MOEA/D与NSGA-II在多目标优化中的适用性


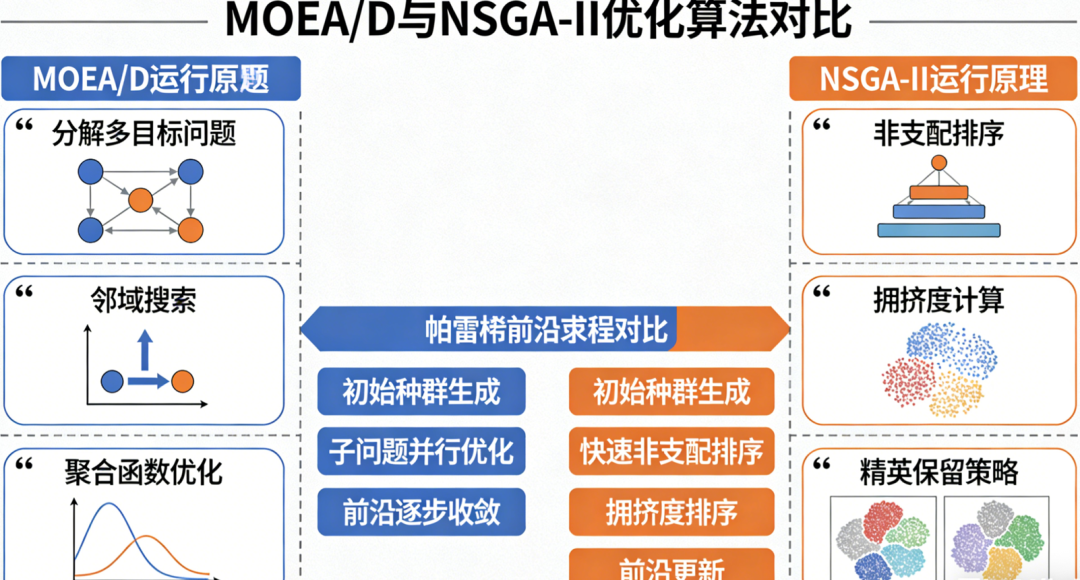
MOEA/D和NSGA-II都是多目标进化算法中的经典代表,但它们解决问题的思路截然不同。简单来说, NSGA-II是基于“支配关系”直接筛选好解,而MOEA/D则是通过“分解”将多目标问题拆解成多个单目标子问题来协作求解 。下面从原理、步骤和适用场景三个方面详细拆解。
1
核心区别:支配 vs 分解
维度 | NSGA-II | MOEA/D |
|---|---|---|
核心思想 | 基于帕累托支配:直接利用解之间的支配关系对种群进行分层排序。 | 基于分解:将多目标问题分解为若干个单目标子问题,通过协作进化求解。 |
选择依据 | 解的优劣由非支配层数和拥挤度距离共同决定。 | 解的优劣由聚合函数值(如加权和、切比雪夫)决定,每个子问题对应一个聚合函数。 |
多样性维持 | 拥挤度距离:在目标空间中,优先保留周围解稀疏的个体。 | 权重向量分布:预先设置一组均匀分布的权重向量,子问题的解对应不同的偏好方向,从而覆盖整个前沿。 |
邻域概念 | 通常不显式定义邻域,整个种群参与交配和选择。 | 显式定义邻域(权重向量相近的子问题集合),进化操作主要在邻域内进行,促进局部信息共享。 |
2
原理本质与步骤详解
NSGA-II:基于非支配排序的精英算法
原理本质 NSGA-II通过 快速非支配排序 将种群划分为多个层次(第一层是帕累托前沿,第二层是被第一层支配的剩余解中的前沿,以此类推)。层数越小,解越优。在同一层内,使用 拥挤度距离 衡量解的稀疏程度,距离越大代表周围解越少,越有助于保持多样性。选择时优先保留层数低且拥挤度大的解。
核心步骤
- 初始化:随机生成规模为N的父代种群P0。
- 非支配排序:对P0进行快速非支配排序,得到每个个体的层数(rank)和拥挤度距离。
- 进化生成子代:通过锦标赛选择(基于rank和拥挤度)、交叉、变异生成子代种群Q0,规模也为N。
- 合并与筛选:将父代P0和子代Q0合并为规模2N的种群R。对R进行非支配排序,并计算拥挤度。
- 精英保留:从R中依次选择非支配层(从第一层开始)填充新父代P1,直到填满N。如果最后一层不能全部放入,则依据拥挤度距离从大到小选取,直到填满。
- 迭代:重复步骤3-5,直到满足终止条件。
MOEA/D:基于分解的多目标进化算法
原理本质 MOEA/D首先需要一组均匀分布的权重向量(数量等于种群规模N),每个权重向量λ对应一个子问题。子问题的目标是通过某种聚合函数(如切比雪夫聚合法)将多目标转化为单目标。算法为每个权重向量维护一个当前最优解,并且定义了一个邻域关系:权重向量相近的子问题互为邻域。进化过程中,子问题之间通过邻域交换信息,协作优化。
核心步骤
- 初始化:
- 生成N个均匀分布的权重向量λ¹, λ², ..., λᴺ,并计算每个权重向量的T个最近邻(欧氏距离),构成邻域B(i)。
- 随机生成初始种群x¹, x², ..., xᴺ,计算每个个体对应的目标向量F(xⁱ)。
- 初始化理想点z = (z₁ , ..., zₘ ),其中zⱼ是当前种群中第j个目标的最小值。
2. 进化:对于每个子问题i(i=1,...,N):
- 繁殖:从邻域B(i)中随机选择两个个体作为父代,通过遗传算子生成新个体y。
- 更新理想点:如果y的目标值能改进理想点z ,则更新z 。
- 更新邻域解:对于邻域B(i)中的每个子问题j,如果y的聚合函数值(基于权重λʲ和当前理想点)优于xʲ的聚合函数值,则用y替换xʲ。
3. 终止判断:若满足终止条件(如达到最大迭代次数),则输出当前种群中的所有非支配解;否则返回步骤2。
3
适用场景对比
场景 | NSGA-II | MOEA/D |
|---|---|---|
目标个数 | 适合2-3个目标的低维多目标问题。当目标数超过4个(高维)时,非支配解比例急剧上升,选择压力下降,效果显著变差。 | 对高维多目标问题(4个及以上)适应性更好,因为聚合方法避免了支配关系失效。 |
帕累托前沿形状 | 对前沿形状不敏感:能很好地处理非凸、不连续、甚至退化的前沿,因为基于支配不依赖前沿几何性质。 | 对前沿形状敏感:基于均匀权重向量假设前沿是连续的,对于不规则前沿(如前沿呈尖峰、断崖)需要设计自适应权重才能保持分布性。 |
问题规模 | 计算复杂度为O(MN²)(M为目标数,N为种群规模),适合中小规模种群。 | 计算复杂度较低(O(MNT)),T为邻域大小,通常远小于N,适合大规模种群和快速求解。 |
偏好集成 | 不易引入决策者偏好,主要通过后处理选择解。 | 天然支持偏好集成:权重向量可视为决策者的偏好方向,可直接引导搜索。 |
典型应用 | 工程结构优化、调度问题、机械设计等经典多目标优化。 | 高维投资组合、大规模多目标优化、需要快速响应且问题规则性较好的场景。 |
4
总结:如何选择?
如果问题 目标数不超过3个 ,且追求 解的分布性和通用性 , NSGA-II 是稳妥的经典选择。
如果问题 目标数较多(≥4) ,或需要 快速得到一个近似前沿 ,并且 对前沿形状有一定先验知识(比如连续凸性) , MOEA/D 更合适。
当面对 前沿极不规则 的高维问题时,可以考虑MOEA/D的变体(如自适应权重调整),或采用基于指标的算法(如IBEA)来弥补不足。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号