AI Agent 离“替你打工”还有多远?它只做完了 20.6%

AI Agent 离“替你打工”还有多远?它只做完了 20.6%

唐国梁Tommy
发布于 2026-07-01 18:21:41
发布于 2026-07-01 18:21:41
我们已经习惯了这样的宣传:AI Agent 能浏览网页、操作软件、写代码跑程序,像一个数字员工一样替你干活。可一旦把任务从"帮我订张票"换成"帮我走完一整套报销流程",故事就完全变了。

论文链接:https://arxiv.org/pdf/2606.29537
来自 XLANG Lab 的新基准 OSWorld 2.0,把电脑使用测评第一次推到了"专业级真实工作流"的难度。结论很扎心:
在最严格的"全任务完成"指标下,目前最强的
Claude Opus 4.8(开满思考、批量调用工具)也只能完整做完 20.6% 的任务。

更值得玩味的是它们栽倒的方式——不是不会点按钮、不会写代码,而是丢了约束、漏了中途信息、该问的时候只顾着猜。
老基准的问题:任务太短,太干净
过去几年,电脑使用 Agent 的进步几乎都是在"短任务"上刷出来的。以上一代 OSWorld 1.0 为例,一个任务人类做完的中位时间大约只有两分钟,Agent 平均走 30 步就能交活,而且基本只在一个应用里打转。
问题在于,真实工作根本不长这样。真实工作流是长程的、跨应用的、信息会中途变化的、还经常缺一块你必须自己找回来的隐藏状态。旧基准测不出这些,于是也就照不出前沿模型真正的短板。

OSWorld 2.0:把"一下午的活"搬进测评
OSWorld 2.0 收录了 108 个长程电脑使用工作流,覆盖日常与专业场景。它的尺度和上一代完全不是一个量级:
- 一个任务,熟练人类完成的中位时间约 1.6 小时,是
OSWorld 1.0的约 48 倍;近 七成任务需要熟练用户花一个多小时。 - Agent 这边同样被拉长——用
Claude Opus 4.7开满思考时,平均要 318 次工具调用(旧版约 30 次),最强设置下单个任务超过 250 步。 - 任务是跨应用的,平均牵涉 2.44 个应用或服务,需要在邮箱、银行、团队聊天、报销门户之间反复横跳。
更关键的是,这些任务不是凭空编的。它们建立在真实的输入材料(PDF 教程、嘈杂的收据、历史报告)之上,还交叉绑定了一套有状态的用户档案数据,并附带独立的安全审计报告。

举个论文里的代表任务:替你提交一笔 ExpenseFlow 报销。Agent 得先读懂一份 PDF 教程,操作一个老旧的报销门户,从嘈杂的收据里抠出正确金额,跨 GMail 和 ChaseBank 追溯订单证据;执行到一半,一封新邮件改变了任务状态,它还得从一份旧报告里找回被隐藏的员工信息,跨多个应用收集证明,发现一处自己解决不了的矛盾、主动向用户求证,最后才是复核与提交。

真实工作的十种"暗礁"
OSWorld 2.0 最有价值的设计,是把真实工作流里反复出现、却被旧基准忽略的难点,提炼成 10 类挑战现象,并给全部 108 个任务打上标签。这十类暗礁,几乎每一条都精准命中当下 Agent 的认知盲区:
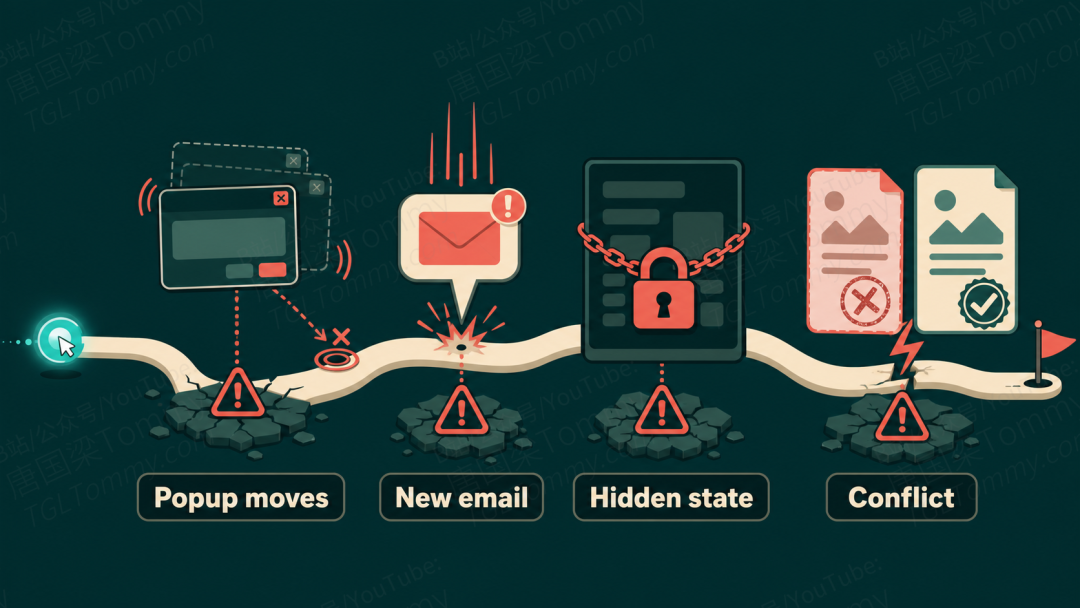
- 流式交互:Agent 用离散截图看屏幕,可环境在"看一眼"和"动手"之间一直在变。一个不断飘动的促销弹窗,会让它算好的点击坐标永远差那么一点,关都关不掉。
- 动态环境:执行途中,团队频道或邮件里突然来了新消息,改写了需求。死守初始计划、不盯着频道看的 Agent,每一步都对、最终的表单却是错的。
- 教程跟随:要边看 PDF/视频教程边操作。其中视频教程最难——多模态模型只能抽关键帧,丢掉了时序,于是"画面里有什么"看得懂,"它是怎么动的"却复现不出来。
- 主动交互:当信息不全或有错时,该停下来问用户,而不是硬着头皮猜。比如发现财力证明只有 12000 美元、项目却要 18000,正确做法是停下、说明缺口、请用户补材料。
- 跨源推理:把银行流水、邮件回执、政策文件对上账,而不是从单一页面照抄。
- 隐状态推断:有些信息既没写在指令里,也不在任何显眼的单一来源里,Agent 必须推断它"应该藏在哪"——某张历史表单、某个数据库、某条运行日志。

剩下几类同样硬核:视觉空间精度(像素级的定位、几何与对齐)、多模态编辑(图像、视频、3D CAD 乃至医学图像分割,考的是真看懂而非会用软件)、多项状态跟踪(一批报销行、日历项、采购单要全程保持一致)、冲突消歧(来源可能陈旧、矛盾甚至是故意的干扰项,得判断谁才权威)。
它们到底栽在哪里?
这份报告最反直觉的发现是:前沿 Agent 的瓶颈不在底层操作,而在高层认知。

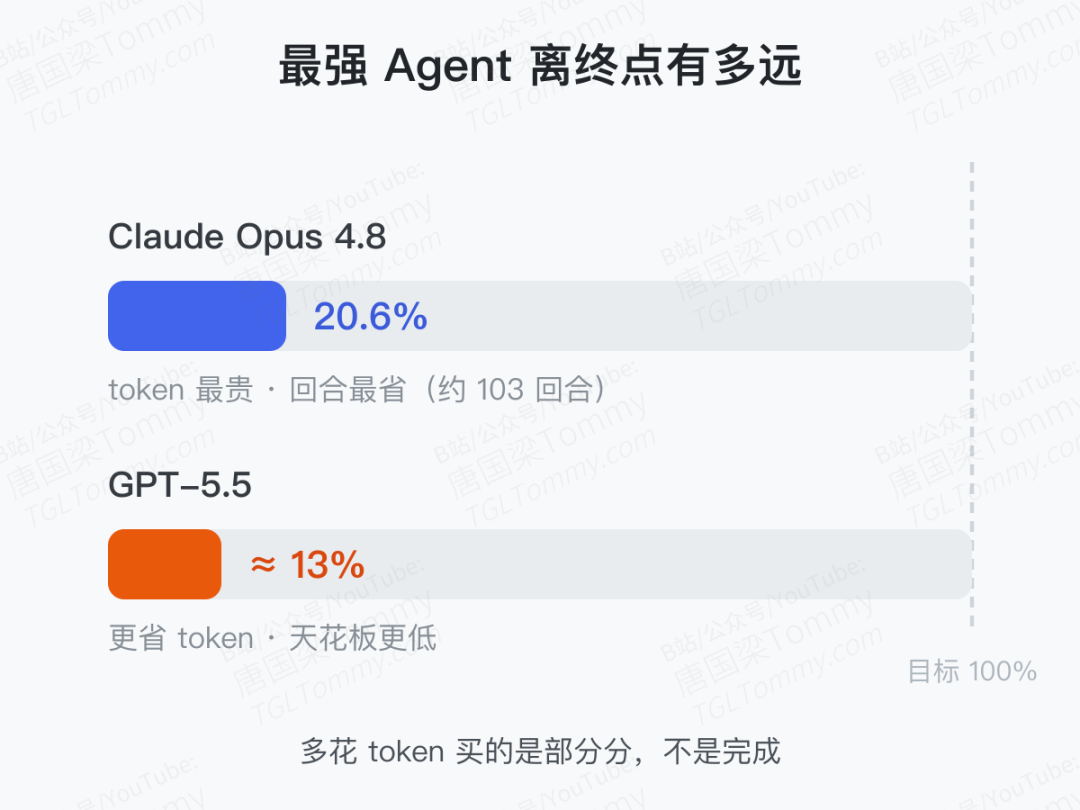
先看一个核心权衡。Claude Opus 4.8 拿到全场最高的 20.6%,靠的不是多走几步,而是批量调用——它 token 花得最多,回合数却最省,约 103 个回合就够了。GPT-5.5 则相反,省 token 但天花板更低,停在约 13%。论文给出一个清醒的判断:在交互式部署里,真正的成本是回合数(每个回合都增加延迟、也给界面一次"在你脚下变形"的机会),而回合空间的上限是由批量调用决定的,不是靠多迈几步。
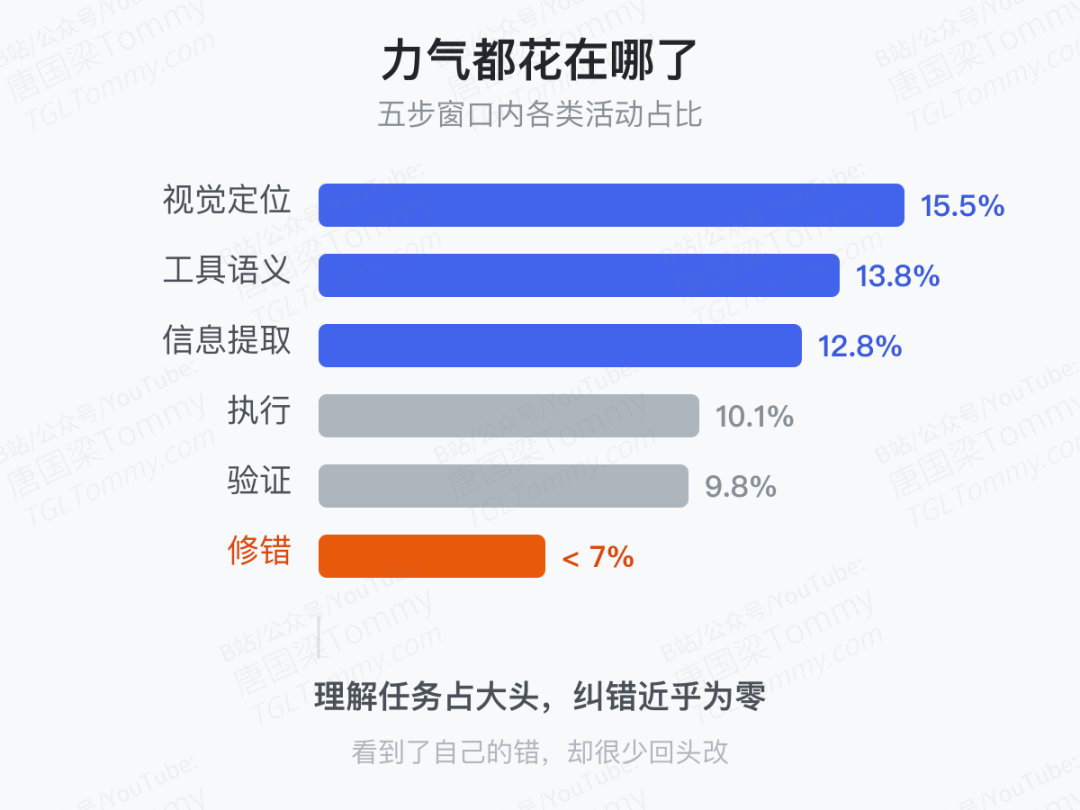
再看 Agent 把"力气"花在了哪。论文按五步一窗统计行为,结果是:预算几乎全砸在"理解任务"上——视觉定位 15.5%、工具语义推理 13.8%、信息提取 12.8%,全部高过真正的执行(10.1%)和验证(9.8%)。动作层面,GUI 点击、终端命令、热键、等待加起来占了 80%,大量是低杠杆的空转。
而最该有的能力却几乎为零:它们几乎不花预算去发现并修正自己的错误。 恢复加修复的开销在所有模型上都低于 7%,重复打转、目标漂移更是基本不超过 2%。换句话说,Agent 看到了自己犯的错,却很少回头改。
把这些拼起来,失败画像就清晰了:Agent 会漏掉来自指令、环境或用户通道的信息;在时间敏感的任务上,因为"看到"和"动手"间隔太长,动作打在了过期的界面上;难以解读和生成领域专有的文件;提交前不验证关键属性,连已经注意到的错误也不改;还会因为只把状态压缩在思维链里,忘掉早期收集的信息。而 GPT-5.5 和 Claude Opus 4.7 各有各的崩法,能力画像几乎相反。

这份基准的意义
OSWorld 2.0 真正的贡献,不是又给出一个排行榜,而是把"离专业级还差多远"翻译成了可诊断的具体短板。
它告诉我们:当下 Agent 的差距,不在它会不会用电脑,而在它会不会像一个靠谱的人那样工作——记得住约束、追得上变化、拿不准时会开口问、交活前会复核。这些恰恰是把 Agent 从"演示里的惊艳"推向"工作中的可靠"必须补上的一课。
真正的鸿沟,不是基础的 GUI 控制或编程,而是当任务取决于一块必须自己找回的隐藏状态时,Agent 最容易彻底迷失。
当然,这份基准也有它的边界:108 个任务虽难却仍是抽样,模型评判与用户模拟引入了新的不确定性,安全审计也只是起步。但它指出的方向足够清楚——下一代 Agent 要赢的,不再是操作,而是认知与协作。
下次再看到"AI 替你搞定一切"的演示时,或许可以多问一句:它能稳稳地做完那一下午的活吗?
进阶学习
如果你正在关注大模型 Agent、强化学习后训练、RLHF、DPO、GRPO、RLVR 等前沿方向,欢迎学习我最新上线的精品课程:
课程围绕 Agent 架构、强化学习基础、Reward 设计、策略优化、工具调用、多轮任务执行、Agentic Workflow 以及前沿论文与实战案例展开,帮助你建立从理论到应用的完整知识体系。
Agent RL 正在成为大模型能力提升与智能体系统演进中的重要方向。未来的 Agent 不只是会调用工具,而是要能规划任务、评估结果、修正策略,并在复杂环境中持续优化自己的行为。
现在系统学习 Agent RL,提前进入下一阶段 AI 应用开发的核心赛道。
🌟 关注“唐国梁TGLTommy”,一起持续追踪 AI 技术演进背后的长期趋势。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号