点击奖励 | 点击是否落在语义有意义的FN/FP区域 |
渐进式分割改进奖励 | 每步mask质量是否优于上一步 |
轨迹长度奖励 | 鼓励用更短路径完成高质量分割 |
其中区域点击奖励与渐进式分割改进奖励是核心创新——前者引导模型将每次点击落在语义有效的区域,后者强制每步行动必须带来实质性的分割改善,从而彻底杜绝冗余操作与来回震荡。 RL训练使用 GRPO 算法,在 888K VQA样本上进行优化。
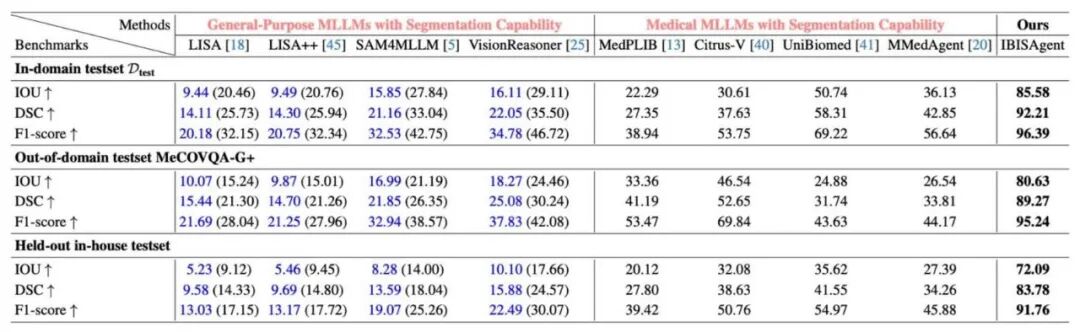
在域内测试集、域外泛化集(MeCOVQA-G+,涵盖5种成像模态)和自建私有数据集(1K CT/MRI/病理, 7类癌
症)三个benchmark上, IBISAgent均大幅领先所有对比方法。相比医学专用MLLM基线,平均 IoU 提升35.13%, DSC 提升 37.58%, F1 提升 29.79%。
值得注意的是, Citrus-V 和 UniBiomed 均在比本方法更大规模的数据集上训练, IBISAgent仍能一致超越,说明性能提升来自方法设计本身,而非数据优势。
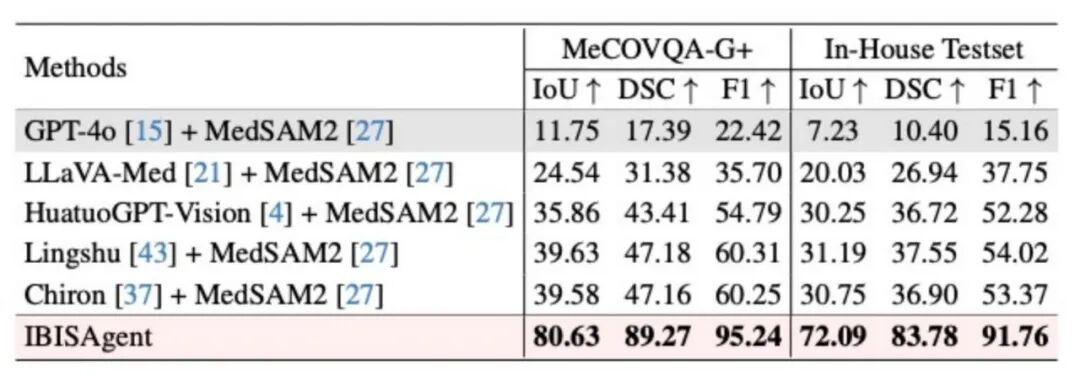
与工具增强Agent的对比实验
相比同样调用 MedSAM2 的工具增强型Agent(GPT-4o 、LLaVA-Med 、HuatuoGPT-Vision等), IBISAgent在域外集和私有数据集上仍保持显著领先,充分说明多轮交互式推理带来的增益远超简单的工具调用。
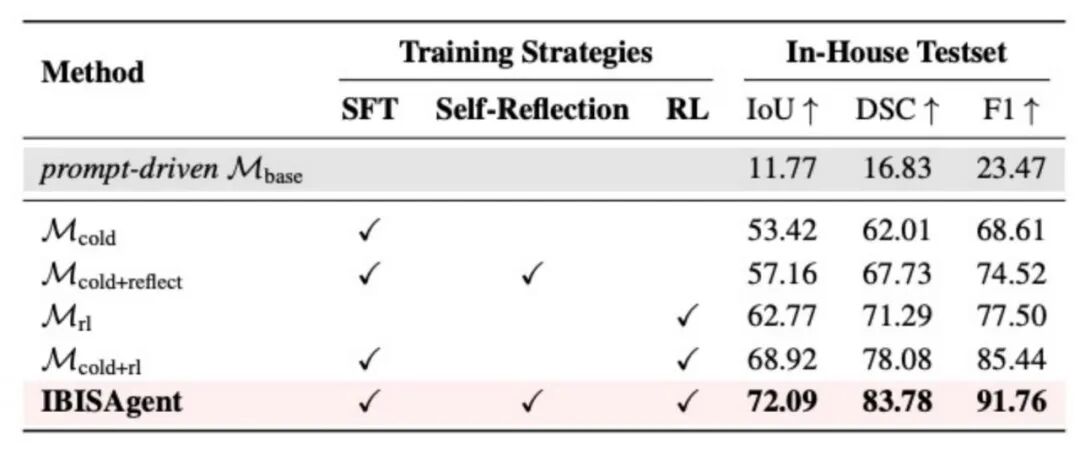
两阶段训练消融实验
消融实验证明,冷启动SFT、自我反思轨迹和RL三个方案缺一不可,逐级叠加均带来明显收益; RL阶段提供最大的性能跃升,说明强化学习的探索-利用机制对激发真正自主的像素级推理至关重要。
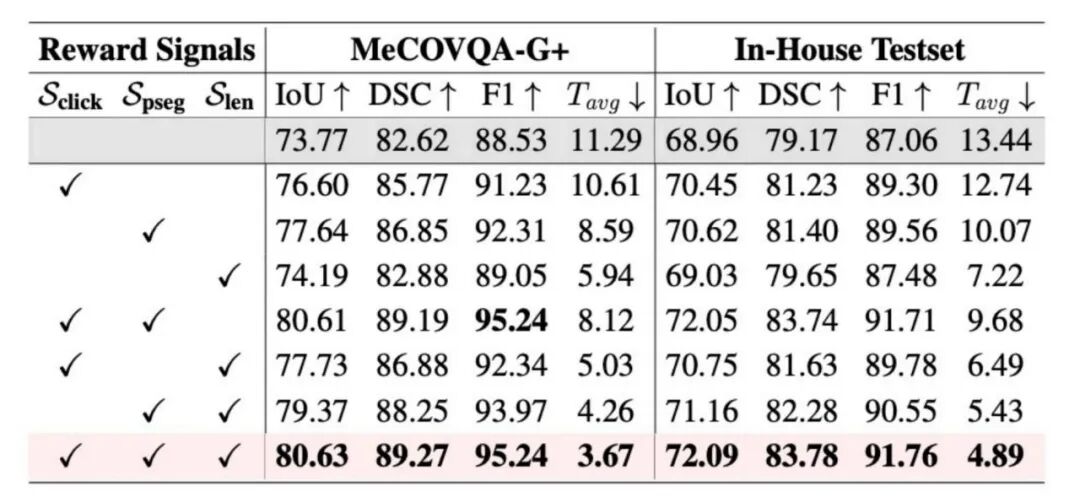
细粒度奖励设计消融实验
对于RL阶段的奖励设计,研究团队同样进行了逐项验证。以仅使用格式奖励与答案奖励为基线,在域外集
MeCOVQA-G+上的IoU仅为73.77;逐步引入区域点击奖励后, IoU提升至76.60, mask定位准确性显著改善;加入渐进式分割改进奖励后进一步跃升至80.61,同时平均交互步数从11.29步压缩至8.12步,模型学会了更高效的分割路径;最终叠加轨迹长度奖励后,交互效率继续提升,步数降至4.26步,同时分割质量维持在最高水平。这一结果表明,细粒度的逐步反馈信号是驱动模型在质量与效率之间取得最优平衡的关键,单纯依赖最终结果奖励无法达到同等效果。
论文总结
该研究将生物医学图像分割从"单次推理输出"推进到" 自主多轮交互决策"。
针对现有方法依赖隐式token导致的推理能力退化问题, IBISAgent以交错的文本推理与点击动作完全替代
token,保留了MLLM完整的语言能力,并通过多步MDP建模实现真正的自主迭代精化。进一步地,冷启动SFT结合自动轨迹生成建立稳健的推理先验, Agentic强化学习与细粒度奖励驱动模型超越模仿、探索最优决策策略,最终实现了细粒度的视觉推理。
广泛的实验验证了IBISAgent在多模态、多疾病场景下的一致性优势,为未来面向真实临床的智能医学图像分析系统奠定了重要基础。
本文系学术转载,如有侵权,请联系CVer小助手删文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号