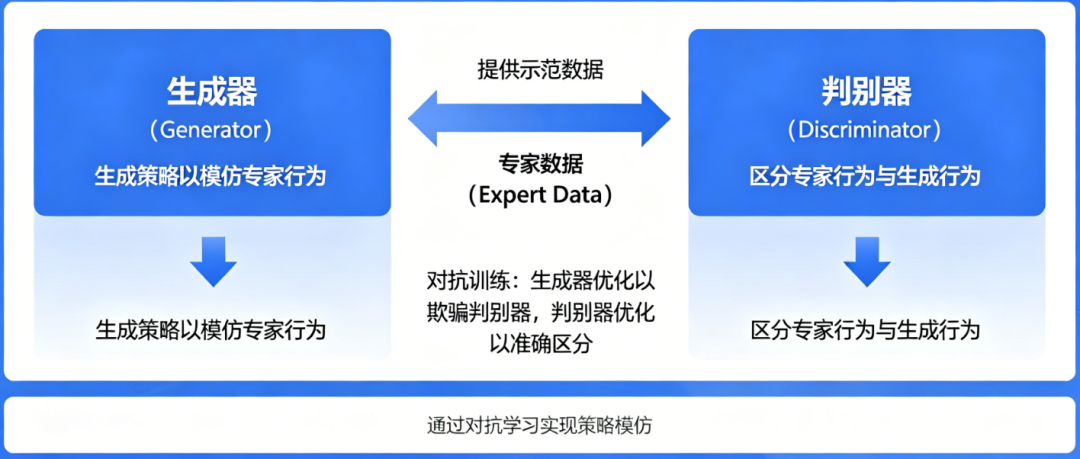
生成对抗模仿学习(GAIL)的原理和步骤


GAIL = GAN(判别器学 reward)+ RL(PPO 更新策略),不需要显式 reward 函数,也不需要专家在线标注,但训练不稳定且计算成本高。
PART 01
核心原理
用 GAN 的思路做模仿学习 :
- 生成器 = 策略网络 πθ,生成状态-动作对 (s,a)
- 判别器 = 分类器,区分"专家数据" vs “策略生成的数据”
判别器的损失信号被反过来当作策略的 隐式 reward ——判别器越认 为 (s,a)是假的,策略得到的奖励越高。策略因此被驱动去生成更像专家的行为。
PART 02
具体步骤
算法:GAIL
输入:专家数据集 D_expert = {(s, a)_expert},环境 env
输出:策略 π_θ
1. 初始化:
- 策略网络 π_θ(生成器)
- 判别器 D_φ(通常是一个二分类网络,输入 (s,a),输出概率)
- D_φ 输出 1 表示"专家",0 表示"策略生成"
2. for iteration = 1 to N:
# --- 步骤1:采集策略轨迹 ---
for episode = 1 to n:
收集轨迹 τ = {(s_t, a_t)},其中 a_t ~ π_θ(s_t)
存储到 D_π
# --- 步骤2:训练判别器 ---
for step = 1 to k: # k 通常 1-5
从 D_expert 采样 batch expert_data
从 D_π 采样 batch policy_data
# 判别器损失:让真数据接近 1,假数据接近 0
loss_D = -E[log D(s,a)]_expert - E[log(1 - D(s,a))]_π
更新 φ 最小化 loss_D
# --- 步骤3:训练策略(用判别器作为 reward)---
# 关键:策略无法直接梯度上升——需要结合 RL 算法(如 PPO)
for step = 1 to m:
采样新轨迹 τ ~ π_θ
# 每一步的 reward 来自判别器:r(s,a) = -log(1 - D_φ(s,a))
# 用 PPO / TRPO 在这个 reward 下更新 π_θ
# --- 步骤4:可选的专家数据辅助 ---
# 在 reward 之外加入 BC 损失,防止策略跑偏
# loss_total = RL_loss + λ * BC_loss
3. 返回 π_θ三个关键理解
① reward 从何而来
判别器的输出被转换为 reward:
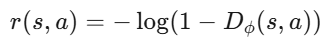
- 当 Dϕ(s,a)→1(判别器认为是专家)→ r→0(低 reward,策略不收鼓励)
- 当 Dϕ(s,a)→0(判别器认为是假的)→ r→+∞(高 reward,策略受到强烈鼓励)
策略最终被训练去"欺骗"判别器,使其认为自己的 (s,a)越来越像专家。
② 为什么需要 RL 算法更新策略
判别器的梯度 无法直接反向传播到策略 ,因为策略的动作采样是离散的(不可导)。所以 GAIL 实际上是一个 GAN + RL 的混合系统 :用 GAN 训练判别器,用 PPO/TRPO 更新策略。
③ 与 IRL 的关系
GAIL 本质上是 IRL(逆强化学习)的近似实现。传统 IRL 先反推 reward 函数再训 RL,GAIL 把这两步 联合优化 ——判别器隐式地学到了 reward,策略通过 RL 直接优化。
PART 03
GAIL vs BC vs DAgger 对比
BC | DAgger | GAIL | |
|---|---|---|---|
在线交互 | ❌ | ✅ 必需 | ✅ 必需(但通过RL) |
需要专家标注 | ❌ | ✅ 必需 | ❌ 不需要 |
训练稳定性 | ✅ 好 | ⚠️ 中 | ❌ 不稳定(GAN问题) |
泛化能力 | ❌ 差 | ✅ 好 | ✅ 好 |
计算成本 | 低 | 中 | 高 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号