CVPR 2026 | 字节等提出图像修复新范式:HiFi-Inpaint

CVPR 2026 | 字节等提出图像修复新范式:HiFi-Inpaint

Amusi
发布于 2026-06-08 13:40:47
发布于 2026-06-08 13:40:47
论文标题:HiFi-Inpaint: Towards High-Fidelity Reference-Based Inpainting for Generating Detail-Preserving Human-Product Images
论文地址:https://arxiv.org/abs/2603.02210 代码地址:https://correr-zhou.github.io/HiFi-Inpaint

创新点
- 针对人类-产品图像生成场景,提出了一种高保真度的参考引导式修复(Reference-Based Inpainting)框架,核心目标是精准保留产品细节。
- 引入高频图(high-frequency maps)进行像素级监督, enforce 精确的细节保持,相比传统 coarse supervision 更加细粒度、更有针对性。
方法
本文的主要研究方法是显式地将高频特征注入网络结构和损失函数中,以解决扩散模型去噪过程中细节"平均化"和隐空间监督粗糙的问题。模型首先通过频域高通滤波从参考商品图中提取高频图(包含文字边缘、Logo、精细纹理等关键细节),然后在双流视觉DiT块中设计了共享增强注意力模块(SEA),将商品Token替换为高频图Token,并通过可学习的权重因子将高频特征自适应地注入Mask区域,相比固定权重能避免特征冲突和视觉伪影。
HiFi-Inpaint 论文方法架构图详解图
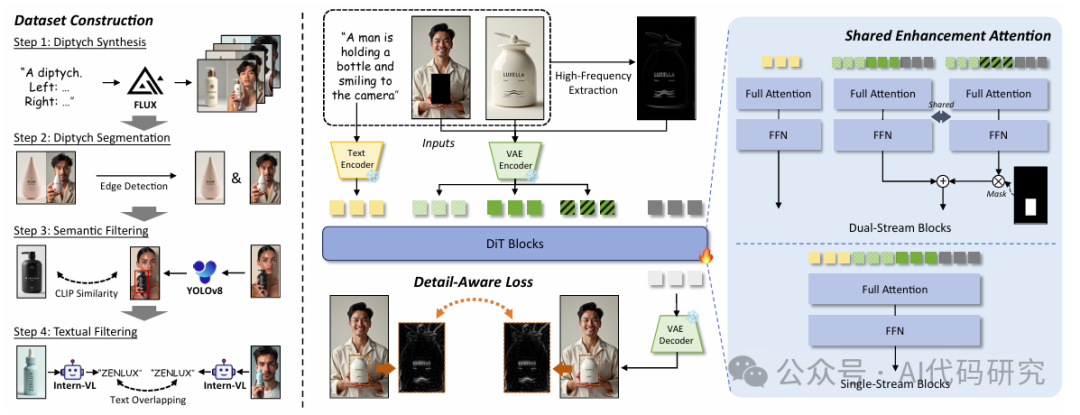
本图展示了 HiFi-Inpaint 框架的整体架构,涵盖了从数据集构建到模型推理及训练的全流程。左侧的数据集构建部分(Dataset Construction)通过四个步骤实现了高质量训练数据的自动生成与清洗:首先利用 FLUX 模型根据文本提示生成“人-产品”双联图(Diptych Synthesis),接着通过边缘检测将产品与人物分割(Diptych Segmentation),随后利用 CLIP 相似度和 YOLOv8 进行语义过滤以确保主体一致性(Semantic Filtering),最后通过 Intern-VL 进行文本重叠检测以剔除文字错误的样本(Textual Filtering),最终构建出包含 4 万张高质量样本的 HP-Image-40K 数据集。中间的主体部分展示了模型的推理与训练机制:输入包括文本提示、包含人物的图像以及参考产品图,其中参考图经过高频提取(High-Frequency Extraction)获得包含细节的高频图,随后文本和图像特征分别通过 Text Encoder 和 VAE Encoder 编码,并在 DiT Blocks 中融合,其中双流块(Dual-Stream Blocks)利用共享增强注意力(Shared Enhancement Attention)机制将高频特征注入掩码区域,而单流块(Single-Stream Blocks)则处理未掩码区域,最终通过 VAE Decoder 生成修复后的图像。
HiFi-Inpaint与现有主流方法的定性对比结果图

本图展示了HiFi-Inpaint(Ours)与ACE++、Insert Anything、FLUX-Kontext等现有主流参考引导修复方法在“人-产品”图像生成任务上的定性对比结果。每一组对比均包含左侧的参考产品图(Ref.)、底部的原始输入图(Input),以及四种方法生成的修复图像,并附带了产品细节的放大图。实验结果表明,HiFi-Inpaint在保持产品细节的高保真度方面表现最为出色,能够精准地还原产品上的微小文字(如“LYNAH GLOW”、“NOVA DEW”)、复杂的Logo图案以及瓶身的纹理质感;相比之下,其他对比方法在生成过程中普遍出现了文字扭曲、模糊、缺失或Logo变形等细节丢失问题,验证了本文提出的方法在生成细节保留型人像产品图像方面的优越性。
HiFi-Inpaint消融实验定性对比图

本图展示了HiFi-Inpaint模型的消融实验结果,旨在验证核心组件Shared Enhancement Attention (SEA)和Detail-Aware Loss (DAL)的有效性。实验对比了完整模型(HiFi-Inpaint (Ours))与去除SEA模块(w/o SEA)以及同时去除SEA和DAL(w/o SEA & DAL)的变体在多个不同产品上的生成表现。结果显示,完整模型生成的产品图像在文字清晰度、Logo还原度以及瓶身纹理细节上均显著优于消融模型;特别是当去除DAL损失函数后,生成的产品文字变得模糊且难以辨认,这有力地证明了SEA模块对于特征融合的重要性,以及DAL损失函数对于指导模型精确还原高频细节(如微小文字和纹理)的关键作用。
实验

该表格展示了HiFi-Inpaint与Paint-by-Example、ACE++、Insert Anything及FLUX-Kontext等主流方法在“人-产品”图像生成任务上的定量对比结果,评估指标涵盖文本对齐(Text Alignment)、视觉一致性(Visual Consistency)和生成质量(Generation Quality)三个维度。数据表明,HiFi-Inpaint在视觉一致性方面表现最为突出,其CLIP-I(95.0%)、DINO(91.9%)和SSIM(63.4%)得分均显著优于其他对比方法,证明了其在保持产品外观与参考图高度一致方面的优越性;同时,该方法在高频结构相似性(SSIM-HF)上取得了42.9%的最高分,验证了其对产品微小文字和纹理等细节的精准保留能力,尽管在部分生成质量指标上略逊于FLUX-Kontext,但整体综合表现依然处于领先地位。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号