深入解读多智能体(Multi-Agent)系统失败的根源

深入解读多智能体(Multi-Agent)系统失败的根源

唐国梁Tommy
发布于 2026-06-25 20:34:12
发布于 2026-06-25 20:34:12
今天,我们要一起深入探讨一个在AI圈子里越来越火的话题——多智能体系统(Multi-Agent Systems,简称MAS)。
你可能已经听说过这些“AI梦之队”了:让一个AI扮演产品经理,一个扮演程序员,另一个扮演测试工程师,它们三个“人”凑一桌,就能自动开发软件。像MetaGPT、ChatDev这样的项目,正在让这个科幻场景变为现实。
然而,理想很丰满,现实却有点骨感。如果你亲自尝试过这些系统,或者关注过它们的评测,你可能会发现一个尴尬的事实:它们常常失败。而且失败率高得惊人。来自加州大学伯克利分校的一篇最新研究论文《Why Do Multi-Agent LLM Systems Fail?》就用一张图(Figure 1)毫不留情地揭示了真相:在某些任务上,像ChatDev这样的系统,成功率只有33.3%,而HyperAgent更是低至25.3%。
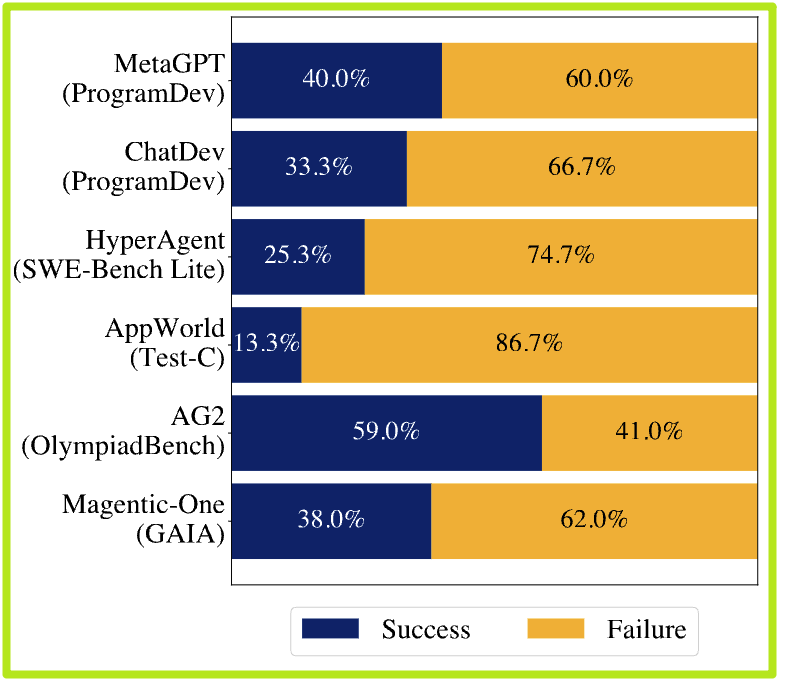
这就引出了一个灵魂拷问:为什么这些看起来聪明的AI智能体,组队之后反而变得“不靠谱”了? 它们究竟在哪个环节掉了链子?是单个AI不够聪明,还是团队协作出了问题?
今天,我们就来一起剖析这篇来自伯克利AI研究实验室(BAIR)的重磅论文。它没有发布又一个狂拽酷炫的新模型,而是像一位经验丰富的“组织行为学家”,对这些AI团队进行了系统性的“病理分析”,并给出了一份堪称“AI团队失败诊断手册”的宝贵成果。
一、问题核心:从“代码能跑”到“团队能赢”的鸿沟
在深入论文之前,我们先明确一下问题的背景和重要性。
多智能体系统(MAS)的初衷,是模仿人类社会的高效协作模式。我们知道,解决一个复杂问题,比如开发一款软件、策划一场市场活动,单靠一个人是很难完成的。我们需要不同角色、不同专长的人组成团队,通过分工、沟通、协作来完成。MAS的核心思想就是,让不同的LLM智能体(Agent)扮演这些角色,通过“对话”和“工具使用”来共同解决问题。
这种模式的理论优势非常明显:
1. 任务分解:将一个大问题拆解成多个小任务,分给专门的智能体,降低复杂度。
2. 专业化:每个智能体可以被赋予特定的角色和知识,成为某个领域的“专家”。
3. 并行处理:多个智能体可以同时工作,提高效率。
4. 多视角审视:通过不同智能体的讨论和辩论,可以发现单一智能体难以察觉的错误和盲点,提升最终结果的鲁棒性。
然而,正如前面提到的,理论上的美好撞上了现实的墙壁。这些AI团队在实际运行中,常常会陷入各种奇怪的困境:有的团队会无休止地重复同一个步骤,陷入“死循环”;有的团队成员之间仿佛有“沟通障碍”,一个成员发现了关键信息却不告诉队友;还有的团队在完成任务后,负责“质检”的AI只是草草看一眼就宣布“大功告成”,结果交付的是一堆有bug的代码。
这些问题的存在,严重阻碍了MAS从“有趣的玩具”走向“可靠的工具”。如果一个AI软件开发团队的成功率只有30%,你敢把公司的核心项目交给它吗?显然不敢。
因此,系统性地理解MAS为什么会失败,并找到问题的根源,就成了推动该领域发展的关键瓶颈。这正是这篇伯克利论文的价值所在。它试图填补“现象”与“本质”之间的空白,为我们提供一个清晰的诊断框架。
二、论文贡献:MAST分类法——AI团队的“失败病理图”
这篇论文最大的贡献,就是提出了一个名为MAST(Multi-Agent System Failure Taxonomy,多智能体系统失败分类法)的框架。你可以把它想象成一张为AI团队准备的、详尽的“失败病理图”。当一个AI团队任务失败时,我们可以用MAST来精确诊断,问题到底出在了哪里。
MAST是通过对7个主流MAS框架、超过200个任务的执行轨迹进行地毯式分析后,经验性地总结出来的。它将MAS的失败模式归纳为三大类,共14个细分项。
这三大类分别是:

1. 规范问题 - “蓝图本身就有问题”
这类失败源于系统设计和任务定义的根源性缺陷,占比高达 41.77%。这说明,很多时候AI团队失败,不是因为“员工”不行,而是因为“公司制度”和“项目需求”就不清楚。
形象类比:想象一下,你拿到一份宜家家具的组装说明书,但说明书本身就画错了、缺步骤、或者对零件的描述模棱两可。那么,无论你多聪明,都很难正确地组装起来。
具体失败模式:
- 不遵守任务规范 (10.98%):AI没有遵循用户的核心要求。比如,用户要求写一个“每天随机生成一个新单词”的Wordle游戏,结果AI给了一个固定的单词列表。
- 步骤重复 (17.14%):这是最常见的失败模式之一!AI团队在一个或多个步骤之间反复横跳,无法向前推进。这通常是因为系统的流程设计不合理,导致AI陷入了逻辑闭环。
- 不遵守角色规范 ( 0.5%):扮演“程序员”的AI突然开始做起了“产品经理”的活,导致角色混乱。
- 丢失对话历史 ( 3.33%):聊着聊着,AI突然“失忆”了,忘记了前几轮的对话内容,导致上下文断裂。
- 不清楚终止条件 ( 9.82%):任务明明已经完成了,或者已经陷入了无法解决的困境,但AI团队还在“努力”地工作,不知道该停下来。
2. 智能体间失调 - “团队协作和沟通一团糟”
这类失败发生在智能体之间的交互过程中,占比 36.94%。即使“蓝图”是完美的,但如果团队成员之间不能有效协作,项目一样会失败。
形象类比:一个施工队,图纸没问题,但瓦工不跟木工沟通,电工无视了水管工的警告,每个人都“埋头干自己的”,结果必然是一场灾难。
具体失败模式:
- 未能请求澄清 ( 11.65%):当一个智能体拿到模糊或不完整的信息时,它没有选择去问队友,而是基于错误的猜测继续工作。
- 信息隐瞒 ( 1.66%):一个智能体明明知道关键信息,却没有分享给需要它的队友。论文中的图5给出了一个绝佳的例子:一个“主管AI”让“手机AI”去登录账户,但提供的用户名
a@mail.com是错的。“手机AI”尝试登录失败后,它内部的API文档其实提示了正确的用户名格式应该是电话号码,但它并没有把这个关键信息告诉主管,只是反复说“登录失败”。结果主管AI也傻傻地继续尝试,最终任务失败。
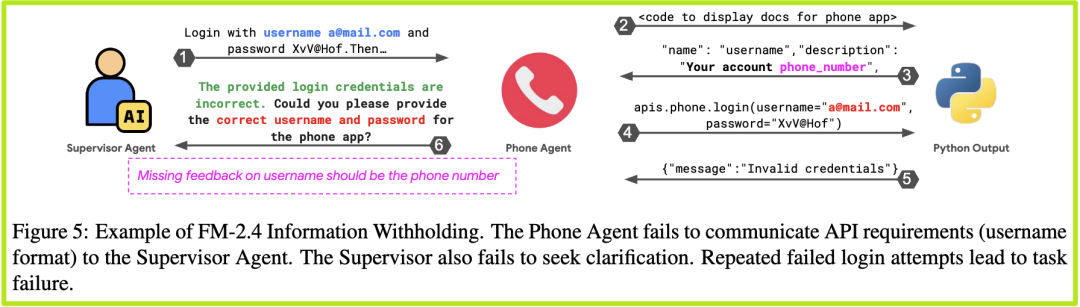
- 推理-行为不匹配 ( 13.98%):这是另一个高频失败模式。AI在自己的“内心思考”(Reasoning)中已经得出了正确的计划或结论,但在实际执行(Action)时却做了另一件事。这就像一个人心里想“我应该右转”,但手上方向盘却往左打了。
- 任务偏离 ( 7.15%):团队聊着聊着就“跑题”了,开始解决一个完全不相干的问题。
- 忽略其他智能体的输入 ( 0.17%):队友给出了明确的建议或结果,但某个AI完全无视,依然我行我素。
3. 任务验证问题 - “质检环节形同虚设”
这类失败发生在任务的最后阶段,即对产出物进行检查和验证时,占比 21.30%。这是保证最终交付质量的最后一道防线,一旦失守,前面的所有努力都可能白费。
形象类比:一个软件公司,开发团队辛辛苦苦写完代码,但QA(质量保证)团队只是检查了一下代码能不能编译通过,完全没测试核心功能是否正常,就直接打包上线了。
具体失败模式:
- 过早终止 ( 7.82%):所有必要的信息还没交换完,或者任务还没完全达成,某个AI(通常是主管角色)就提前结束了对话。
- 无或不完整的验证 ( 6.82%):负责验证的AI没有进行充分的检查。比如,在生成一个象棋游戏的代码后,验证AI只检查了代码语法,却没验证游戏规则是否正确实现(比如,是否允许非法的移动)。
- 不正确的验证 ( 6.66%):验证AI进行了检查,但得出了错误的结论。它错误地认为一个有bug的产出物是合格的。
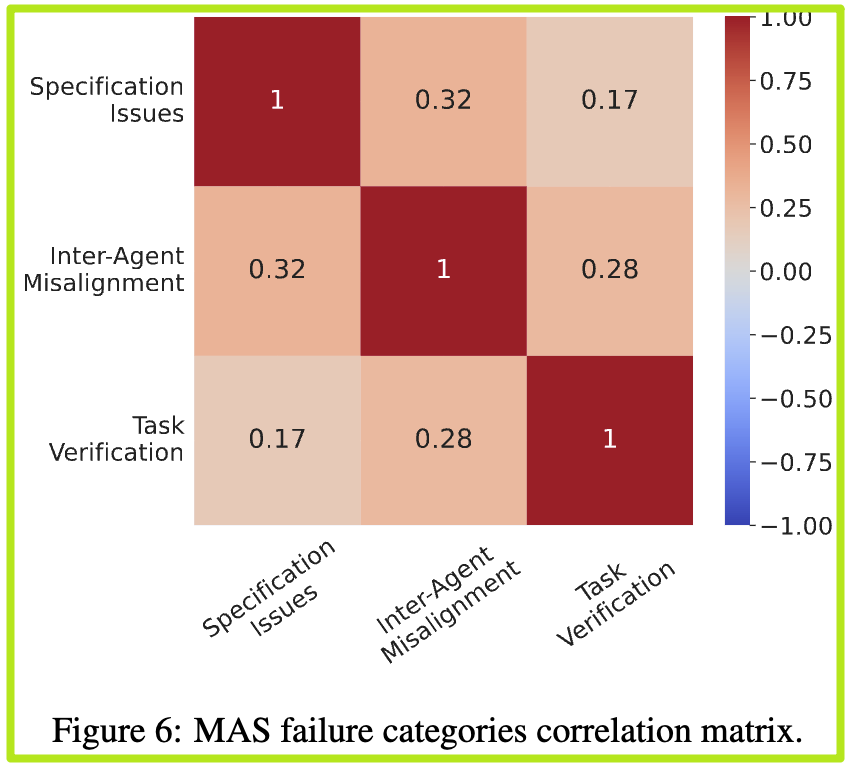
通过MAST这个框架,我们第一次能够如此清晰地看到,MAS的失败是一个复杂的、多层次的系统性问题。它远不止是“LLM遵循指令能力不行”这么简单,更多的是系统设计、协作流程和质量控制的失败。这正是这篇论文最核心的洞见。
三、研究方法:如何科学地给AI团队“看病”?
你可能会好奇,伯克利的这群研究者是如何得出MAST这个“诊断手册”的?他们的方法非常严谨,充满了科学精神,主要分为三步:
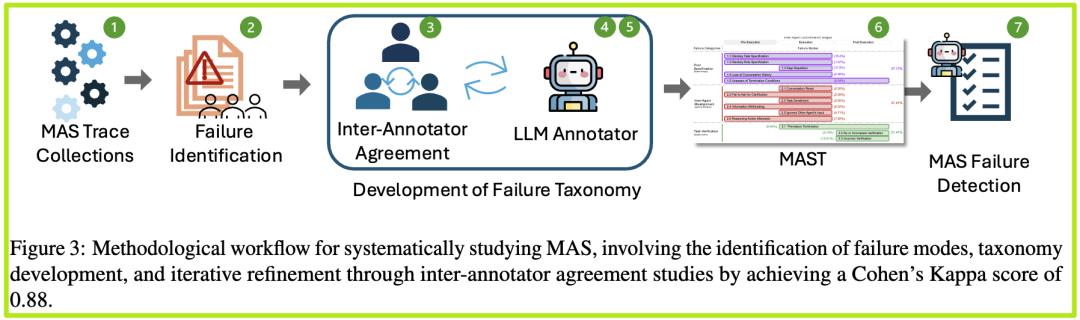
第一步:扎根理论 - 从零开始,让数据说话
这可能是整个研究中最独特的一点。研究者们没有预设任何立场或假设,而是采用了一种源自社会科学的质性研究方法——扎根理论。
- 这是什么意思? 传统的研究方法通常是“假设驱动”的(我猜失败是因为A,然后设计实验去验证)。而扎根理论是“数据驱动”的,它要求研究者像一张白纸一样,沉浸到原始数据中(在这里就是海量的MAS执行日志),不受任何偏见地去观察、标记和归纳,让理论从数据中“自然生长”出来。
- 具体操作:六位专家标注员花费了大量时间(每人超过20小时的纯标注时间),一行一行地阅读那些长达数万行的AI对话日志,识别出各种失败现象,并给它们贴上“标签”(这个过程叫“开放编码”)。然后,他们会不断地比较和讨论这些标签,将相似的合并,将复杂的拆分,直到所有人都对每个失败模式的定义达成共识,并且新的日志数据不再带来新的失败类型(这个状态叫“理论饱和”)。
第二步:跨标注员一致性 (IAA) - 确保“诊断标准”是统一且明确的
一个好的诊断手册,必须保证不同的医生用它来给同一个病人看病,能得出基本一致的结论。为了验证MAST是否达到了这个标准,研究者们进行了严格的跨标注员一致性(Inter-Annotator Agreement)测试。
- 如何测试? 他们让三位标注员使用MAST分类法,独立地去标注同一批新的失败案例。然后,使用一个叫做科恩卡帕系数 (Cohen's Kappa)的统计指标来衡量他们之间的一致性。这个系数的取值范围通常在-1到1之间,1表示完全一致,0表示和随机猜测一样。
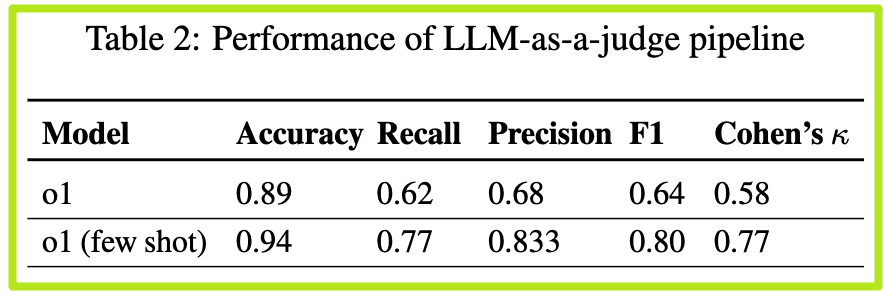
- 惊人的结果:经过几轮的迭代优化,MAST的定义变得越来越清晰。最终,在人类专家之间,MAST的科恩卡帕系数达到了惊人的 0.88!这是一个非常高的分数,在学术上被认为是“强一致性”,充分证明了MAST分类法的可靠性和无歧义性。
第三步:LLM-as-a-Judge - 训练一个AI“诊断专家”
手动分析成千上万的失败案例是不现实的。为了让MAST能够被大规模应用,研究者们训练了一个基于LLM的自动化标注工具,也就是所谓的“LLM作为评判者”。
- 如何实现? 他们给一个强大的LLM(OpenAI的
o1模型)提供了MAST中每一项失败模式的详细定义,并附上了一些典型的示例(这是一种“小样本学习”或Few-shot Learning技术)。然后,让这个LLM去自动读取MAS的执行日志,并根据MAST进行失败分类。 - 效果如何? 如论文表2所示,这个AI“诊断专家”的表现相当出色。与人类专家的标注结果相比,它的准确率高达94%,科恩卡帕系数也达到了0.77。这意味着,我们现在有了一个可以信赖的自动化工具,来大规模、高效地诊断AI团队的“病情”。
通过这三步,研究者们不仅构建了一个坚实的理论框架,还提供了一套可行的实践工具,堪称典范。
四、实验验证:MAST不仅能“看病”,还能“治病”
一个好的诊断框架,最终要能指导治疗。为了证明MAST的实用价值,论文进行了精彩的案例研究。他们选择了AG2和ChatDev这两个系统,上演了一出“诊断-干预-复查”的好戏。
核心思路:
1. 基线测试:先运行原始的MAS系统,记录成功率,并用MAST分析其失败原因的分布。
2. 干预 :针对MAST诊断出的主要问题,设计两种不同的改进方案:
- 方案A:改进提示:优化给每个智能体的角色和任务指令,让它们的职责更清晰,协作更顺畅。这相当于给团队成员做了一次“岗前培训”。
- 方案B:改进拓扑:改变智能体之间的协作流程。比如,将ChatDev原本线性的“设计-编码-测试”流程(有向无环图),改成一个可以循环的流程,允许测试人员将代码打回给程序员返工,直到满意为止。这相当于重构了公司的“工作流”。
3. 结果评估:在应用了改进方案后,重新测试系统的成功率,并再次用MAST分析失败分布,看看到底是哪些问题得到了解决。
关键实验结果:
实验结果(如论文表4所示)非常具有启发性:
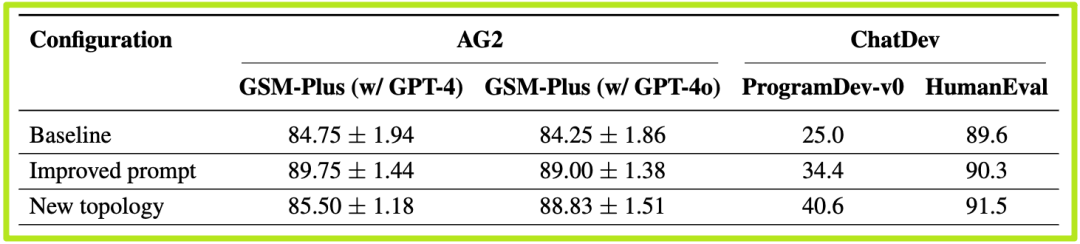
- 干预是有效的:在ChatDev的软件生成任务(ProgramDev-v0)上,基线系统的成功率只有惨淡的25.0%。经过“改进提示”后,成功率提升到了34.4%。而当采用更根本的“改进拓扑”方案后,成功率飙升到了40.6%,绝对提升了15.6%!
- 系统设计比微调提示更重要:这个结果有力地证明了论文的核心论点。虽然优化提示词有一定帮助,但改变系统架构和协作流程,带来的性能提升是更显著的。这告诉我们,构建强大的MAS,重点不应仅仅放在“提示工程”上,更要放在“系统工程”上。
- MAST提供了深入的洞察:通过对比干预前后的MAST失败分布图(论文图9),我们可以清晰地看到,改进拓扑结构后,几乎所有类型的失败(包括规范问题、协作问题和验证问题)都得到了显著的缓解。MAST让我们不仅知道“成功率提升了”,更知道“为什么提升了”,为后续的优化指明了方向。
这些实验无可辩驳地证明,MAST不仅是一个理论框架,更是一个强大的、可以指导实践的开发和调试工具。
五、AI团队的进化之路
这篇论文为我们揭示了多智能体系统失败的深层原因,也为未来的发展指明了方向。它带给我们的启示是深刻的:
1. 从“模型为王”到“设计为王”:我们必须转变思路,认识到构建成功的MAS,优秀的系统设计、清晰的协作协议和强大的验证机制,与强大的底层LLM模型同等重要,甚至更为关键。未来的研究需要更多地借鉴软件工程、组织行为学等领域的知识。
2. 自动化诊断与自愈:既然我们有了MAST和LLM-as-a-Judge这样的自动化诊断工具,那么未来的MAS或许可以具备“自我诊断”和“自我修复”的能力。想象一个AI团队,它在运行中可以实时监测自身的协作健康度,一旦发现某种失败模式(比如“信息隐瞒”)的频率上升,就能自动调整沟通策略,从“自由讨论”切换到“强制信息同步”模式。
3. 超越“正确性”的考量:论文坦言,其研究主要聚焦于任务是否能正确完成。但在现实世界中,效率、成本和安全同样至关重要。一个能花10个小时和100美元完成任务的AI团队,远不如一个能花10分钟和1美元完成同样任务的团队有价值。未来的研究需要将这些维度也纳入考量,构建一个更全面的MAS评估和优化体系。
总而言之,这篇来自伯克利的论文,就像一位冷静而睿智的医生,为当前火热但混乱的MAS领域进行了一次彻底的“体检”。它提出的MAST分类法,为所有MAS的开发者和研究者提供了一面宝贵的镜子,让我们能看清自己系统的弱点,并朝着构建更健壮、更可靠、更高效的AI团队迈出坚实的一步。
参考文献
论文名称: Why Do Multi-Agent LLM Systems Fail? Learning for LLMs
第一作者: 加州大学伯克利分校
论文链接: https://arxiv.org/abs/2503.13657v2
发表日期: 2025年4月22日
GitHub:https://github.com/multi-agent-systems-failure-taxonomy/MAST.git
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#多智能体 #AIAgent #LLM #AI大模型 #唐国梁Tommy #AIGC #智能体Agent #AI前沿技术
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号