当生物 AI 智能体走进实验室,我们该如何相信它?

当生物 AI 智能体走进实验室,我们该如何相信它?

DrugIntel
发布于 2026-05-20 12:49:11
发布于 2026-05-20 12:49:11
来源:Evaluating AI Agents in Biology | Phylo · Biomni Lab 发布日期:2026年2月11日 | 原文阅读时长:约14分钟 作者团队:Phylo 研究团队(已获 a16z & Menlo Ventures 联合领投种子轮)
导读
如果你关注 AI 在生命科学领域的应用,这篇来自 Phylo 团队的博客是近期值得精读的方法论文章之一。
它不是在炫技——而是在诚实地追问一个更难的问题:我们凭什么相信生物 AI 智能体的分析结果? 现有的评测基准到底可不可靠?我们应该如何衡量一个 AI 是否真的理解生物学?
文章从一个令人警醒的场景出发,系统拆解了生物 AI 评测的三大核心挑战,分享了对 BixBench 基准的深度分析与修订实践,并提出了一套全新的"过程追踪"评测框架 BiomniBench。篇幅不长,信息密度很高。
一、问题的核心:生物 AI 的失败是沉默的
文章开篇以一个典型场景切入:
一个 AI 智能体分析了一份差异表达数据集,交出了漂亮的火山图、整洁的基因排名和言之凿凿的解读——一切看起来都对。但在分析轨迹的深处,它使用了错误的归一化方法,忽略了批次效应,还引用了一篇根本不存在的论文。
这个例子揭示了生物 AI 最危险的特征:失败是沉默的。
- • 软件出错 → 程序崩溃,立即可见
- • 数学证明出错 → 逻辑断裂,可以验证
- • 生物分析出错 → 结果照样往前跑,影响湿实验室方案、药物研发决策,可能在研究流水线里传播数月才被发现
代价是真实的:浪费的试剂、失败的临床试验、建立在错误基础上的科学结论。
这正是为什么,评估 AI 智能体的能力,在生物学领域比任何其他领域都更加紧迫、更加复杂。
二、为什么评估生物 AI 格外困难?四大结构性挑战
作者归纳了生物学区别于其他领域的四个核心难点:
1. 领域极度碎片化
生物学不是一个统一的领域,它横跨分子生物学、基因组学、结构生物学、生态学、临床研究等数十个子领域,每个子领域都有自己的方法论、术语体系和判断标准。任务类型同样千变万化:文献综述、显微图像解读、基因组数据分析、实验方案撰写……构建覆盖全面的评测基准,本身就是一个巨大的工程。
2. 真实工作是多步骤链路,而非单点任务
一个生物学家的典型工作流:文献检索 → 实验设计 → 数据处理 → 分析解读 → 结论撰写。现有大多数评测只测试某一个节点的能力,但真实场景要求整条链路都正确——任何一环出错,最终结论都可能失效。
3. 没有唯一正确答案
生物学问题往往有多种合理的实验设计方案和分析路径。期望一个固定"标准答案"的评测框架,从根本上无法捕捉科学推理的真实复杂性。这对基准构建是一个深层的认识论挑战。
4. 验证代价极高且需要专业判断
许多任务的真正验证需要实际运行实验,周期以天至月计算。即便是评估每个分析步骤是否正确,也需要深厚的领域专业知识:
- • 数据分布选错了统计检验方法
- • 使用了不合适的参考基因组
- • 对照组设置存在混淆变量
这些错误,连初级科学家都可能犯,让 AI 自动评分难上加难。
三、现有评测基准的现状与局限
过去两年,生物 AI 评测领域出现了一批有价值的尝试:
阶段 | 代表性基准 | 评测重点 |
|---|---|---|
早期 | HLE、LAB-Bench | 生物知识、文献理解、序列操作、协议推理等 LLM 能力 |
近期 | Biomni-Eval1、BixBench 等 | 开放式多步骤分析、构建 pipeline、基于真实数据的决策 |
这些基准反映了社区的真实努力,也显著推进了我们对 LLM 在生物学中能力边界的认识。但若要真正评估 AI 是否能推动科学发现,仍需要弥合现有评测任务与实践生物学家日常工作之间的差距。
四、深度实践:重新审视 BixBench
Phylo 的评测实验
为评估自家平台 Biomni Lab 的分析能力,Phylo 团队首先系统测试了 BixBench——目前公认为最贴近真实场景的生物信息学基准之一。该基准要求智能体分析真实生物数据集并回答研究问题,已被多个团队采用,是自然的起点。
在原始 BixBench 上,各主要智能体成绩如下:
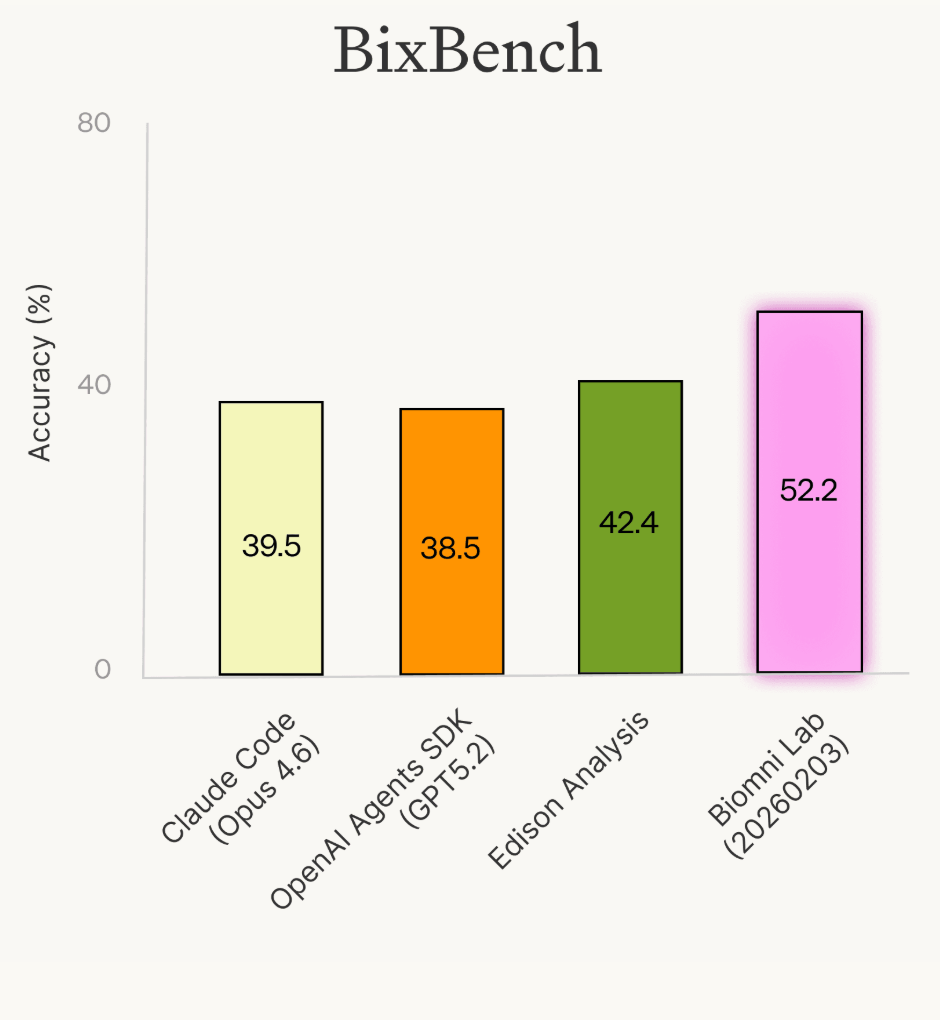
智能体 | 准确率 |
|---|---|
Biomni Lab | 52.2% |
Edison Analysis | 42.4% |
Claude Code (Opus 4.6) | 39.5% |
OpenAI Agents SDK (GPT-5.2) | 38.5% |
相较于原论文的约 21%,这些成绩代表了明显进步。但"即便最好的智能体也有近半题目答错"——这个表面数字,让人觉得这些系统离实际可用还差得很远。
然而,这与 Phylo 团队从用户那里听到的真实反馈完全不符。用户普遍认为这些工具在日常研究中确实有用。这个矛盾促使他们深入追查:失败究竟失败在哪里?
关键发现:失败可以分为三类
深入分析后,团队将失败样本归纳为三种不同性质的问题:
① 真正的 AI 能力缺陷(应该改进)
智能体缺乏深层生物学理解,导致分析错误。例如:
- • 在通路富集分析中混淆了上调/下调基因的方向性
- • 错误理解了基因必需性评分的含义与方向
这类失败是真实的,反映了 AI 当前的知识边界,需要改进。
② 题目歧义或信息不足(基准设计问题)
题目或背景信息不够充分,即便是人类专家也难以确定唯一答案。例如:
- • 没有说明"良性"分类是否包含"疑似良性"
- • 没有指定通路富集应用 GSEA 还是 ORA
- • 没有明确期望的输出格式
③ 参考答案本身有误(基准质量问题)
部分"标准答案"本身就是错的。例如:
- • 参考分析对已归一化的数据重复运行了 DESeq2
- • 根据未声明的标准移除了某些样本
- • 使用了与题目描述不一致的文件
这是最发人深省的发现:在我们评判 AI 是否够好之前,必须先评判评测本身是否够好。 只有第①类才真正反映 AI 的问题。后两类是评测的失败,不是智能体的失败。
BixBench-Verified-50:修订实践与开源
为了将 AI 的真实能力与基准噪声分离,Phylo 团队策划了 BixBench-Verified-50:
操作流程:
- 1. 从完整基准中抽样,逐题识别问题
- 2. 对无法修复的题目直接剔除
- 3. 对可修复的题目:修订题目表述或修正参考答案(同时保留合理的模糊性,不过度指定)
- 4. 联合多位领域专家进行交叉验证,确保:参考答案正确性 / 上下文信息充分性 / 期望答案表述清晰
结果已开源在 Hugging Face,附有详细的修订记录文档,说明每道题的原始问题与修改原因。
在修订后的子集上重跑相同智能体,成绩大幅提升:
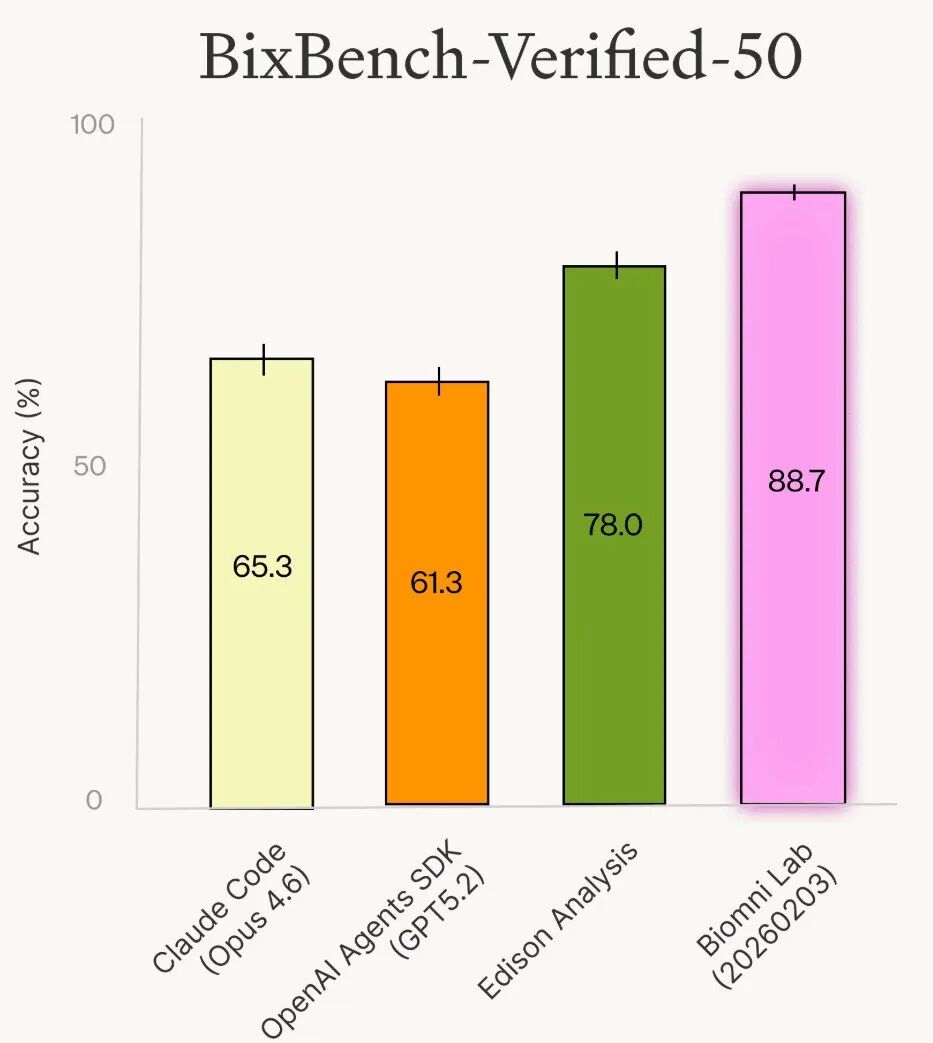
智能体 | 原始 BixBench | BixBench-Verified-50 | 提升幅度 |
|---|---|---|---|
Biomni Lab | 52.2% | 88.7% | +36.5pp |
Edison Analysis | 42.4% | 78.0% | +35.6pp |
Claude Code (Opus 4.6) | 39.5% | 65.3% | +25.8pp |
OpenAI Agents SDK (GPT-5.2) | 38.5% | 61.3% | +22.8pp |
所有智能体的准确率都大幅提升,一致地证明了原始基准中相当比例的"失败"来自基准本身的质量问题,而非智能体的真实能力边界。
五、评估范式的深层转变:从"答案"到"过程"
BixBench 的实践还暴露了一个更根本的问题:二元评分对生物 AI 来说是一把残缺的尺子。
二元评分的根本局限
考虑一个场景:
- • 智能体 A:正确加载了数据,合理过滤,选用了不同但同样合理的统计方法,因此得出了与"标准答案"不同的数值
- • 智能体 B:每一步都错,从数据加载就失败
在二元评分下,两者都得 0 分。这个分数什么都没告诉我们。
对于短答案事实题,这种评分方式尚可。对于定义真实生物研究的长链路分析任务,二元评分丢弃了几乎所有有价值的诊断信号。
过程追踪评估的必要性
文章提出了一个核心类比——科学评审本身就是过程导向的:
同行评审不只看结论是否正确,因为直接实验验证既慢又贵。它审视的是方法选择、分析逻辑、对照设置。导师看学生的图,会问"为什么用这个归一化方法?""去掉那个离群点会怎样?" 过程,是建立信任的地方。
这正是为什么生物 AI 评测需要一种根本性的范式转移:从"答对了吗"到"做对了吗"。
维度 | 结果导向评估 | 过程追踪评估 |
|---|---|---|
评估对象 | 最终输出是否与标准答案一致 | 每一步分析决策的质量 |
优势 | 易于规模化,指标清晰 | 诊断价值高,与科学实践对齐 |
局限 | 无法区分"歪打正着"与"真正正确" | 构建难度大,需要领域专家参与 |
对多元解的处理 | 困难(只有一个标准答案) | 自然(可以定义合理的方法空间) |
当前生物 AI 评测中的比例 | 占主流 | 几乎缺失 |
六、BiomniBench:生物 AI 的第一个"过程追踪"评测框架
正是为了填补这一空白,Phylo 提出了 BiomniBench——一个以分析轨迹为核心的生物 AI 评测框架。
设计哲学
BiomniBench 的设计遵循四个核心原则:
- • 评估过程,而非只看输出:对智能体每一步的分析决策打分
- • 扎根真实任务:任务来源于高影响力已发表论文的真实长链路分析
- • 覆盖生物学广度:跨越不同生物医学领域与数据模态
- • 与科学实践对齐:评分标准与领域专家(包括论文第一作者)共同制定
评分维度详解:BiomniBench-DataAnalysis
首个模块聚焦数据分析与解读,按五个维度打分:
维度 | 核心问题 | 具体示例 |
|---|---|---|
数据处理 | 有没有加载正确文件、用正确 ID 合并、处理好测量尺度的一致性? | 加载所有必要文件、合并时使用正确标识符、过滤到正确的处理臂和时间点、确保每个患者一行 |
方法选择 | 选用的分析方法是否适合当前任务? | 生存分析 → Kaplan-Meier + log-rank;比较免疫细胞群 → Wilcoxon(非参数),而非不恰当的参数检验 |
统计严谨性 | 统计检验、阈值、多重校正是否被正确应用? | 正确应用 p < 0.05 阈值;报告精确 p 值;在适当时应用 BH-FDR 校正;只基于统计显著结果延伸解读 |
来源可靠性 | 引用的是否是可靠的、有同行评审背书的信息源? | 来自同行评审文献、权威数据库的相关引用,而非幻觉出来的参考资料 |
推理链条 | 整体分析逻辑是否连贯?解读是否连接到生物学机制? | 正确框架化问题(如区分"生存相关"vs"预测性"生物标志物);避免因果过度声明;连接到生物学机制(如 CD40 驱动的抗原呈递);承认研究局限性 |
任务来源与覆盖范围
任务由领域专家(包括原始论文第一作者和对应领域的行业专家)共同策划,覆盖:
生物医学领域:肿瘤学、神经退行性疾病、心血管疾病等
数据模态:转录组学、基因组学、临床数据等
七、初步成绩:AI 已能与资深科学家比肩
在 15 个任务的初步子集(Biomni-DA-v0)上,各智能体综合过程评分如下(满分100):
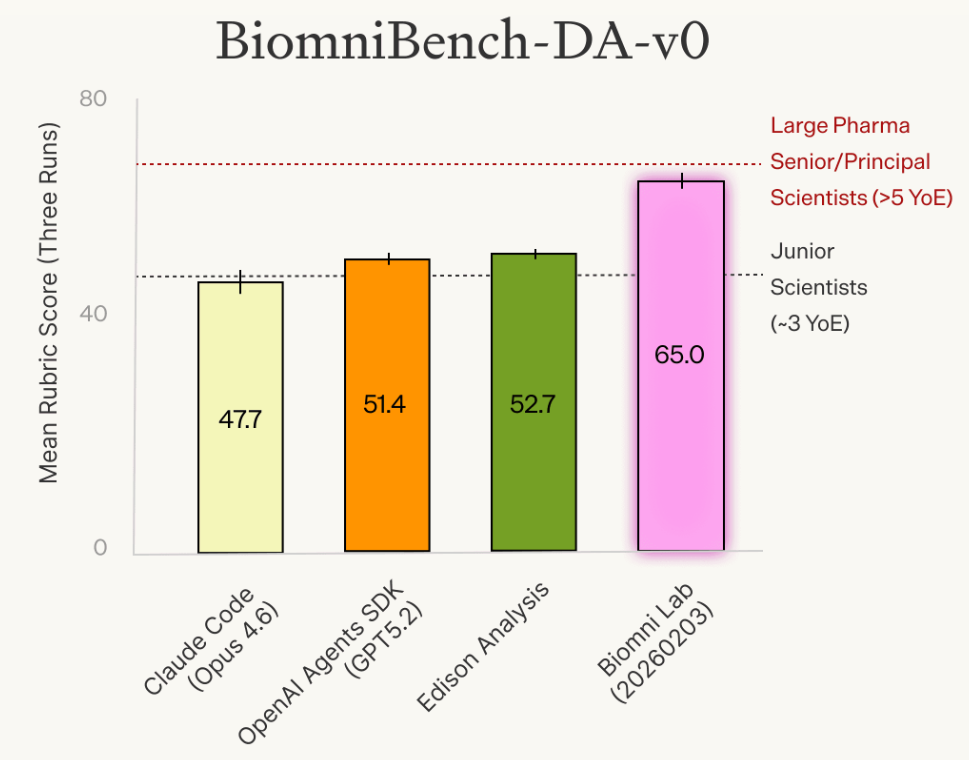
参与者 | 类型 | 得分 |
|---|---|---|
资深科学家(大型药企,5年以上) | 人类基准 | 68.5 |
Biomni Lab | AI 智能体 | 65.0 |
Edison Analysis | AI 智能体 | 52.7 |
OpenAI Agents SDK (GPT-5.2) | AI 智能体 | 51.4 |
初级科学家(约3年经验) | 人类基准 | 48.5 |
Claude Code (Opus 4.6) | AI 智能体 | 47.8 |
几个值得注意的关键发现:
- • Biomni Lab 的得分(65.0)与资深科学家基准(68.5)处于同一数量级,而远高于初级科学家组(48.5)
- • 这里的"资深科学家"是大型药企有5年以上经验的科研人员,代表了行业中的高水平实践者
- • 这是过程评分,而非结果评分——意味着 Biomni Lab 在分析方法的合理性、统计严谨性、推理逻辑等维度,整体达到了接近资深专家的水平
- • 这些结果是15个任务上的初步数据,团队明确指出会随基准扩展而演变
八、开放性与社区建设愿景
Phylo 团队将 BiomniBench 定位为一个开放的社区共建项目,原因是:
追踪式评估中最难的部分,是选题和制定评分标准(rubric)——而生物学每个子领域都有其独特的判断标准,只有实践者才真正理解。这不是一个机构能独立完成的工作。
他们正在招募希望共同参与的:
- • 生物学家(贡献任务、验证评分标准)
- • 研究机构
- • 制药公司
- • AI 智能体开发团队(在追踪式指标上测试自己的系统)
联系方式:contact@phylobio.com
BixBench-Verified-50 已开源至 Hugging Face,附有完整的逐题修订记录文档。
总结
这篇文章的价值不只在于 Biomni Lab 的评测成绩,而在于它提出了一套系统性的反思框架,值得整个生物 AI 领域认真对待。
三个核心贡献:
1. 对现有评测基准的诚实解剖 通过 BixBench 实践,量化地展示了评测噪声的规模——清理后各智能体准确率提升了22到36个百分点。这说明当前社区对生物 AI 能力的评估,可能系统性地被低估了。
2. 对评估范式的深层反思 从"答案正确性"到"过程合理性",不只是方法上的改进,更是对"AI 智能体的可信度应该如何建立"这一根本问题的重新定义。这个框架与科学界的同行评审实践天然对齐。
3. 对领域生态的建设性贡献 开源 BixBench-Verified-50、提出 BiomniBench 框架、招募社区共建——这种做法比单纯发布一个"我的模型最好"的报告有价值得多。
局限性说明: BiomniBench-DataAnalysis 目前仍是初步结果(15个任务),Phylo 自己也明确指出这些数字会随基准扩展而变化。同时,作为 Biomni Lab 的开发方,他们在评测设计上存在潜在的利益相关性,独立验证将更具说服力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号