新突破!上海交大等提出Evo-Depth:为VLA补上轻量隐式深度一环

新突破!上海交大等提出Evo-Depth:为VLA补上轻量隐式深度一环

Amusi
发布于 2026-05-20 14:52:48
发布于 2026-05-20 14:52:48
一句话推荐: 上海交大等单位提出的 Evo-Depth,用约 0.9B 参数,在仿真与真机上同时兼顾性能与部署效率,为资源受限场景下的 VLA 提供了一条轻量化空间增强路线。
《Evo-Depth: A Lightweight Depth-Enhanced Vision-Language-Action Model》
代码:github.com/MINT-SJTU/Evo-Depth
论文:https://arxiv.org/abs/2605.14950
导语:VLA 很热,但「空间」仍是短板
Vision-Language-Action(VLA)把视觉、语言与动作串在一起,被视作可扩展机器人学习的重要方向。现实任务里,精定位、细摆放、遮挡与前后关系往往决定成败——而大量 VLA 仍主要依赖二维视觉,空间 grounding 不足时,成功率会出现明显下滑。
怎么补空间?
显式 3D(深度、点云)能补几何,却常带来额外传感与重建链路,并对噪声与标定误差敏感;隐式 3D 从 RGB 学能省硬件,但不少路线依赖较重的基础模型,训练与推理成本偏高。
Evo-Depth 瞄准的正是中间地带:不显式增加硬件负担,同时尽量保留实时部署能力,并把「深度感」以紧凑方式写进策略里。
三个值得关注的点
- 问题切得比较准: 针对 VLA 在精细操作场景中的空间瓶颈,给出一条相对清晰的模块化路径(隐式深度编码 → 空间增强 → 动作学习对齐),而不是单纯依赖更大的模型规模。
- 不仅关注 benchmark: 除了 Meta-World、VLA-Arena、LIBERO 等基准结果外,论文还同步报告了显存占用与推理频率,方便和真实部署场景进行对照。
- 开源链路完整:
官方仓库
MINT-SJTU/Evo-Depth与工程实现相互对应,配套训练与评测脚本,降低了从阅读论文到实际复现的门槛。
方法速览:轻量 、可端到端训练
Evo-Depth(Evo-Depth: A Lightweight Depth-Enhanced Vision-Language-Action Model)的核心思路是:
从多视角 RGB 提取紧凑的隐式深度表征,再以轻量方式融入视觉–语言通路,最后通过 flow-matching 动作专家输出连续动作。
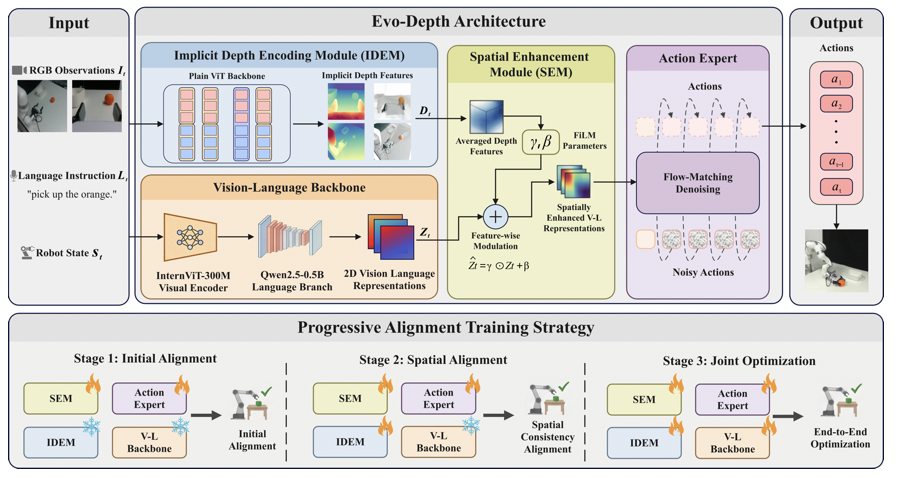
Evo-Depth 模型结构图
Evo-Depth 模型结构图:多视角 RGB、语言指令和机器人状态作为输入,经深度增强的视觉语言动作框架后生成连续动作。
整个系统主要由三部分组成:
IDEM:Implicit Depth Encoding Module
IDEM 负责从多视角图像中提取隐式深度特征,强调空间布局与相对几何关系,而不是显式生成高成本的 3D 中间表示。
论文中,IDEM 骨干约 0.13B 参数,并结合多视角深度预训练初始化,在轻量条件下引入与深度相关的归纳偏置。
SEM:Spatial Enhancement Module
SEM 将隐式深度作为一种调制信号,用于增强视觉–语言表征。
相比直接增加独立深度分支,这种融合方式更克制:
- 原有 VLM 继续负责语义理解
- 深度特征主要负责空间增强
- 同时尽量控制延迟与显存开销
Progressive Alignment Training
多模块联合训练通常容易出现优化不稳定的问题。
为此,作者采用 Progressive Alignment Training,通过分阶段训练方式逐步完成:
- 深度表征对齐
- 多模态融合
- 动作学习
动作头则采用了当前 VLA 中较常见的 flow-matching 路线。
实验结果
在约 0.9B 总参数设置下,论文报告的结果包括(完整对比见原文):
维度 | 论文报告结果 |
|---|---|
仿真 | Meta-World **84.4%**、VLA-Arena **41.1%**、LIBERO **95.4%**、LIBERO-Plus 69.6% |
真机 | 平均成功率约 90% |
部署侧 | 约 3.2 GB GPU 显存、约 12.3 Hz 推理频率 |
相比只关注 benchmark 分数,论文也给出了部署侧开销与实时性指标。
对于需要真正运行在机器人控制回路中的 VLA 来说,这部分信息往往同样重要。
从论文到代码:已全面开源
- 官方仓库: https://github.com/MINT-SJTU/Evo-Depth
- 支持评测: LIBERO、LIBERO-Plus、Meta-World MT50、VLA-Arena 等常见具身智能基准。
- 训练流程: 支持 LeRobot v2.1 风格数据组织与三阶段微调流程。
- 模型权重: https://huggingface.co/MINT-SJTU/EVO-Depth-LIBERO
结语
Evo-Depth 想解决的问题其实很直接:
在不显著增加系统负担的情况下,提升 VLA 的空间能力。
相比纯二维 VLA,它补充了空间信息;相比更重的 3D 路线,它又尽量保留了部署效率。
对于正在做机器人操作、空间智能或 VLA 系统的团队来说,这类“性能—成本—实时性”之间的折中方案,可能会越来越重要。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号