Skill 仓库本周炸榜,但 90% 工程师没分清这三个体系的本质区别

Skill 仓库本周炸榜,但 90% 工程师没分清这三个体系的本质区别

码哥字节
发布于 2026-05-22 18:47:02
发布于 2026-05-22 18:47:02
你好,我是《Redis 高手心法》作者码哥。
打开今天的 GitHub Trending,我盯着看了五分钟没动。
榜单前列三个仓库——mattpocock/skills、obra/superpowers、anthropics/skills——本周合计新增 33,968 stars。这是个什么量级?相当于一个 5 年老项目一年的星星增长,在七天内集中砸到了 Claude Code Skill 这一个赛道上。
但更让我意外的是身边几个工程师朋友的反应。问他们「这三个仓库装哪个?」,答案高度一致:「都装上呗」。
这恰恰说明大部分人没搞清楚一件事——这三个仓库根本不是同类竞品,它们代表着三种完全不同的工程哲学:一个是 library(工具集合),一个是 framework(方法论框架),一个是 reference implementation(官方参考实现)。你把它们当同类装在一起,大概率会冲突 + 互相覆盖 + 让 Claude Code 行为变得不可预测。
我做了 10 年后端架构,见过太多团队把「Spring」「Spring Boot」「Spring Cloud」当同一个东西装,结果踩到各种依赖冲突的坑。今天 Skill 生态正在重演这个故事,而且节奏快 10 倍。这篇文章把三大体系的设计哲学差异拆清楚,给你一个真正能用的选型矩阵。
先看实时数据:这周到底发生了什么
我用三个仓库的 GitHub 主页实测了一遍数据(2026-05-21):
仓库 | 当前 stars | 本周新增 | 作者 | License |
|---|---|---|---|---|
mattpocock/skills | 97.5k | +18,368 | Matt Pocock | MIT |
obra/superpowers | 201k | +10,851 | Jesse Vincent | MIT |
anthropics/skills | 138k | +4,749 | Anthropic 官方 | Apache 2.0 + source-available |
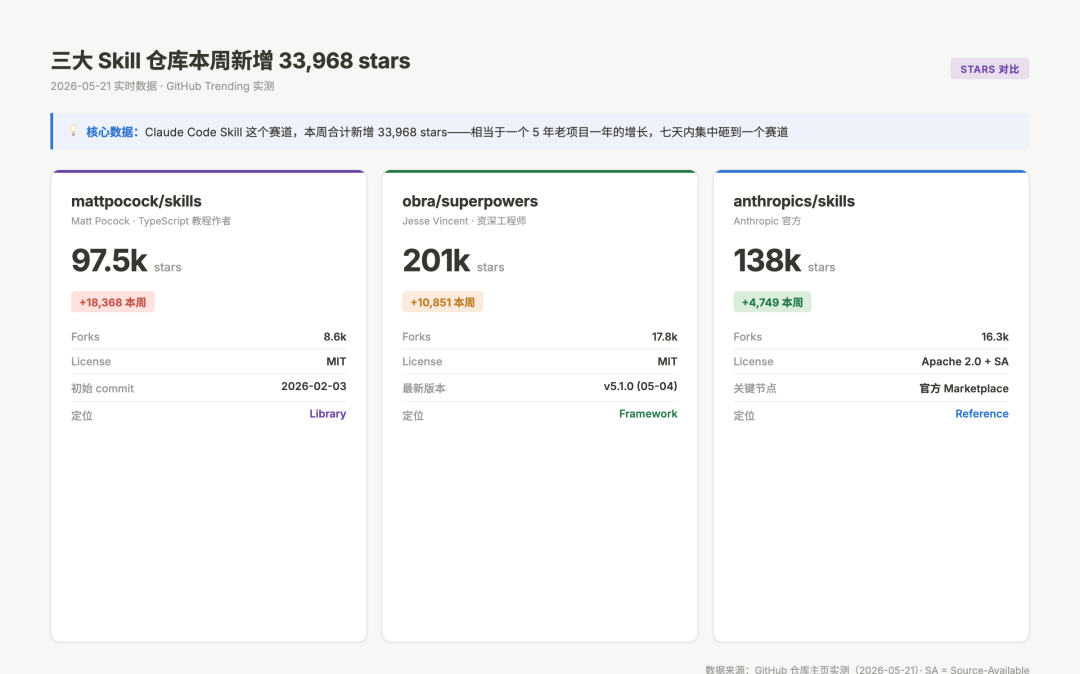
三大 Skill 仓库本周新增 33,968 stars 实时数据对比
图:mattpocock/skills、obra/superpowers、anthropics/skills 三个 Skill 仓库本周 stars 增长 + 累计 stars + 定位对比(2026-05-21 实测)
三个数字背后有不同的故事:
mattpocock/skills 的增长曲线最陡——这个仓库初始 commit 是 2026-02-03,三个半月就到了 97.5k stars。Matt Pocock 是 TypeScript 教程界的网红,自己有 6 万订阅的 newsletter,他把自己 .claude 目录里的 skill 整理开源,社区接住得很快。
obra/superpowers 是其中最老牌的一个,已经迭代到 v5.1.0(2026-05-04 发布),201k 这个体量在 AI 工具类项目里是顶级。它的关键里程碑是 2026-01-15 被 Anthropic 官方 Plugin Marketplace 接收——一个第三方框架被官方接管推广,这在 Claude Code 生态里是头一次。
anthropics/skills 是 Anthropic 自己的官方公共库,定位最特殊——它既是教育示范(README 明确写「demonstration and educational purposes only」),又包含驱动 Claude.ai 文档生成功能的生产级实现(pdf、docx、xlsx、pptx 四个 skill)。
但 stars 数字解决不了一个核心问题:这三个仓库的工程哲学完全不同,混着装等于在你的 .claude 目录里塞三种不兼容的框架。
三种体系,三种工程哲学
这是本文的核心判断,先把它放出来:
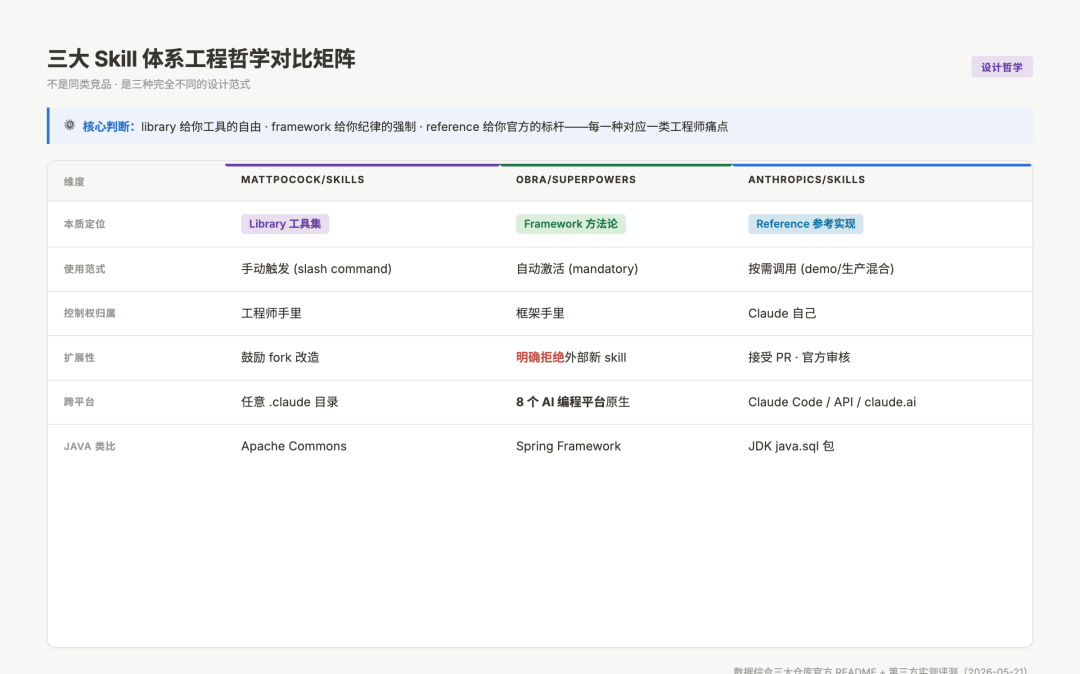
三大 Skill 体系工程哲学对比矩阵:library 框架 framework 参考实现 reference 的差异
图:从本质定位、使用范式、控制权、扩展性、跨平台、Java 类比六个维度对比三大体系
维度 | mattpocock/skills | obra/superpowers | anthropics/skills |
|---|---|---|---|
本质定位 | Library(工具集合) | Framework(方法论框架) | Reference(官方参考实现) |
使用范式 | 手动触发(slash command) | 自动激活(mandatory workflow) | 按需调用(demo/生产混合) |
控制权归属 | 工程师手里 | 框架手里 | Claude 自己 |
扩展性 | 鼓励 fork 改造 | 明确拒绝外部新增 skill | 接受 PR,官方审核 |
跨平台 | 任意 .claude 目录 | 8 个 AI 编程平台原生支持 | Claude Code / API / claude.ai |
这种差异不是「风格不同」,是底层架构哲学的不同。我用 10 年做后端的经验给你一个最直观的类比——
如果把 AI Agent 编程比作 Java Web 开发,mattpocock/skills 就是 Apache Commons(工具类库,你想用哪个调哪个),obra/superpowers 是 Spring Framework(强约束的方法论,按它的规则走),anthropics/skills 是 JDK 自带的 java.sql 包(官方实现 + 参考标准 + 部分功能直接构成生产能力)。
这三者你混着用,技术上是可以的——但前提是你清楚每一个的边界在哪里。
mattpocock/skills:一个 TypeScript 教程作者怎么设计 Skill 库
Matt Pocock 在 README 里写「Skills for Real Engineers」,这个口号背后其实是一份反 vibe-coding 宣言——他不相信「让 AI 自己搞定一切」,他认为 AI Agent 在编程里有 4 个固定失败模式,每个模式都需要一个对应的 skill 来对抗。
这 4 个失败模式我看完之后愣了很久——它们本质上是分布式系统的 CAP 推论,只是把 AI 当成一个不稳定的分布式节点:
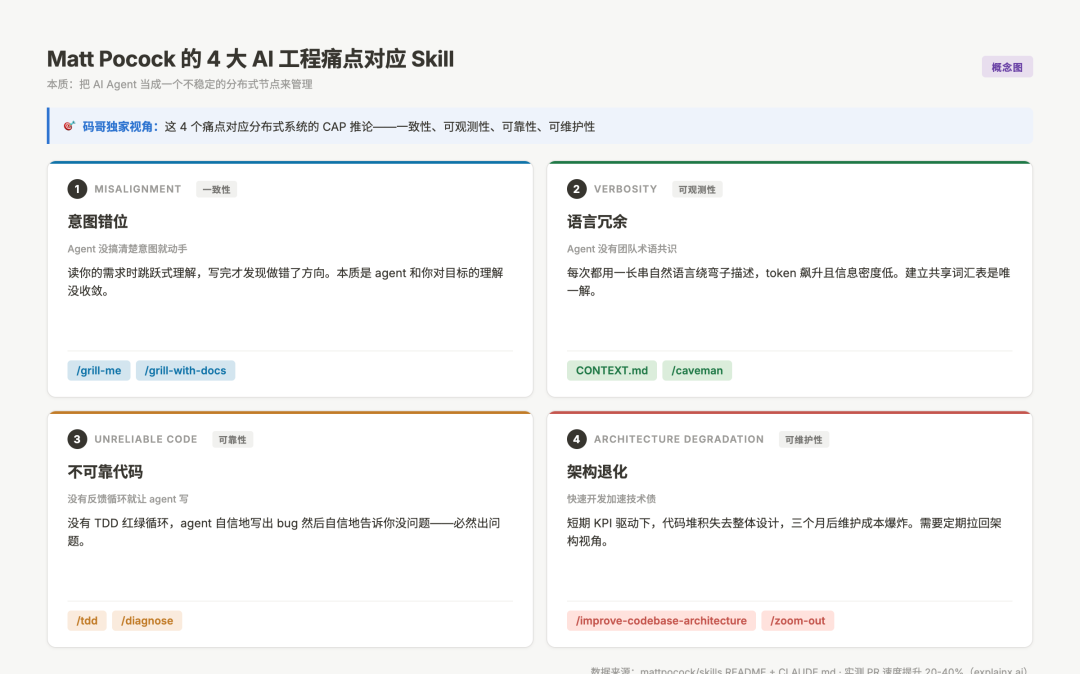
Matt Pocock 4 大 AI 工程痛点对应 Skill 拆解:意图错位 语言冗余 不可靠代码 架构退化
图:mattpocock/skills 的 4 大失败模式对应分布式系统的一致性/可观测性/可靠性/可维护性
1. Misalignment(意图错位)——agent 在没搞清楚意图前就开始动手。Matt 的方案是 /grill-me 和 /grill-with-docs,强制 Claude 在写代码前用苏格拉底式提问把需求问透。这就是分布式系统里的「一致性」问题——你和 agent 对同一个目标的理解必须先收敛。
2. Verbosity(语言冗余)——agent 不知道你团队的领域术语,每次都用一长串自然语言绕弯子描述。Matt 的方案是用 CONTEXT.md 文件建立共享词汇表。这就是「可观测性」——agent 输出可被人类快速理解的简洁信号。
3. Unreliable Code(不可靠代码)——没有反馈循环就让 agent 写代码 = 必然出问题。Matt 的方案是 /tdd 强制 red-green-refactor,/diagnose 提供结构化调试流程。这就是分布式系统的「可靠性」——每一次变更必须有可验证的反馈。
4. Architecture Degradation(架构退化)——快速开发加速技术债。Matt 的方案是 /improve-codebase-architecture、/zoom-out、/to-prd——定期把 agent 拉回到架构层面审视。这就是「可维护性」——长期演化的代码库必须有架构纪律。
这套思维不是「prompt 工程师」能想到的,是做过生产系统的人才会这样建模——把 AI agent 当成一个不靠谱的微服务节点来管理。
关于实战效果,第三方评测(explainx.ai 实测)给出的数字是「时间到正确 PR 的速度降低 20-40%」。其中最受欢迎的是 /grill-me(避免需求歧义),最反直觉的是 /caveman——它强制 agent 用「穴居人短句」回答(去掉所有客套和解释),实测**输出 token 削减 62%**。
适合谁用?看一下决策标准:
- 你对 Claude Code 的工作流有自己的偏好,不想被一个框架完全接管 → 选 mattpocock
- 你的团队主要写 TypeScript / Node.js → mattpocock 的多个 skill 是为 JS 生态优化的
- 你愿意手动
/grill-me、/tdd来触发 skill → mattpocock 的「手动触发」模型适合你
不适合谁?团队工程纪律差、希望框架强制规范的——mattpocock 给你工具,但不强制你用。
obra/superpowers:一套强制纪律的方法论框架
如果说 mattpocock 是「给你工具」,那 obra/superpowers 就是「强制你按它的规则走」。
Jesse Vincent(obra)在 README 里有一句让我反复琢磨的话:「what AI coding agents are missing is not capability but discipline」——AI 编程 agent 缺的不是能力,是纪律。
这句话决定了 superpowers 跟其他 Skill 仓库的本质差异——它不是一组可选的工具,是一套不可绕过的强制工作流。
具体表现是「七阶段流水线」:

obra superpowers 七阶段强制工作流:Brainstorm Spec Plan TDD Subagent Review Finalize
图:superpowers v5.1.0 的七阶段强制流水线 + 三条 Iron Law(测试优先 / 证据非声称 / 拒绝外部贡献)
Brainstorm(头脑风暴)
↓
Spec(编写规格说明)
↓
Plan(拆解可执行任务)
↓
TDD(红绿重构强制循环)
↓
Subagent Dev(子 agent 实现)
↓
Review(两阶段审查:规格合规 + 代码质量)
↓
Finalize(交付前最终验证)
每个阶段都对应一个 skill,关键是这些 skill 不是「你想用才用」——它们在 session 启动时通过 hook 注入,agent 在做任何事之前必须先检查相关 skill 是否应该触发。
最极端的体现是 test-driven-development 这个 skill 的 Iron Law:如果 agent 在写测试之前就开始写实现代码,superpowers 会强制删除这段代码,要求从测试重新开始。这种「执行层面的强制力」是普通 Skill 库做不到的。
obra/superpowers 还有几个让我觉得它「不是普通 skill 库」的工程细节:
第一,明确拒绝外部贡献新 skill。 仓库贡献指南里直接写:「we don't generally accept contributions of new skills」。这跟 mattpocock 鼓励 fork 改造完全相反——superpowers 把自己定位成方法论而不是工具集,方法论一旦稀释就变味了。
第二,跨 8 个 AI 编程平台。Claude Code、Cursor、Codex、OpenCode、GitHub Copilot CLI、Gemini CLI、Factory Droid 等。这意味着 superpowers 的 skill 文件不能用任何平台的特有特性,全部是纯 markdown + 约 2000 tokens 的 bootstrap 引导词。
第三,2026-01-15 被 Anthropic 官方 Plugin Marketplace 接收。一个第三方框架被原厂收编,这在生态里是稀有事件——意味着 Anthropic 内部也认可 superpowers 的方法论价值。
适合谁用?
- 团队工程纪律差,需要框架强制规范 → superpowers 的强制工作流就是为这个设计的
- 项目复杂、bug 多、重构频繁 → 七阶段流程能把回归 bug 降到很低
- 你跨多个 AI 编程平台工作 → superpowers 是唯一在 8 个平台一致工作的框架
不适合谁?
- 做快速原型、写一次性脚本 → 七阶段流程的开销太大
- 经验丰富、自己已经形成稳定工作流的工程师 → 强制框架会让你觉得被掣肘
anthropics/skills:官方公共库的双重身份
这个仓库最有意思的地方,是它同时扮演两个角色——既是教育示范,又是生产实现。
打开 README 你会看到这样一句声明:「These skills are provided for demonstration and educational purposes only」——这些 skill 仅供演示和教育目的使用,使用前必须自己充分测试。
听起来像是免责声明,但仔细看仓库结构你会发现一件事:
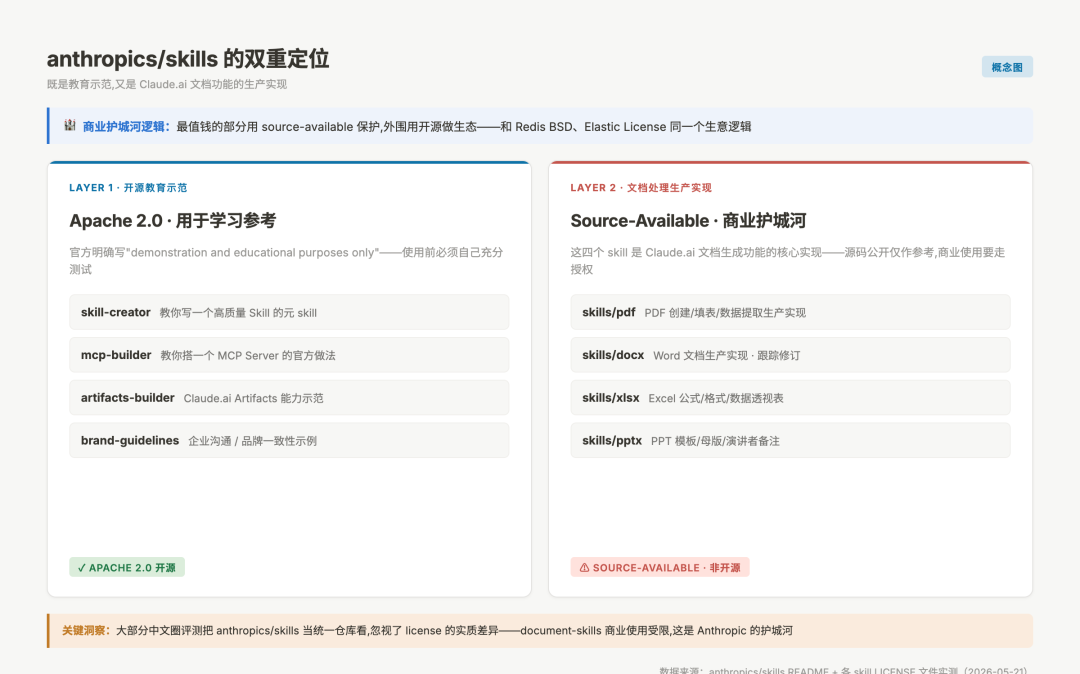
anthropics skills 双重定位:Apache 2.0 教育示范层 + Source-Available 文档处理生产层
图:anthropics/skills 的两层架构——开源 skill-creator/mcp-builder + source-available 的 pdf/docx/xlsx/pptx
仓库里的 skill 分两层:
第一层:教育示范类(Apache 2.0 开源)
skill-creator:教你怎么写一个高质量 Skill 的元 skillmcp-builder:教你怎么搭一个 MCP Server- 还有创意类、企业沟通类等示例 skill
第二层:文档处理类(source-available 而非开源)
skills/pdf:Claude 处理 PDF 的生产实现skills/docx:Word 文档生成的生产实现skills/xlsx:Excel 处理的生产实现skills/pptx:PowerPoint 处理的生产实现
关键差别在这里:第二层不是开源——是「source-available」,源码可见,但 license 限制了商业重用。这四个 skill 是Claude.ai 文档生成功能的核心实现,开放源码是给开发者作参考,但商业使用要走 Anthropic 的授权。
这是个典型的商业护城河设计——和 Redis 改 BSD License、Elasticsearch 改 Elastic License 是同一个生意逻辑:最值钱的部分用 source-available 保护,外围用开源做生态。
适合谁用?
- 想学怎么写一个好的 Skill →
skill-creator是最权威的教材 - 想搭 MCP Server →
mcp-builder是 Anthropic 官方做法 - 实际项目需要处理 PDF/Word/Excel/PPT → 直接装文档 skill,能力跟 Claude.ai 一致
不适合谁?把它当主力 Skill 来源——官方明说了是教育示范,真正驱动你日常工程效率的,还是 mattpocock 或 superpowers 这类专门设计的。
Skill 比 prompt 模板强 10 倍的真正原因
聊到这里有个根本性问题必须说清楚:为什么这三个仓库这么火?凭什么 Skill 取代 prompt 模板?
我看了一圈中文圈的评测,发现大部分人讲的是表面原因——「可复用」「结构化」「跨项目」。这些都对,但都没说到点子上。
真正的根本差异是触发权。
prompt 模板的工作模型是:你记住有这么个模板,需要时手动复制粘贴。模板再好,用不用的决定权在你手里。
Skill 的工作模型是:你写好 description 和 when_to_use,Claude 自己判断「现在应该用这个 skill」。决定权从你手里交到了 Claude 手里。
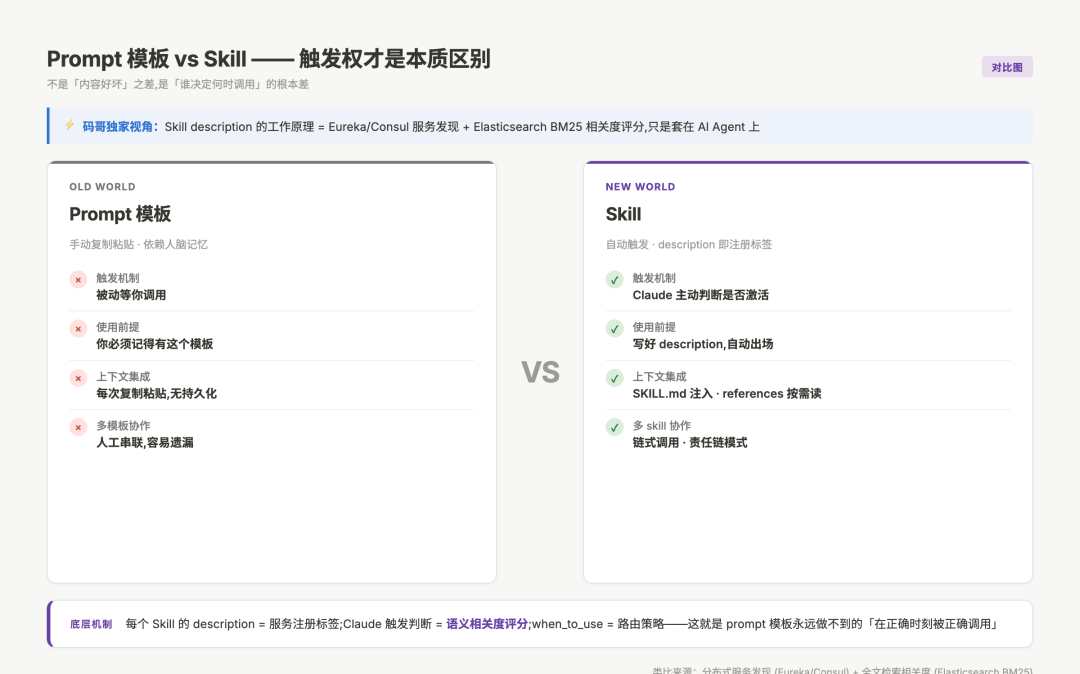
Prompt 模板 vs Skill 触发机制对比:被动等调用 vs 主动判断激活
图:prompt 模板和 Skill 在触发机制、使用前提、上下文集成、多对象协作四个维度的本质差异
这个差异在工程上对应的是服务发现机制。
我做后端的人对这个特别敏感——这本质上是 Eureka/Consul 在 AI Agent 上的对应物:
- 每个 Skill 的 description 字段 = 服务注册时的标签
- Claude 触发 Skill 的判断逻辑 = 服务发现里的相关度评分(类似 Elasticsearch 的 BM25)
- Skill 的 when_to_use 描述 = 服务路由策略
当你问 Claude「帮我重构这个函数」时,Claude 会扫描所有注册的 Skill description,找出语义最匹配的那一个(或几个)触发。如果你装了 mattpocock 的 /tdd,它的 description 写得精确到「触发条件」,Claude 大概率会觉得「现在必须用 tdd」并自动激活。
这就是为什么 prompt 模板再好也比不上 Skill——prompt 是被动等你调用,Skill 是主动判断该出场了。
这也解释了为什么 obra/superpowers 强调「skill description 要写得精确到触发条件」——因为 description 模糊的话,Claude 在两个相关 skill 之间会犹豫甚至误判,整个工作流就乱了。
三个体系怎么选:决策矩阵
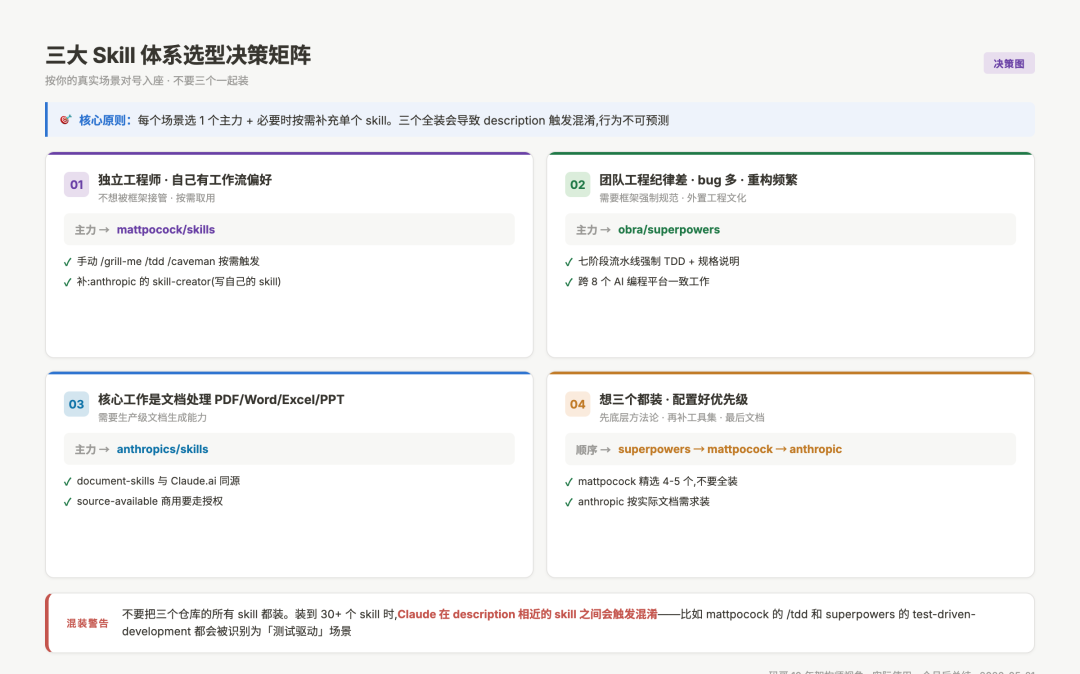
三大 Skill 体系选型决策矩阵:4 个真实场景对应的主力仓库 + 混装警告
图:独立工程师 / 团队纪律差 / 文档处理 / 三个都装 四种场景的选型建议 + 混装时的触发混淆警告
回到那个最初的问题——「我应该装哪个」?
按我实际用过这三个仓库一个月的判断,给一个最简化的决策矩阵:
情况 1:你是个独立工程师,对工作流有自己的想法
主力装 mattpocock/skills,按需取用单个 skill。它给你工具不绑你流程,符合「我知道我在做什么」的工程师心态。补充:从 anthropics/skills 装 skill-creator,方便你写自己的 skill。
情况 2:你的团队工程纪律差、bug 多、需要框架强制规范
主力装 obra/superpowers。它的七阶段流程会逼着团队成员先写测试、先做规格说明、先 brainstorm。强制力是它最大的价值,对纪律差的团队是「外置的工程文化」。
情况 3:你的核心工作是文档处理(PDF / Word / Excel / PPT)
主力装 anthropics/skills 的 document-skills 插件。这是唯一跟 Claude.ai 同源的生产级文档处理能力。其他场景按需补充。
情况 4:你想三个都装
可以,但要按这个优先级配置:
- 先装
obra/superpowers作为底层方法论(如果你需要强约束) - 再装
mattpocock/skills作为补充工具集(精挑选 4-5 个用得上的,不要全装) - 最后装
anthropics/skills的 document-skills(按实际需求)
核心警告:不要三个仓库的所有 skill 都装。我自己装了 30+ 个 skill 后发现一个问题——Claude 在描述相近的 skill 之间会触发混淆,比如 mattpocock 的 /tdd 和 superpowers 的 test-driven-development 描述类似,Claude 可能会在不同 session 里随机选其中一个,导致行为不一致。
踩坑提醒:混装时最容易出的三个问题
坑 1:Skill description 冲突导致触发混乱
mattpocock 的多个 skill 和 superpowers 的 meta-skill 都涉及「代码审查」「测试驱动」「需求澄清」这些场景。description 写法不一致,Claude 会在它们之间反复横跳。
解决:装完之后,打开两个相关 skill 的 SKILL.md,对比 description——保留 description 更精确的那个,删掉另一个。
坑 2:Plugin marketplace 注册顺序问题
obra/superpowers 现在已经在 Anthropic 官方 marketplace 里。如果你之前用 /plugin install superpowers@superpowers-marketplace 装过(旧路径),现在又通过官方 marketplace 装一遍(新路径),会同时存在两份副本。
解决:用 /plugin list 看一下当前装了哪些版本,把旧路径的卸载,只保留官方 marketplace 的版本。
坑 3:把 anthropics/skills 当作主力 Skill 源
anthropics/skills 的 README 明确写了是「demonstration and educational purposes」。我之前把它当主力装的时候发现,它的 skill 设计偏向「广而薄」——能演示给你看怎么写 skill,但实际工程深度比不上 mattpocock 或 superpowers 专门设计的。
解决:把 anthropics/skills 当工具书用——需要的时候查 skill-creator 的写法,用 document-skills 处理文档,不要把它当 Claude Code 工作流的主力。
常见问题
Q:这三个仓库装在一起会不会冲突?
A:不会真正冲突(不会让 Claude Code 报错),但会触发混乱——多个 description 相近的 skill 同时存在,Claude 选择哪个是不确定的。建议按上面决策矩阵选一个主力,另外两个按需补充单个 skill。
Q:obra/superpowers 既然被 Anthropic 官方收编了,为什么没合并进 anthropics/skills?
A:因为定位不同。anthropics/skills 是「Skill 公共库 + 文档处理生产实现」,superpowers 是「方法论框架」——前者是数据,后者是规则。两者在仓库形态上没法合并,但通过官方 Plugin Marketplace 实现了「发行渠道统一」。
Q:mattpocock/skills 主要为 TypeScript 设计,Java/Go 工程师用会有问题吗?
A:大部分核心 skill 是语言中立的(/grill-me、/tdd、/diagnose、/zoom-out、/improve-codebase-architecture),跟语言无关。只有 /migrate-to-shoehorn 和 /setup-pre-commit 是为 JS/TS 工具链优化的——这两个 Java/Go 项目里直接忽略就行。
Q:Skill 比 prompt 强 10 倍的「10 倍」是怎么算出来的?
A:不是精确数字,是工程师的口语化表达。具体可以分三个维度对比:①触发机制(被动 vs 主动,1:N 量级);②上下文集成(一次复制 vs 持久注入,1:M 量级);③ 多 skill 协作(孤立 vs 链式调用,1:N 量级)。综合下来一个数量级的差距,所以叫「10 倍」。
Q:Skill 生态这波热度能持续多久?现在投入学习值不值?
A:底层判断是 Skill 模式不会被替代——它解决的是「让 LLM 在正确时刻触发正确能力」这个根本问题,比 prompt 模板进化了一代。但具体哪个仓库会笑到最后不好说。我的建议是不要押注单一仓库,重点掌握「怎么写一个 Skill」(用 skill-creator 学)和「Skill 触发机制原理」(看 superpowers 的 description 写法)——这两个能力是可迁移的。
总结
说到底,这波 Skill 生态炸榜不是偶然——它解决的是 prompt 模板永远解决不了的问题:让 AI 在「该出手的时候自己出手」。
三大体系里,library 给你工具的自由,framework 给你纪律的强制,reference 给你官方的标杆——每一种都对应一类工程师的痛点。
我个人现在用的是 mattpocock 主力 + superpowers 的 brainstorming 单个 skill + anthropics 的 skill-creator,三个仓库各取一部分,没有谁能完全替代谁。
下篇打算拆一个具体的:自己写一个真正用得上的 Skill,怎么把 description 写到 Claude 自动触发的精度——感兴趣的关注一下,发了第一时间推给你。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号