Drift-AR:一个熵信号,同时加速AR与视觉解码两大瓶颈,实现5.5倍加速+单步生成!

Drift-AR:一个熵信号,同时加速AR与视觉解码两大瓶颈,实现5.5倍加速+单步生成!

Amusi
发布于 2026-04-15 19:14:16
发布于 2026-04-15 19:14:16

论文标题:Drift-AR: Single-Step Visual Autoregressive Generation via Anti-Symmetric Drifting
论文作者:Zhen Zou, Xiaoxiao Ma, Mingde Yao, Jie Huang, Linjiang Huang, Feng Zhao
作者机构:中国科学技术大学,香港中文大学MMLab,京东探索研究院,北京航空航天大学
论文地址:https://arxiv.org/abs/2603.28049
代码仓库:https://github.com/aSleepyTree/Drift-AR
Drift-AR:一个熵信号,同时加速AR与视觉解码两大瓶颈,实现5.5倍加速+单步生成!
MAR、TransDiff、NextStep-1等AR-Diffusion混合模型将AR的语义建模与扩散的高保真合成相结合,生成质量优异,但面临双重速度瓶颈:AR阶段逐token序列生成慢,扩散视觉解码器需要多步迭代去噪。现有加速方案各管各的——投机解码管AR,蒸馏管扩散——缺乏统一原则。
有没有一个信号能同时解决两个瓶颈?我们发现,连续空间AR模型的逐位置预测熵恰好扮演这个角色。据此,我们提出Drift-AR,实现3.8--5.5倍加速与真正的单步(1-NFE)视觉生成。
🔍 核心洞察:熵的"双重角色"
不同于语言模型中token间的信息密度相对均匀,图像生成中的信息分布具有强烈的空间非均匀性:天空、纯色墙面等冗余区域产生低熵,而纹理、物体边界等复杂结构产生高熵。
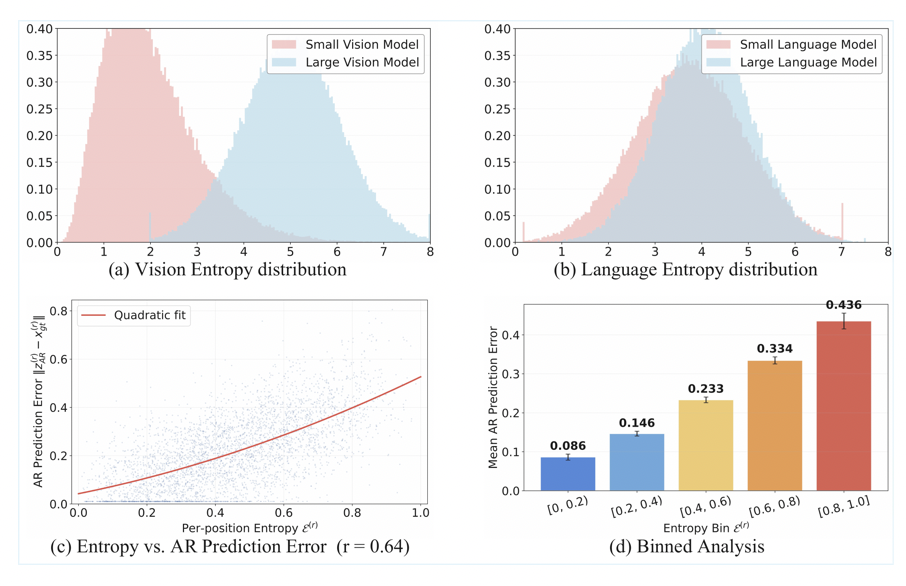
作者从两个角度揭示了熵的双重意义:
1. AR加速视角:熵失配导致投机解码失败
如上图(a)(b)所示,在视觉AR模型中,小型Draft模型的熵分布严重偏向低熵(过度自信),与大型Target模型的熵分布存在显著失配。这种失配直接导致投机解码的接受率极低。而在语言AR模型中,大小模型的熵分布高度重叠,投机解码因此在NLP中效果显著——但这一优势无法直接迁移到视觉AR模型。
2. 视觉解码加速视角:熵编码局部生成难度
如上图(c)(d)所示,逐位置AR预测误差与熵呈强正相关(Pearson r=0.64),且分箱分析显示平均误差随熵单调递增。这意味着高熵位置正是AR预测偏差最大的位置,也正是视觉解码器需要施加最强校正的位置。
这一双重角色使得熵成为连接AR加速与视觉解码加速的天然桥梁。
🛠 Drift-AR的核心设计
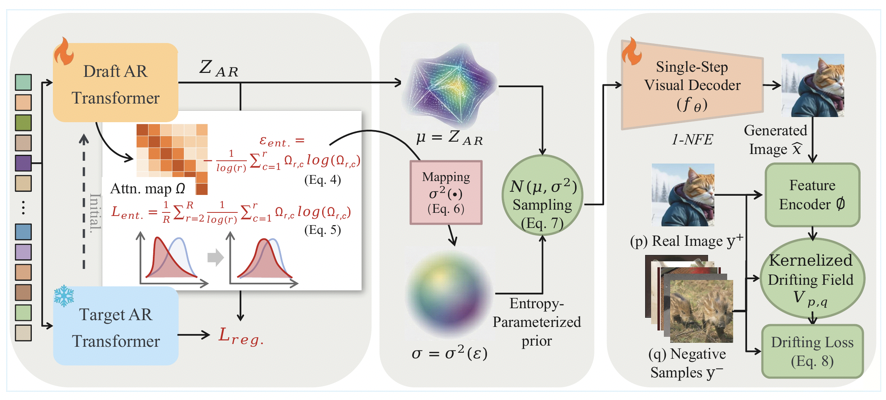
Drift-AR围绕熵信号设计了两大核心组件:
组件一:熵引导的投机解码(加速AR阶段)
直接将EAGLE等投机解码方法应用于连续空间AR模型效果不佳——Draft模型产生过度自信的低熵特征,导致大量草稿被Target模型拒绝。
Drift-AR对此做了两项关键改进:
- 连续空间回归损失:移除离散分类目标,替换为连续特征回归,适配连续空间AR模型
- 因果归一化熵损失:显式对齐Draft与Target的熵分布,解决熵失配问题。对注意力矩阵每一行的熵按归一化,确保训练与推理使用同一尺度
组件二:熵参数化的反对称漂移场(加速视觉解码阶段)
这是本文最核心的创新:将熵重新解释为反对称漂移场(Anti-Symmetric Drifting Field)初始分布的物理方差。
具体而言,在每个空间位置,以AR特征作为先验均值,以熵导出的方差决定先验分布的宽度:
- 低熵位置:方差趋近于零,先验接近确定性输入,漂移自然消失
- 高熵位置:方差增大,先验分布扩展,激活更强的漂移校正
当模型收敛至时,反对称性质保证漂移场,从而实现1-NFE(单步前向传播)生成——完全消除迭代去噪,无需蒸馏。
统一设计:退火训练 + 共享熵信号
- 退火训练:Phase I(前80%训练)联合优化AR与漂移场,从0.95线性衰减至0;Phase II冻结AR先验,仅优化漂移场,恢复平稳源分布假设
- 零额外开销:投机解码中计算的熵被直接复用为视觉解码器初始分布的方差参数,无需额外计算
📊 实验结果
Drift-AR在MAR、TransDiff、NextStep-1三大AR-Diffusion混合模型上均取得了显著效果:
ImageNet 256×256 类条件生成
方法 | 延迟/s | 加速比 | FID ↓ | IS ↑ |
|---|---|---|---|---|
MAR-L | 5.31 | 1.00× | 1.78 | 296.0 |
MAR-L + DMD | 1.99 | 2.67× | 1.81 | 295.5 |
MAR-L + LazyMAR | 2.29 | 2.32× | 1.93 | 297.4 |
MAR-L + Ours | 0.96 | 5.53× | 1.76 | 297.4 |
MAR-H | 9.97 | 1.00× | 1.55 | 303.7 |
MAR-H + DMD | 4.17 | 2.39× | 1.73 | 301.0 |
MAR-H + LazyMAR | 4.24 | 2.35× | 1.69 | 299.2 |
MAR-H + Ours | 1.93 | 5.16× | 1.53 | 304.6 |
TransDiff-L | 3.17 | 1.00× | 1.61 | 295.1 |
TransDiff-L + SD | 1.75 | 1.81× | 1.88 | 283.6 |
TransDiff-L + DMD | 1.61 | 1.97× | 1.79 | 288.3 |
TransDiff-L + Ours | 0.64 | 4.96× | 1.61 | 295.8 |
TransDiff-H | 6.72 | 1.00× | 1.55 | 297.9 |
TransDiff-H + SD | 3.52 | 1.91× | 1.68 | 291.1 |
TransDiff-H + DMD | 3.48 | 1.93× | 1.71 | 289.9 |
TransDiff-H + Ours | 1.33 | 5.06× | 1.57 | 298.1 |
在所有模型规模上,Drift-AR均实现最高加速比(4.96--5.53×),同时FID和IS指标不降反升。相比之下,DMD和LazyMAR仅能达到约2.4倍加速且伴随质量下降,vanilla投机解码更是出现严重质量崩塌(TransDiff-L IS从295.1降至283.6)。
文生图(NextStep-1)
方法 | 加速比 | GenEval ↑ | FID ↓ | CLIP ↑ |
|---|---|---|---|---|
NextStep-1 | 1.00× | 0.63 | 6.71 | 28.67 |
NextStep-1 + SD | 2.03× | 0.63 | 6.90 | 27.96 |
NextStep-1 + DMD | 1.66× | 0.59 | 8.33 | 25.19 |
NextStep-1 + Ours | 3.81× | 0.66 | 6.66 | 29.02 |
在文生图任务上,Drift-AR实现3.81倍加速,且GenEval、FID、CLIP三项指标均超越原模型。DMD出现严重质量崩塌(FID 8.33, CLIP 25.19),投机解码虽保持语义一致性但质量下降。
视觉效果对比

定性对比显示,Drift-AR在大幅降低延迟的同时,保留了精细纹理和语义一致性。
🔬 单步解码的验证:Decoder Step Analysis
一个自然的问题是:漂移解码器真的只需要一步前向传播吗?
解码器 | 步数 | 延迟/s | FID ↓ | IS ↑ |
|---|---|---|---|---|
Diffusion | 20 (默认) | 6.72 | 1.55 | 297.9 |
Diffusion | 4 | 1.65 | 3.89 | 261.5 |
Diffusion | 1 | 1.28 | 14.72 | 148.3 |
DMD | 1 | 1.30 | 2.93 | 273.2 |
Drifting (Ours) | 1 | 1.33 | 1.57 | 298.1 |
原始扩散解码器在1步时质量完全崩塌(FID 14.72);DMD在1步时仍有明显退化(FID 2.93);而Drift-AR在仅1步时即达到FID 1.57——与20步扩散基线持平,充分验证了反对称漂移场将生成能力集中到单次前向传播的能力。
📊 消融实验
在TransDiff-H上对五个核心组件进行消融:
方法 | FID ↓ | IS ↑ |
|---|---|---|
Ours w/o 熵参数化 (A) | 1.72 | 289.3 |
Ours w/o 退火调度 (B) | 1.69 | 292.6 |
Ours w/o 反对称核 (C) | 1.69 | 291.8 |
Ours w/o 早停机制 (D) | 1.62 | 295.5 |
Ours w/o 先验冻结 (E) | 1.67 | 291.9 |
Ours (完整) | 1.57 | 298.1 |
移除熵参数化(A)导致最大性能下降(FID从1.57升至1.72, IS从298.1降至289.3),直接验证了熵作为漂移先验方差是整个框架的核心设计。移除任何其他组件同样导致退化,证明五个组件缺一不可。
💡 TL;DR
一个熵,两个用途:既对齐Draft-Target熵分布让投机解码跑起来,又充当漂移场的物理方差让视觉解码一步到位——计算一次,加速两处,3.8--5.5倍提速,质量不降反升。
- 熵 = 统一加速信号:同一个熵同时驱动AR投机解码 + 视觉解码先验
- 1步生成,不蒸馏:反对称漂移场实现1-NFE,FID 1.57 vs. 20步扩散的1.55
- 5.5×加速,质量不降反升:MAR / TransDiff / NextStep-1全面验证
代码已开源,欢迎star与讨论交流~
本文系学术转载,如有侵权,请联系CVer小助手删文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号