高阶神经加性模型:支持特征交互的可解释机器学习模型

高阶神经加性模型:支持特征交互的可解释机器学习模型

CreateAMind
发布于 2026-06-01 19:41:21
发布于 2026-06-01 19:41:21
高阶神经加性模型:支持特征交互的可解释机器学习模型
Higher-order Neural Additive Models: An Interpretable Machine Learning Model with Feature Interactions
https://arxiv.org/pdf/2209.15409v2


摘要
神经加法模型(Neural Additive Models, NAMs)最近在保持可解释性的同时,展现出了具有前景的预测性能。然而,其能力仅限于捕捉一阶特征交互,这限制了它们在真实世界数据集上的有效性。为解决这一局限性,我们提出了高阶神经加法模型(Higher-order Neural Additive Models, HONAMs),这是一种可有效且高效地捕捉任意阶特征交互的可解释机器学习模型。HONAMs 在不牺牲可解释性的前提下提升了预测准确性,而可解释性是高风险应用场景中的一项基本要求。HONAM 的这一优势有助于分析和提取数据集中存在的高阶交互作用。HONAM 的源代码公开于:https://github.com/gim4855744/HONAM/。
索引术语—广义加法模型(Generalized Additive Model)、特征交互(Feature Interactions)、可解释机器学习(Interpretable Machine Learning)、可解释性(Interpretability)
I. 引言
黑盒模型(如深度神经网络)已在计算机视觉、自然语言处理和推荐系统等多个领域展现出卓越的预测性能。然而,其决策过程本质上是不可透明的。近年来,各类可解释人工智能(Explainable Artificial Intelligence, XAI)方法被开发出来,旨在通过识别影响预测的关键特征或区域来揭示这些决策过程。尽管如此,XAI 在医疗、社会安全等高风险领域的应用仍然有限,因为这些方法常常对底层模型的行为提供不准确或缺乏忠实性的解释 [1], [2]。需要注意的是,在本文中,我们明确区分"解释方法"(例如,事后特征归因方法,如 SHAP 和 LIME)与"可解释模型"(例如,玻璃盒模型,如线性模型和广义加法模型)。
近期,神经加法模型(Neural Additive Models, NAMs)被提出,旨在通过整合神经网络来增强广义加法模型(Generalized Additive Models, GAMs)[3]。NAM 由一组神经网络的线性组合构成,每个网络对应一个单独的输入特征。尽管 NAM 在保持可解释性的同时,相较于极端梯度提升(XGBoost)和多层感知机(MLPs)展现出具有竞争力的性能,但其存在一个显著局限:仅能捕捉一阶特征交互。具体而言,NAM 的预测可分解为各个特征的加法贡献。然而,真实世界的数据集通常涉及高阶交互作用——即由多个特征组合所产生的效应——而 NAM 无法捕捉此类交互。这一局限性导致其预测性能次优,且解释质量较低。
为克服这一局限,我们提出了一种新型可解释机器学习模型,称为高阶神经加法模型(Higher-order Neural Additive Models, HONAMs)。由于 NAM 不适合捕捉高阶特征交互,我们重构了 NAM 的加法框架,以有效捕捉任意阶的特征交互。此外,我们提出了一种新的特征交互建模方法,旨在解决现有方法在可解释性挑战和计算成本方面的问题。HONAM 由一组神经网络的线性组合构成,每个网络对应一个单独的输入特征,而所提出的交互方法则用于建模任意阶的特征交互。因此,HONAM 在保持可解释性的同时,能够捕捉非线性的高阶特征交互作用。
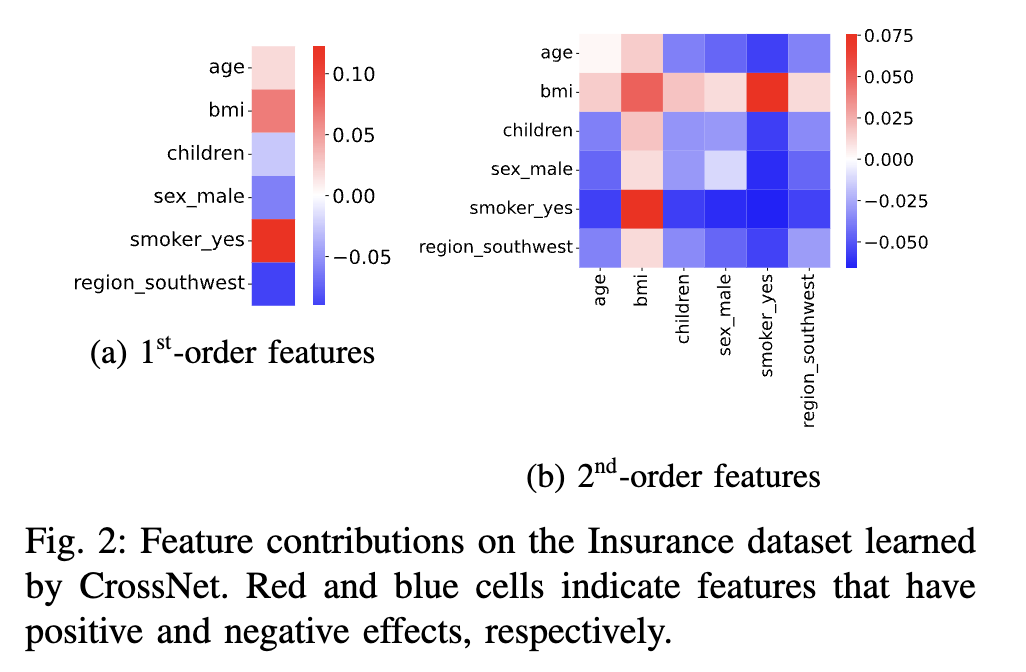
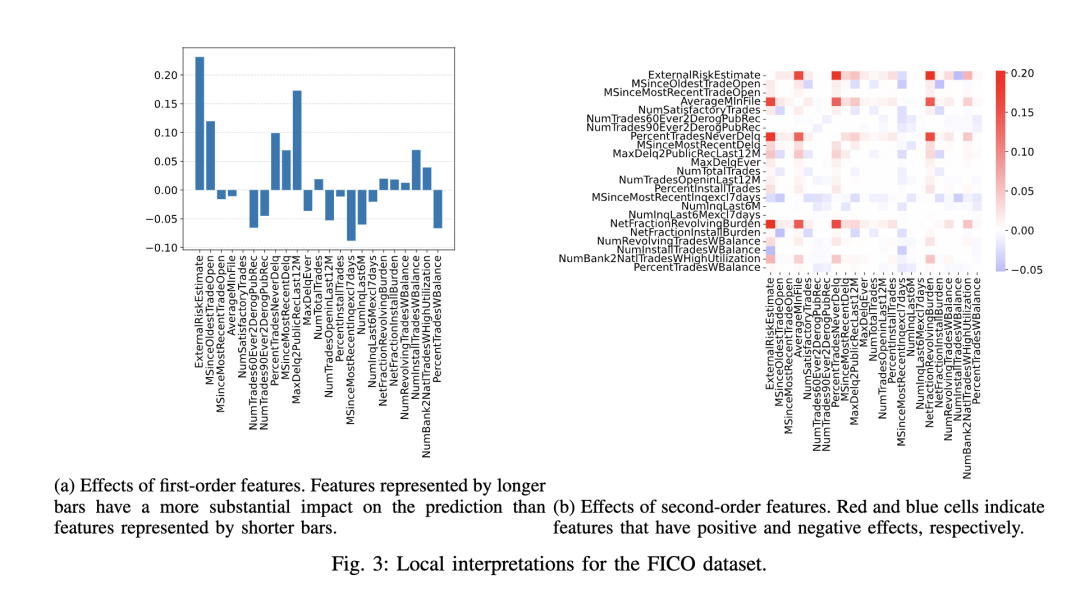
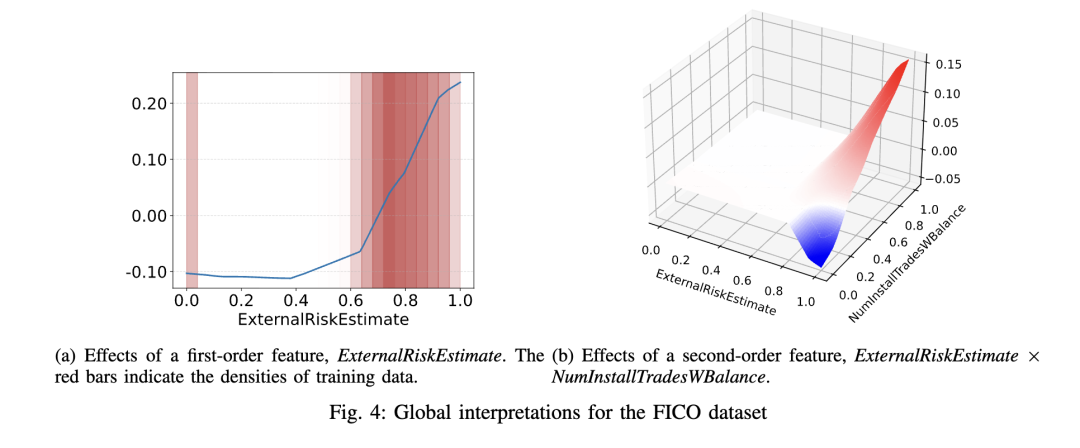
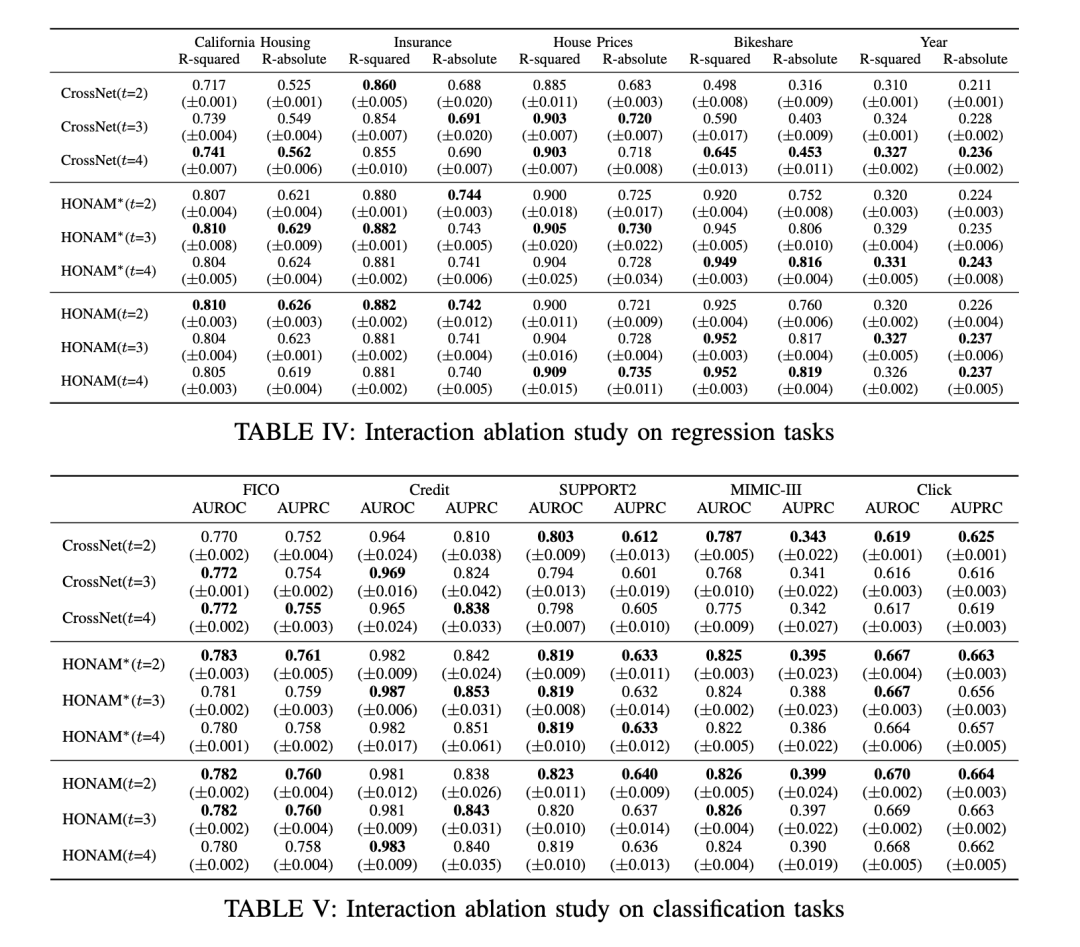
我们使用多种真实世界数据集进行了大量实验,以评估 HONAM 的有效性。实验结果表明,HONAM 优于现有的可解释模型,并与黑盒模型相比达到了具有竞争力的性能。通过可视化 HONAM 的预测结果(尤其是一阶和二阶特征交互),我们证明 HONAM 能够有效识别 NAM 无法捕捉的二阶交互中的有价值模式。这凸显了 HONAM 在那些既要求强预测性能又要求高质量解释的高风险领域中的适用性。此外,HONAM 的这一优势也可有益于数据挖掘任务,例如偏差检测 [3], [4] 和科学发现 [5], [6],而这些任务中可解释模型已被成功应用。
II. 相关工作
A. 特征交互方法

显式捕捉特征交互的机器学习方法已被广泛研究。分解机(Factorization Machine, FM)[7] 同时捕捉一阶和二阶特征交互,表现出强劲的性能,特别是在推荐系统中。高阶分解机(Higher-order FM, HOFM)[8] 扩展了 FM 以捕捉二阶以上的交互。注意力分解机(Attentional FM, AFM)[9] 将注意力机制整合到 FM 中以动态加权特征交互。最近,神经网络已被用于捕捉高阶交互 [10], [11]。交叉网络(Cross Network, CrossNet)[12] 采用类似于多层感知机(MLP)的多层结构,但在每一层中将一阶特征的和相乘而不使用激活函数,使得 tt 层 CrossNet 能够捕捉高达 tt 阶的交互。几种方法也被开发出来以同时捕捉跨多个阶的特征交互 [13], [14]。此外,自适应分解网络(Adaptive Factorization Network, AFN)[15] 在学习过程中自适应地选择交互阶数。
特征交互方法在推荐和回归等预测任务中已显示出成功。尽管它们有效,但这些方法面临几个挑战。许多现有方法依赖于线性交互,限制了它们对复杂非线性关系建模的能力,从而限制了它们的表达能力。虽然一些方法利用深度神经网络来捕捉高阶交互,但它们通常缺乏可解释性。此外,大多数关于特征交互的先前研究主要集中在预测性能上,往往忽视了线性模型固有的可解释性。
B. 广义加法模型
GAM 是内在可解释(即透明)模型的领先框架 [16]–[18]。GAM 将输出表示为单变量函数的线性组合,每个函数反映单个特征的贡献。由于其可解释性和强大的预测性能,GAM 特别适用于高风险领域 [18], [19]。GA2M [20] 通过整合二阶(成对)特征交互对 GAM 进行了扩展。可解释提升机(EBM)[21] 是一种基于树的 GAM,它超越了传统 GAM,并与随机森林和 XGBoost 等基于树的集成模型相比达到了具有竞争力的准确率。然而,将基于树的模型扩展到多任务、多标签或迁移学习具有挑战性 [3], [22]。广义加法神经网络(GANN)[23] 利用浅层神经网络构建非线性 GAM,而最近引入的神经加法模型(NAM)[3] 则利用深度神经网络,捕捉更复杂的非线性关系。尽管 NAM 优于其他 GAM,但其仅限于捕捉一阶特征交互。NodeGAM 和 NodeGA2M [22] 是基于神经树的 GAM;然而,它们分别仅限于一阶和二阶交互。此外,现有的 GAM 依赖于手动设计的特征来表示高阶交互,这需要领域专业知识且耗时。因此,它们通常将所有组合特征作为输入,但这会导致随着交互阶数的增加,模型大小和计算时间呈指数级增长。相比之下,我们提出的 HONAM 通过一个高效的特征交互模块,保持了恒定的模型大小,并在计算复杂度上随特征数量和交互阶数呈线性扩展。
C. 可解释人工智能
深度神经网络已在多个领域展现出卓越的性能,然而其决策过程仍然难以理解。为解决这一问题,研究者提出了大量可解释人工智能(Explainable AI, XAI)方法。若干研究采用注意力机制来评估特征重要性或选择显著特征 [24], [25]。例如,TabNet [26] 使用类似于注意力分数的软掩码(soft mask)来识别重要特征。尽管注意力机制能有效突出关键特征,但其解释可能并不总能可靠地反映模型真实的预测过程 [27]–[29]。
近期的 XAI 方法遵循事后(post-hoc)、模型无关(model-agnostic)的方式,可应用于任何机器学习模型而不影响其性能。例如,分层相关性传播(Layer-wise Relevance Propagation, LRP)[30] 将模型输出分解为相关性分数,并将其反向传播至输入层以指示特征重要性。然而,LRP 可能产生误导性解释。为解决这一问题,深度学习重要特征(Deep Learning Important FeaTures, DeepLIFT)[31] 采用了一种基于参考的策略。局部可解释模型无关解释(Local Interpretable Model-agnostic Explanations, LIME)[32] 使用可解释的代理模型在局部近似黑盒模型的预测,当近似准确时能有效解释单个预测。沙普利加法解释(SHapley Additive Explanations, SHAP)[33] 是一种基于博弈论的方法,通过衡量因特征缺失而导致的预测变化来评估特征影响。尽管取得了这些进展,XAI 方法仍可能产生无法可靠反映模型真实行为的解释 [1], [2], [34]–[40],从而限制了它们在高风险领域的应用。
近年来,反事实(Counterfactual, CF)示例方法——即生成一个与原始数据点差异最小但能产生不同预测的数据点——受到了广泛关注。[41] 提出了针对基于树的模型的 CF 方法,而 [42] 则开发了一种专门用于可微分模型(如神经网络)的方法,以生成可操作且多样化的 CF 示例。针对神经网络的其他 CF 方法也被提出 [43], [44],包括 [45] 提出的基于强化学习的方法。由于对预测模型具有内在的忠实性,CF 方法相较于 SHAP 等传统特征归因方法具有优势。然而,CF 方法仍面临若干局限性:(1)难以准确确定特征重要性;(2)所推导的特征重要性可能无法真实反映模型的决策过程;(3)单个特征的真实贡献仍不清晰。
III. 高阶神经加法模型
A. 神经加法模型的问题陈述
在本文中,我们旨在解决 NAM 的局限性。原始 NAM 的公式定义如下:
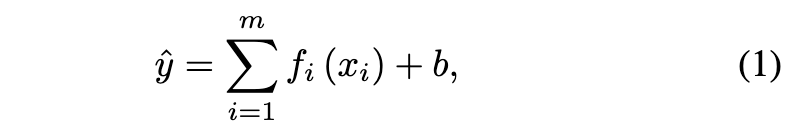

B. 神经加法模型的变换
我们的目标是使 NAM 能够建模高阶特征交互;然而,原始 NAM 结构不适用于此目的,因为它为每个针对特定特征的 MLP 输出标量值。有效的特征交互建模需要向量输出。因此,我们引入了一种改进的 NAM 结构,它更适合捕捉特征交互,定义如下:
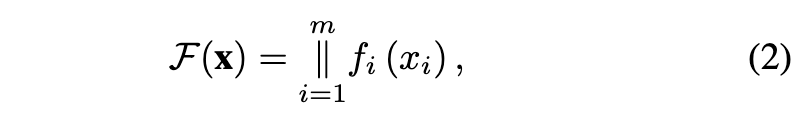

C. 建模高阶特征交互
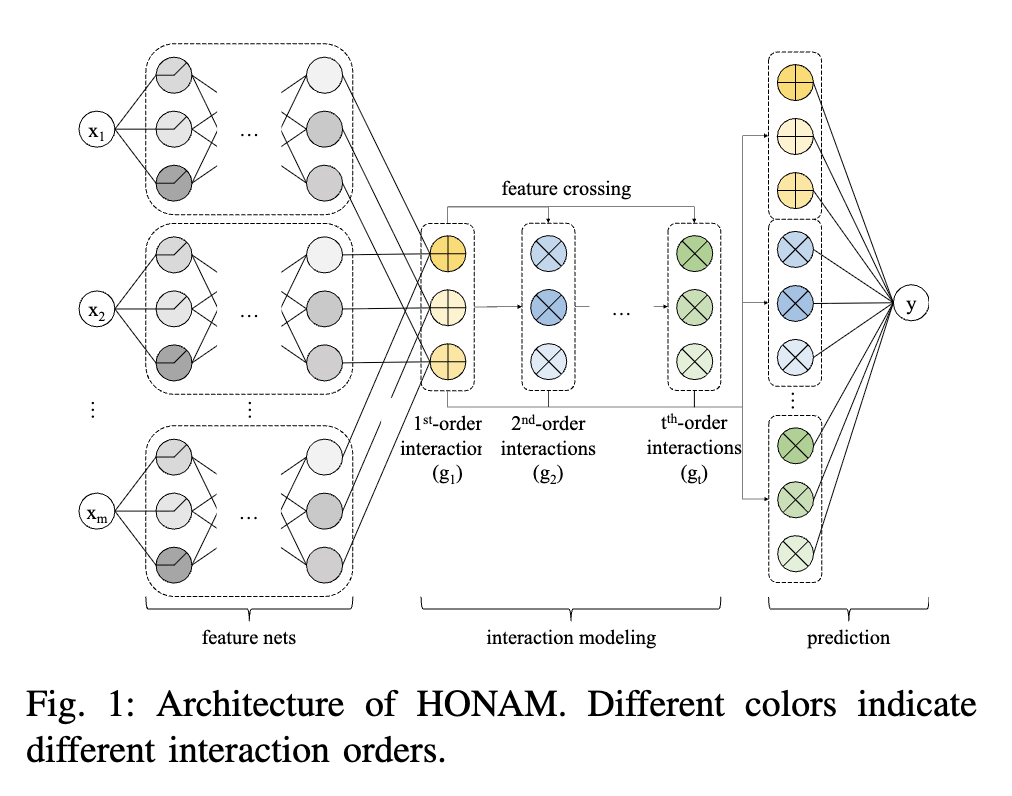
我们要开发 HONAM 的目标是扩展 NAM,使其能够捕捉高阶特征交互。为了实现这一目标,我们提出了一种架构,该架构由 NAM 与一个高阶特征交互模块级联而成,如图 1 所示。由此得到的 HONAM 定义如下:
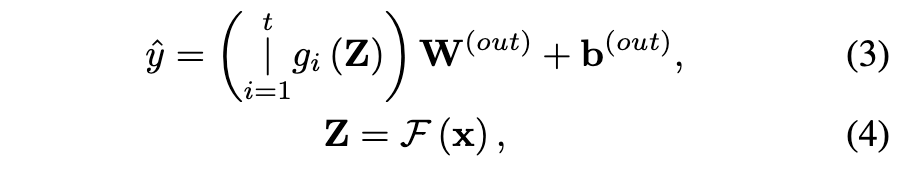

公式 (3) 中的高阶特征交互模块可以使用 CrossNet [12] 来实现,其定义如下:
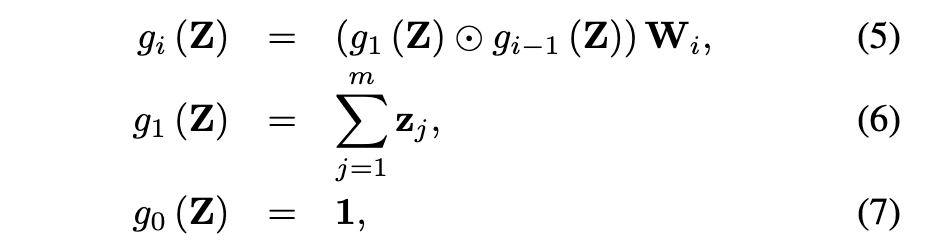

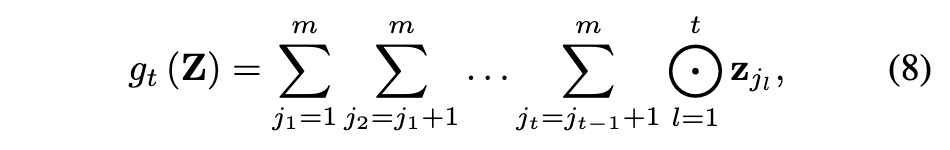

命题 1。 为了缓解公式 (8) 中简单枚举方法的计算复杂度,我们提出了一种用于高效计算高阶特征交互的递归公式,定义如下:
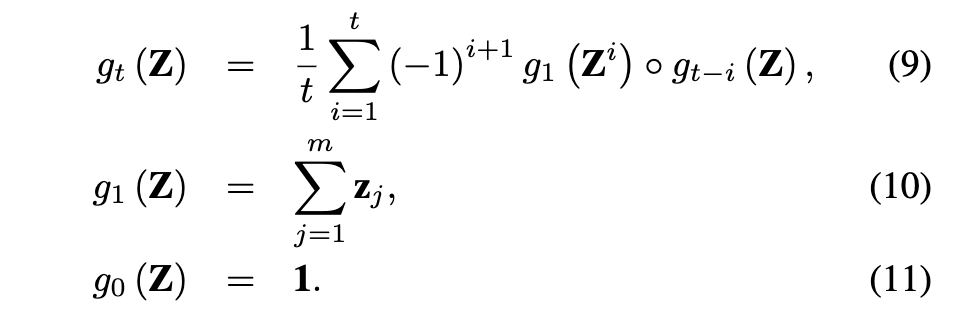
那么,公式 (9) 中的递归公式等价于公式 (8) 中描述的简单枚举法。命题 1 的证明见附录 A。
利用动态规划,公式 (9) 的时间复杂度为
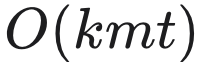
。因此,我们可以在线性时间内高效计算 tt 阶特征交互,而无需生成幂次项。
D. HONAM 的可解释性
与现有的可解释模型相比,我们的 HONAM 具有以下优越性:(1) HONAM 通过利用神经网络捕捉复杂的非线性模式。(2) HONAM 通过我们提出的特征交互模块有效地捕捉任意阶的特征交互。
传统的可解释模型主要是线性的或基于树的,而像 NAM、NodeGAM 和 NodeGA²M 这样的近期方法仅限于捕捉一阶或二阶交互。据我们所知,HONAM 是第一个能够以端到端方式捕捉高阶特征交互的可解释模型。

E. 与高阶分解机(Higher-order Factorization Machines)的关系
HOFM 可以被视为 HONAM 的一个特例。具体来说,如果每个特征网络是线性的,并且输出权重是一个全一矩阵,那么 HONAM 就等同于 HOFM。此外,我们提供了理论证明,表明我们的递归公式在功能上等同于附录 A 中的枚举方法。
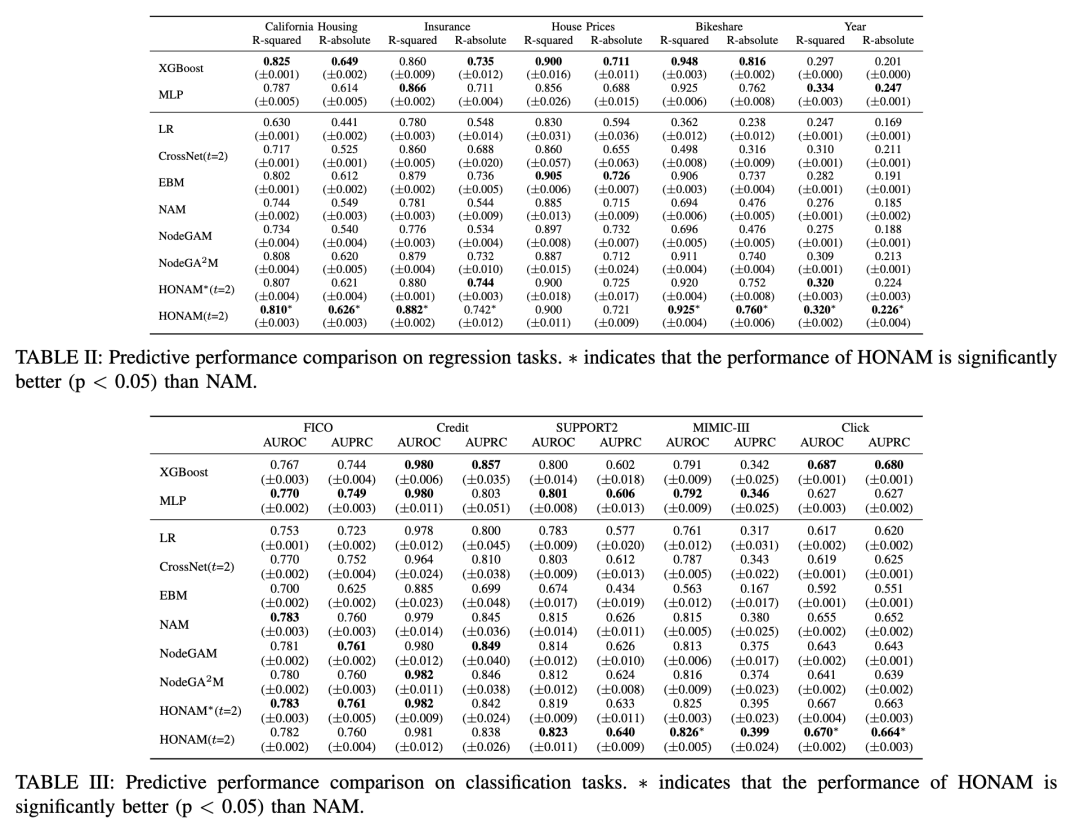
VI.结论
在本研究中,我们提出了HONAM,一种新颖的可解释机器学习模型,能够捕捉任意阶数的特征交互。通过全面的实验,我们证明了所提出的交互方法显著提升了预测性能。通过对一阶和二阶特征交互的局部与全局解释进行可视化,我们强调了建模高阶交互对于增强可解释性的重要性。鉴于其有效性与透明性,我们预期HONAM将在众多领域获得广泛应用。
原文链接:https://arxiv.org/pdf/2209.15409v2
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号