华为韬定律详解,AI圈值得熬夜读的一篇半导体路线图

华为韬定律详解,AI圈值得熬夜读的一篇半导体路线图

乐小野
发布于 2026-06-01 21:47:23
发布于 2026-06-01 21:47:23
前天上海下了点雨,2026 IEEE ISCAS的会场里何庭波站在讲台上,一张PPT切到正中间,τ这个希腊字母占了大半个屏幕。朋友圈里一票做芯片的,连夜在群里转那张幻灯片。这是中国第一次在全球半导体领域抛出产业级的演进新原则,名字叫韬定律,τ的中文音译,听上去有点武侠味儿,底子是一篇相当硬核的论文。
我把论文和现场报道里能找到的细节都翻了一遍,写一份技术解读,重点搞清楚这套体系到底怎么跑、麒麟2026的数字怎么来的、对昇腾和端侧推理后面会有什么传导。
如有不当之处,欢迎在评论区指正。
韬定律到底说了什么
摩尔定律的核心很直白,每两年单位面积的晶体管数量翻一倍,靠的是把晶体管尺寸缩小。这条路走到5nm之后已经开始喘,3nm卡了一阵,2nm到现在也没那么轻松,几何缩微越来越像在啃一块越来越薄的饼。
韬定律换了个变量。它盯的不是晶体管的物理尺寸,而是信号在芯片里跑一圈的时间常数τ。何庭波在论文里把τ拆成了四层,每一层都有自己的优化空间。
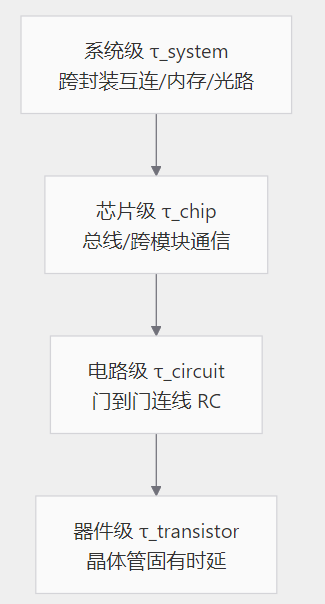
晶体管层的τ是器件的固有RC时延,电路层的τ来自门到门的连线,芯片层的τ涉及总线、跨模块的通信,系统层的τ则覆盖到内存、互连、甚至跨封装的片间通信。整个公式想讲的是,性能不只取决于最底下那颗晶体管多小,而是整个信号路径加起来的等效时延有多短。
这个视角的厉害之处在于,它给出了一条不依赖光刻机的演进路径。EUV短期内拿不到也没关系,只要能在电路、芯片、系统这三层把τ持续压下去,密度和性能依然能跑出代际跳跃。论文里给到一个相当激进的预期,2031年基于韬定律的高端芯片,晶体管等效密度会做到1.4nm节点的水平。
τ的数学拆解,α=10是怎么来的
论文里给到的核心公式相当干净。
这是一条标准的几何衰减形式,下一代的时间常数等于当前的τ除以缩放因子α。摩尔定律在历史上对应的α大约是1.4,每两年密度翻倍,等效到时延维度上差不多就是这个数。韬定律最大的变化在于α不再是全行业一个值,而是按应用场景分层,论文里写得明确,「缩放因子α是特定于应用的,而不是通用的」。
何庭波把α拆成了三档。功能型芯片(手机SoC、消费电子)这一档α相对保守,目标在每代1.5左右。计算型芯片(CPU、通用算力)拉到中间档。AI芯片这一档放到最激进,α=10,按年迭代。
α=10这个数字看上去夸张,但实际上是对过去六年AI算力曲线的拟合反推。从V100到A100到H100再到B200,单卡有效算力大约是每年10x的节奏在涨。这个节奏不是单靠制程做出来的,背后是多个分量乘起来的结果。论文里的τ拆解给了一个相对清晰的视角。
每个分量都可以独立做工程优化,乘起来之后整个系统级的τ才是用户看到的那个数。论文给到的预期分解大概是这样。
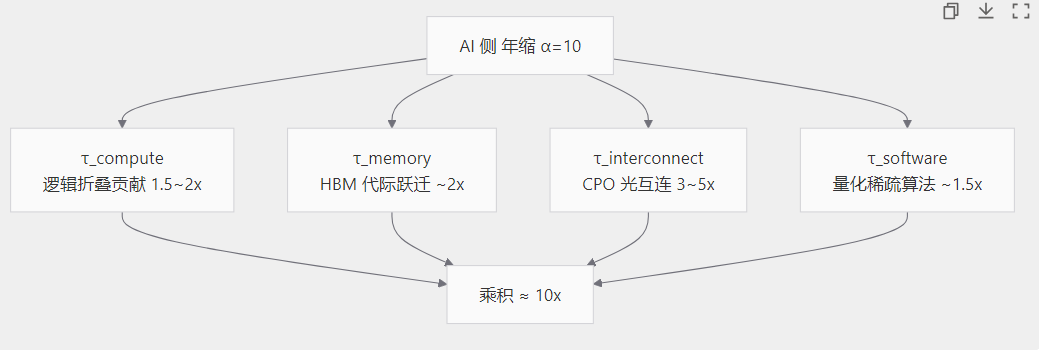
逻辑折叠主要压和层的延迟,麒麟2026实测的频率+13%、能效+41%已经验证了这一档能跑出1.5到2倍的代际收益。HBM4到HBM5的代际跃迁会贡献大约2倍的带宽密度,按SK海力士给的roadmap是2027量产。CPO,共封装光学,落地后那一档能做到3到5倍的提升,1.6T、3.2T的速率档位上电互连已经撞墙,光必须上桌。再加上低精度量化(FP4、INT4)、动态稀疏这些软件侧的优化,每年再贡献1.5倍。几个分量乘起来逼近10倍是数学上跑得通的。
α=10这件事最关键的不是单一技术能不能撑起来,而是它强迫整个产业链同时加速。任何一个分量掉队,AI侧的α就上不到10。这是为什么论文里反复强调全栈协同,而不是单点突破。
顺着这个公式还能反推一件事。如果α=10持续五年,τ会被压缩到原来的十万分之一。换算到算力维度,意思是2031年AI芯片的等效性能相对2026是量级。这个数字听上去离谱,但放到大模型推理的实际需求上,长上下文、Agent链路、视频生成、实时多模态,每一个场景都在吞这种量级的算力。论文给出的α并不是凭空许愿,是被需求侧倒逼出来的。
逻辑折叠这套架构到底怎么跑
理论部分听上去抽象,工程上的关键武器叫Logic Folding,逻辑折叠。
核心思想用一句话讲,把原本平铺在一个面上的关键路径逻辑单元,立起来叠到垂直堆叠层里去,让信号走的物理距离变短,从而压低RC时延。这跟3D NAND那一招在直觉上有点像,但用在逻辑芯片上是另一回事。3D NAND堆的是存储单元,结构相对规整,温度也能控住。逻辑芯片的关键路径门级一旦开始堆叠,要处理的问题完全不是一个量级。

可以从几个维度感受这套打法的复杂度。3D时序的等效约束完全变了,原来EDA工具针对的是一个二维平面布线,现在要支持垂直方向的多层时序闭环。散热被放大,堆叠之后每一层的功率密度怎么分布,是新工具链必须解决的题。良率怎么测、怎么修,封测环节也跟着重写。再加上「自由逻辑(Free Logic)」这个设计理念,何庭波在演讲里讲得很清楚,麒麟2026是从单层扩展到双层,这是商业化的首例。
逻辑折叠不是随便堆两层就能用,背后是一整套从器件、电路、EDA到封测的全栈协同。
论文里有一段披露相当惊人,过去6年内基于韬定律的思路,华为已经设计并量产了381款芯片。这个数字传出来之后,整个行业的认知开始变化,原本以为韬定律是一篇白皮书的概念,实际上是过去六年大量产线沉默积累之后的总结。
麒麟2026的实测,到底有多狠
论文公布了麒麟2026这颗手机SoC的具体测试结果。
指标 | 上一代 | 麒麟2026 | 变化 |
|---|---|---|---|
晶体管密度 | 155 MT/mm² | 238 MT/mm² | +53.5% |
频率 | 基准 | 3.1 GHz | +13% |
能效 | 基准 | 基准×1.41 | +41% |
这是单代数据。按摩尔节奏正常一代是18%密度提升,53.5%相当于一步顶三年的几何缩放。
这里有个细节需要讲清楚。麒麟2026的衬底工艺并没有跨代到所谓“真3nm”,物理工艺节点维持在中芯N+3类似的水平上。密度提升53.5%这件事,主要不是来自更小的晶体管,而是来自双层逻辑折叠让等效面积压缩。如果按摩尔时代的算法,在不换工艺节点的前提下提密度50%基本是不可能完成的任务,但在韬定律的框架下,τ被压短了,等效密度就跟着上去了。
能效提升41%对端侧大模型尤其敏感。端侧推理这两年所有人都在抠每瓦能跑多少token,41%能效落到端侧大模型上,差不多是直接改变力量对比的级别。Claude Code、Codex这种本地跑agent的体验,过去依赖M系列芯片的能效优势,麒麟2026之后国产端侧的天花板会被重新画一遍。我自己还没拿到机器实测,但想想就觉得Qwen3端侧版那套方案在新一代麒麟上跑起来,体感不会比M4差太多。
没有EUV这件事,要重新看
韬定律的发布点很微妙,它出现在中国半导体被卡EUV五年之后。这套体系如果只看技术路径,是一个纯粹的工程优化方案。但放到产业语境里,它解决的是一个相当棘手的问题,没有先进光刻怎么继续往前走。
先把背景理一遍,避免笼统。麒麟9020用的是中芯N+2,第二代7nm类工艺,TechInsights在Mate 70系列上拆解确认。麒麟9030用的是中芯N+3,5纳米级,TechInsights在Mate 80 Pro Max的拆解里看到关键步骤靠SAQP,自对准四重曝光,金属线间距相当激进。这两颗的产线都没碰EUV,全靠DUV多重曝光把节点往前推。这是个产业事实。
但DUV多重曝光这条路是有上限的。曝光次数越多,良率越掉,成本越高,到了4纳米级以下基本就撞墙了。摩尔定律的范式里,没有EUV你就只能停在这个节点上。
韬定律给的答案,是把竞争维度从“谁能做出更小的晶体管”挪到“谁能把信号时延压得更狠”。这是一道完全不同的题。光刻机不再是唯一的胜负手,封装、堆叠、互连、EDA工具链都成了新的主战场。这件事最直接的传导,是对中芯之外的整个产业链来讲,有了一个更大的出口,不再是只有一条路通罗马。
路线图,从2026走到2031
按论文给到的预期,整个韬定律的执行节奏大概是这样。
2026 秋麒麟2026量产双层逻辑折叠首发238 MT/mm²2028多层折叠扩展等效密度对标 3nm节点2031全栈 τ 协同等效密度对标 1.4nm节点韬定律执行节奏
这是一条相当激进的曲线。2028这一代要把折叠从两层扩展到更多层,工具链、散热、良率每一项都不是稳赢的牌。2031的1.4nm等效密度,按现在的几何缩微节奏,台积电的A14节点也大概要等到2028年量产,韬定律走到那个位置中间还差三年的物理时间。
不过这里有一个判断点。如果韬定律的执行节奏比预期慢两年,等效1.4nm要到2033年才落地,对中国半导体行业来说也是一个完全可以接受的结果。因为在没有EUV的前提下,原有路径几乎是没有时间表的。
落到AI侧能看到什么
这一段是我自己最关心的。把视角从手机SoC挪到AI芯片,韬定律的传导路径有三条值得盯。
一是昇腾。逻辑折叠在昇腾下一代上落地的难度比手机SoC更高,AI芯片的die size本来就大,多层堆叠之后散热问题会指数级放大。但收益也最大,能效再上一个台阶之后,单卡算力密度会重新拉开和H100、B200的距离。论文里有一句话讲得很重,AI侧的τ年缩节奏目标是10倍(α=10),这是个相当激进的α值。
二是端侧。麒麟2026这颗芯片秋季就要量产铺到手机上,41%能效提升会让端侧大模型的体验有明显变化。Seedance 2.0这种视频生成模型,如果未来能塞进端侧实时跑,整个内容生产链都得重做。MiniCPM、Qwen3那套agent方案现在在M4上能跑得比较顺,麒麟2026之后国产端侧的体验位会拉上来一档。
三是基础设施侧。论文里有一句被很多人忽略的话,“下一个美元应该投τ而非节点”。这是给整个产业链的导向信号,未来的钱要往封装、内存、互连、EDA工具链这些方向走,而不是死磕光刻机这个单点。
HBM和光互连,国产产业链的具体传导
把τ的拆解套到国内产业链上看,受益最直接的是几条具体的赛道。这块专门展开讲,对做投资和做架构选型的同学都有用。
先说HBM。长鑫存储在上海厂区已经开始量产HBM2,按公开口径下半年HBM3也会出货。母公司睿力集成电路启动IPO辅导之后,资金端进入快车道,长鑫聚焦AI赛道这件事是写进公告里的。武汉新芯(XMC)跟长江存储有深度协同,HBM相关产能正在堆。技术差距方面,相比SK海力士、三星的HBM3E主流量产,国产HBM大致落后1到1.5代,但在韬定律的语境里这个差距可以被Logic Folding和封装侧的优化补回来一部分。意思就是国产昇腾下一代不一定要HBM4才能打,配上逻辑折叠的算力密度提升,HBM3配合τ优化的组合在很多场景里够用。
光互连这块更值得看。中际旭创、新易盛、天孚通信、光迅科技、华工科技这一票公司,过去两年是英伟达算力链的硬件二供,现在韬定律一旦把定义为关键变量,国产AI算力链对光互连的需求会从可选变成必选。CPO这个方向尤其敏感,1.6T、3.2T的速率档位上电互连已经撞墙,光必须上桌。中际旭创在CPO方案上跟博通、英伟达都有合作,这些技术能不能反向授权或者迁移到昇腾产线,是接下来一年的关键观测点。源杰科技、长光华芯做光芯片本体(DFB、EML、VCSEL),这些是CPO的上游核心,国产化率目前不高,韬定律带来的需求会强行把这条线往前推。
先进封装这块绕不开。Logic Folding虽然是芯片内的逻辑堆叠,但落到大die的AI芯片上必然要跟3D封装协同。长电科技的XDFOI从2022年下半年开始量产,是国内最接近CoWoS的方案,做芯粒间高速互连。通富微电跟AMD合作Chiplet封装做了多年,7nm级Chiplet量产能力已经跑通。盛合晶微作为新势力,在硅中介层和RDL中介层上有自己的路线。这三家在韬定律落地节奏里是绕不过去的,特别是2028多层折叠扩展那一代,对中介层的良率和密度要求会陡升一档。
EDA这块是最容易被忽略但最致命的一环。3D时序闭环、跨层布线、热协同仿真,这些东西现在Cadence、Synopsys的主流工具支持都不算完善,给国产EDA留出了一段窗口期。华大九天、概伦电子、芯华章如果能在韬定律的工具链需求里抓住一两个核心点,是有机会卡住一段时间的。这一块的传导周期会比硬件更长,三年内能看到苗头就算快的。
如果要把这几条赛道按受益弹性排个序,我自己的判断是光互连排第一,先进封装排第二,HBM排第三,EDA排第四。原因是越靠近那一档,受益的弹性越大,过去几年这一档的需求是被压抑的,韬定律一旦把它定义成主战场,需求曲线会陡。HBM国产化更多是把性价比拉平,弹性反而没有光互连那么大。
几个还没看清楚的点
写到这里需要诚实一点,韬定律目前还有几个地方没有充分披露或者没法证实。
逻辑折叠的良率没有公开数据。麒麟2026是商业化首例,但量产规模、良率爬坡曲线,论文和何庭波的演讲都没有讲。要等秋季机器铺开之后,从拆机数据反推。
散热方案也是个谜。双层逻辑折叠之后功率密度怎么分布,用了什么新材料或者新结构,论文一笔带过,留了个口子。这块要看后续放出来的IEEE会议论文。
对外授权与生态怎么走没有清晰的表态。何庭波在演讲最后讲了一句“我们呼吁全球合作推动产业演进”,但具体是开源、开放标准还是专利交叉许可,没有给出细节。如果韬定律只是华为内部循环,影响会小很多。如果走开放路线,整个国产半导体产业的玩法都会变。
第三方验证还在路上。台积电、Intel、IMEC对韬定律目前没有公开回应。这种产业级的新原则,最终能不能立得住,要看其他玩家是否跟进。摩尔定律之所以是定律,是因为整个行业都在按它的节奏跑,韬定律要走到那一步,至少还要好几年的产业演化。
α=10这个目标的可持续性也是个问号。第一年靠逻辑折叠拉53.5%密度是相对容易的,第二年开始HBM、光互连、软件侧每个分量都要按预期节奏跟上,任何一个掉链子整条曲线就会塌。这是个工程上很难的题。
写在最后
前天那场会议结束之后,半导体这盘棋上多了一个新的解法。韬定律不是一篇论文,还是过去六年381款芯片沉默积累之后的总结。从这个角度看,它已经被产线验证过了。
对AI行业来说,未来三年最该盯是底下这套算力底座怎么走。麒麟2026秋季量产是第一个观测点,昇腾下一代是第二个观测点,2028多层折叠是第三个观测点。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号